本文主要是介绍论文阅读:Feature Refinement to Improve High Resolution Image Inpainting,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目地址:https://github.com/geomagical/lama-with-refiner
论文地址:https://arxiv.org/abs/2109.07161
发表时间:2022年6月29日
项目体验地址:https://colab.research.google.com/github/advimman/lama/blob/master/colab/LaMa_inpainting.ipynb#scrollTo=-VZWySTMeGDM

解决了在高分辨率下工作的神经网络的非绘制质量的下降问题。inpainting网络往往无法在分辨率高于其训练集的情况下生成全局相干结构。这部分归因于接受域,尽管图像分辨率保持静态。虽然在绘制之前缩小图像会产生相干的结构,但它本质上缺乏更高分辨率的细节。为了充分利用这两个世界,我们通过最小化推理时的多尺度一致性损失来优化网络的中间特征图。这种运行时优化改进了的绘制结果,并建立了一种新的高分辨率的绘制状态。
本文主要是提出一种图像修复效果不断精细化的方法(与模型结构无关),其前置条件时低分辨率修复效果比高分辨效果好,然后基于低分辨率的预测中的可靠部分对模型在推理时进行训练,从而提升高分辨率的预测结果。本文提出的方法与personal-sam存在一定类似,即在运行时进行模型参数的迭代更新
1. Introduction
Image inpainting是填充图像[19]中缺失的像素或区域的任务。该任务可应用于图像恢复、图像编辑、增强现实和减弱现实[12] [4]。人们已经提出了几种方法来解决这个问题。[6,17]使用梯度引导的来自相邻像素的颜色扩散来绘制缺失区域。[5,7]是来自满足定义明确的相似性标准的图像的未掩蔽区域的样本补丁。基于patch的解决方案被广泛应用于图像编辑工具,如Gimp [2]和ps[1]是填充图像[19]中缺失的像素或区域的任务。该任务可应用于图像恢复、图像编辑、增强现实和减弱现实[12] [4]。人们已经提出了几种方法来解决这个问题。[6,17]使用梯度引导的来自相邻像素的颜色扩散来绘制缺失区域。[5,7]是来自满足定义明确的相似性标准的图像的未掩蔽区域的样本补丁。基于补丁的解决方案被广泛应用于图像编辑工具,如Gimp [2]和ps[1]。
当掩蔽区域足够大,足以包含多个纹理或语义区域[20,23]时,现有的方法常常难以实现全局一致性。条件生成对抗网络(cGAN)已经被开发出来,通过一个中间的全局表示[11,14,19,20,25]来解决这个问题。即使使用cGAN,一个大的接受域对于高性能Image inpainting[16]也至关重要。人们提出了各种技术来增加有效的接受域,如傅里叶卷积[16],扩散模型[15],contextual transformations[21],和transformers[8,10]。
在这项工作中,我们专注于提高现有网络在高分辨率下的inpainting质量。在绘制一个区域时,按比例增加操作图像的大小会减少网络的可用局部上下文,从而导致非相干的结构和模糊的纹理[21]。为了解决这个问题,我们提出了一种新的从粗到细的迭代细化方法,它通过多尺度损失来优化特征图。通过使用低分辨率的预测作为指导,细化过程产生详细的高分辨率的未绘制结果,同时保持来自低分辨率预测的颜色和结构(图1)。不需要对入侵绘制网络进行额外的训练;在推理[13,18]期间,只有特征图被细化。

2. Multiscale Feature Refinement
我们的多尺度特征细化遵循一种从粗到细的方法来迭代地添加更多的预测细节,具体如图二所示。
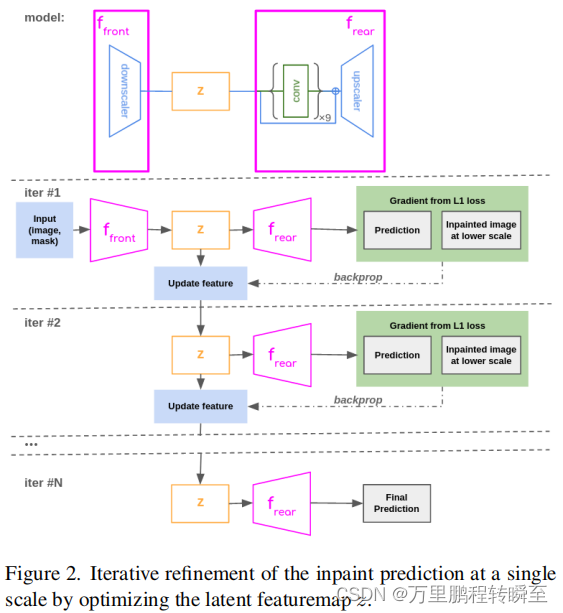
构造了输入RGB图像和绘制掩模的图像金字塔,作为多推理分辨率的网络输入。最小的尺度近似等于网络的训练分辨率。我们假设该网络在训练分辨率方面表现最好,并将其作为所有的inpainting结构指导的基础。
该模型被分为“front”和“rear”部分,类似于论文[18]。通常,这些部分分别对应于网络的编码器部分和解码器部分。在最低分辨率下,我们对整个绘制模型进行一次向前传递,以获得初始绘制预测。对于每个后续尺度,我们运行一个通过“front”来生成一个初始特征图z。多个特征图(例如,从跳跃连接)可以联合优化,但本文没有进行研究。
网络的后部处理z以产生一个inpainting预测。然后缩小预测范围,以匹配前一个尺度结果的分辨率。降尺度包括应用高斯滤波器,然后进行双线性插值。高斯滤波器去除高频分量,并防止在降级期间出现混叠。在掩蔽的内绘制区域之间计算一个L1损失,并通过反向传播更新z来最小化。这将优化z,以产生一个更高分辨率的预测,具有与以前的尺度相似的特征。
图3显示了一个细化如何提高预测质量的示例。高分辨率(1024px),与Big-LaMa [16]相比,本文方法在结构完成度方面有了显著的改进。与升级的低分辨率预测(512px)相比,我们的改进还包含了更多的细节。

算法1中描述了用于多尺度细化的Python伪代码。multiscale_inpaint函数生成图像金字塔并在多个尺度上迭代,而预测_和_细化生成每个尺度的细化预测。
def predict_and_refine(image, mask, inpainted_low_res,
model, lr=0.001, n_iters=15):z = model.front.forward(image, mask)# configure optimizer to update the featuremapoptimizer = Adam([z], lr)for _ in range(n_iters):optimizer.zero_grad()inpainted = model.rear.forward(z)inpainted_downscaled = downscale(inpainted)loss = l1_over_masked_region(inpainted_downscaled, inpainted_low_res, mask)loss.backward()optimizer.step() # Updates z# final forward passinpainted = f_rear.forward(z)return inpainteddef multiscale_inpaint(image, mask, model, smallest_scale=512):images, masks = build_pyramid(image, mask, smallest_scale)n_scales = len(images)# initialize with the lowest scale inpaintinginpainted = model.forward(images[0], masks[0])for i in range(1, n_scales):image, mask = images[i], masks[i]inpainted_low_res = inpaintedinpainted = predict_and_refine(image, mask, inpainted_low_res, model)return inpainted
3. Experiments
在我们的实验中,我们应用迭代多尺度细化到Big-LaMa[16]。用2的降比例因子来建立图像金字塔。从大lama降尺度部分的部分(见图2)的输出特性图将进行优化。该特征图的选择是基于观察到离预测层更远的特征图有更大的接受域,并且能够影响更多的输出[18]。
在每个尺度上,我们使用Adam优化器执行15次细化迭代,学习率为0.002。为了防止网络在网络已经表现良好的薄区域对低分辨率填充进行优化,我们在对已绘制区域应用L1损失之前,用15像素的圆形核侵蚀mask。
4. Results
图像修复网络通常在Places2[24]上作为基准。然而,该数据集并没有用于评估目的的高分辨率图像。相反,我们将使用来自 Unsplash-Lite数据集的图像,其中包含2.5k张高分辨率的自然主题照片[3]。我们随机抽取了1000张图片来进行评估(链接到[这里])。
每个图像都被调整大小并裁剪到1024x1024,并使用[16]中描述的方法,用薄、中、厚的笔触生成一组掩模。这些不同的掩模类型分别进行评估,以观察掩模宽度对图像inpainting质量的影响。根据最近的工作[8,16],使用FID评分[9]和LPIPS [22]来评估性能。
我们与表1和图4、5中的其他方法进行了比较。我们的方法在中和厚掩模方面的性能优于报道的最先进的绘制网络,而在薄掩模上的性能与Big-LaMa [16]类似。薄掩模的性能是相似的,因为有足够的周围上下文来完成结构。
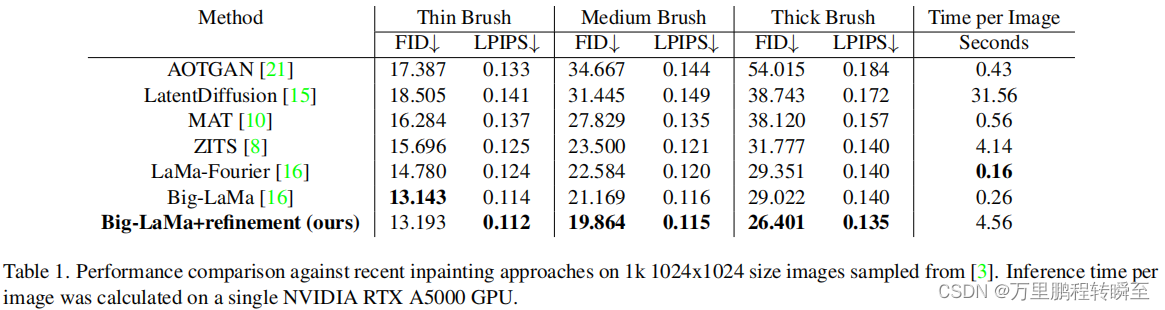


虽然我们的细化产生了更高的评分结果,但处理图像也需要花费更长的时间。对于每个图像,需要多次正向和反向传递。这与尺度和优化步骤的数量成比例地增加了推理时间。细化还增加了内存的使用,因为在运行时需要梯度,从而降低了GPU内存的最大分辨率。我们的方法产生了填充与更强的全局一致性和更清晰的纹理。其他的结果可以通过这个链接的视频获得。
5. Conclusion
我们提出了一种多尺度细化技术来提高神经网络在分辨率高于原生训练分辨率的图像上的嵌入性能。这种细化是网络不可知的,不需要额外的模型再训练。我们的结果表明,该技术在高分辨率的inpainting上显著优于其他最先进的方法。
这篇关于论文阅读:Feature Refinement to Improve High Resolution Image Inpainting的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)