本文主要是介绍杨中科 EFCore 第二部分 实体配置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
实体的配置
约定配置
主要规则:
1:表名采用DbContext中的对应的DbSet的属性名。
2:数据表列的名字采用实体类属性的名字,列的数据类型采用和实体类属性类型最兼容的类型。
3:数据表列的可空性取决于对应实体类属性的可空性。
4:名字为Id的属性为主键,如果主键为short,int 或者long类型,则默认采用自增字段,如果主键为Guid类型则默认采用默认的Guid生成机制生成主键值。
两种配置方式
l、Data Annotation把配置以特性 (Annotation)的形式标注在实体类中。
[Table(“T_Books”)]
public class Book
优点:简单;缺点:耦合。
2、Fluent API 【推荐】
builder.ToTable(“T_Books”);
把配置写到单独的配置类中。
缺点:复杂;优点:解耦
3、大部分功能重叠。可以混用,但是不建议混用
示例:
1.新建 Cat 类
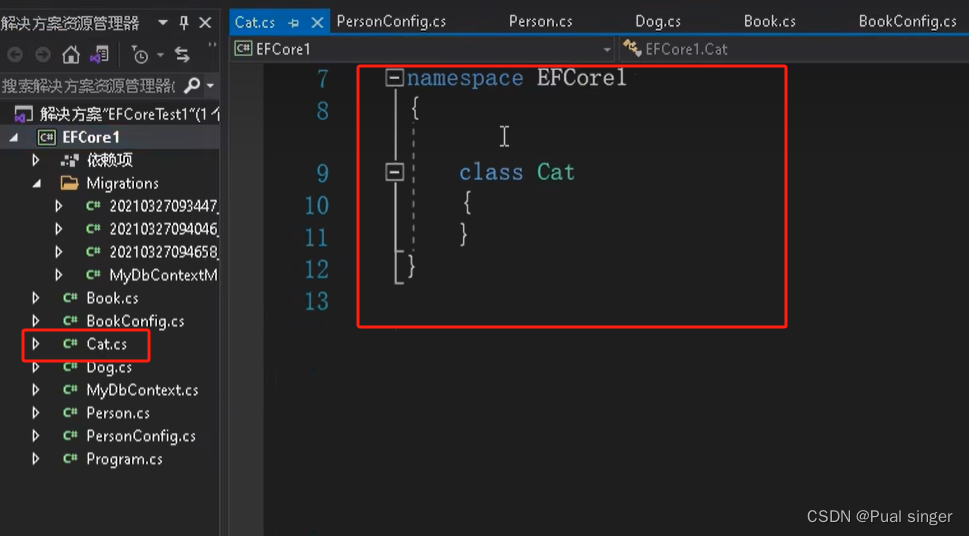
2.将类信息加到 Dbcontext 中
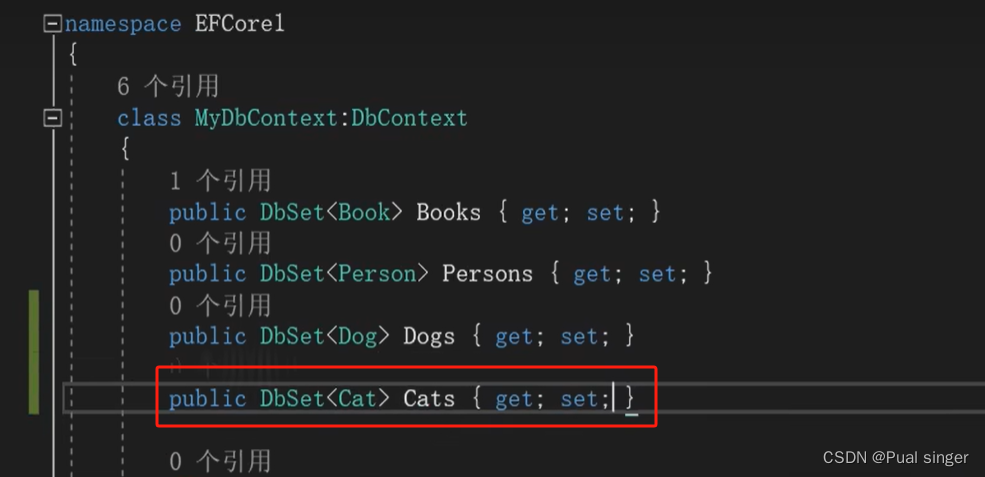
3.添加特性
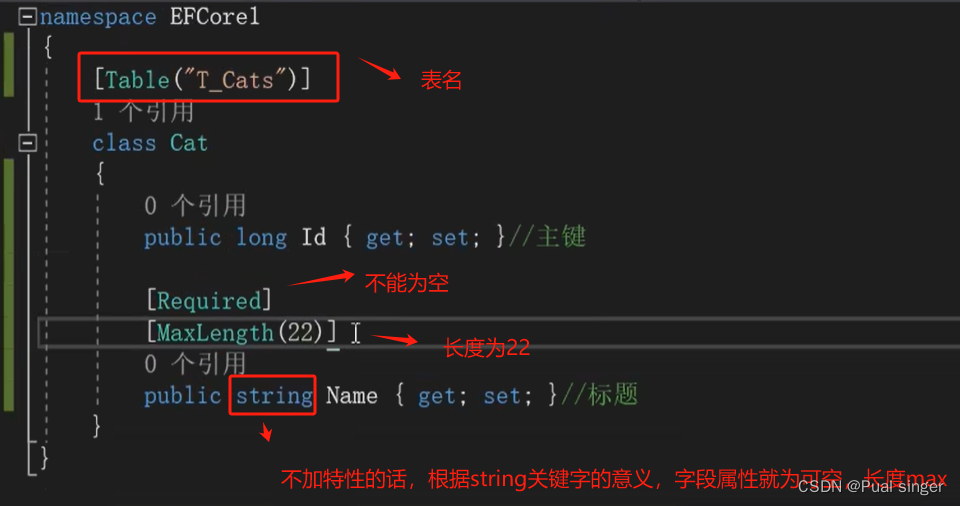
执行编译和运行命令:
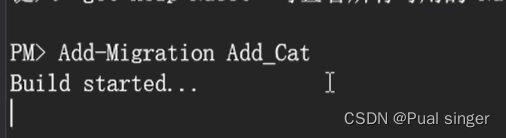
表 生成成功
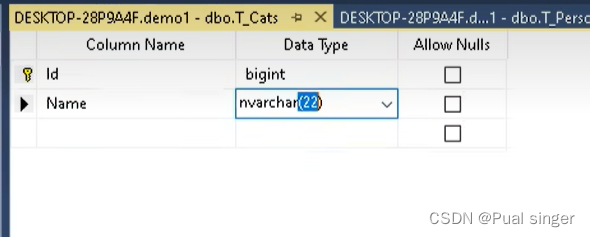
使用Fluent API 的好处是可以根据实际情况,修改代码结构 ,生成不同类型表名,字段等。 可定制化性 提高
Fluent API 1
只过一遍,不演示
1、视图与实体类映射:
modelBuilder.Entity(.ToView(“blogsView”);
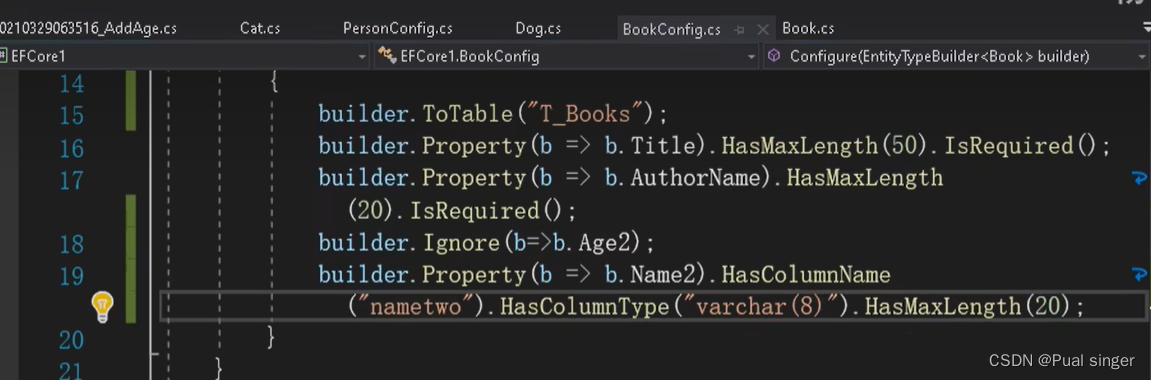
2、排除属性映射:(让某个属性,不映射到表中)
modelBuilder.Entity().lgnore(b => b. Name2);
3、配置列名:(将某个字段改为自己想要的名字)
modelBuilder.Entity().Property(b=>b.BlogId).HasColumnName(“blog_id”);
4、配置列数据类型:
builder.Property(e => e.Title) .HasColumnType(“varchar(200)”)
5、配置主键
默认把名字为Id或者“实体类型+Id“的属性作为主键,可以用HasKey()来配置其他属性作不演示映射: modelBuilder.Entity().HasKey(c=>c.Number);
支持复合主键,但是不建议使用
增加 Name2字段

执行:
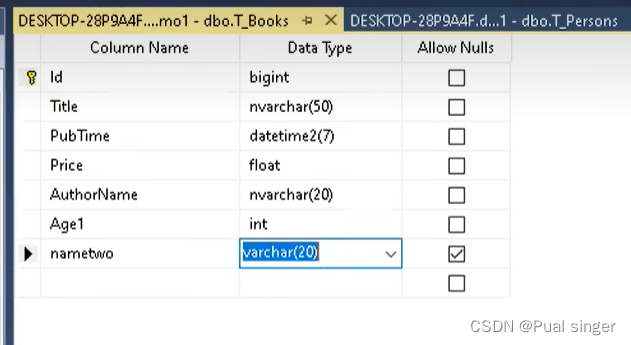
Fluent API 2
6、生成列的值
modelBuilder.Entity().Property(b =>b.Number).ValueGeneratedOnAdd();
7、可以用HasDefaultValue0为属性设定默认值modelBuilder.Entity().Property(b =>b.Age).HasDefaultValue(6);
8、索引
modelBuilder.Entity().HasIndex(b => b.Url);
复合索引modelBuilder.Entity().HasIndex(p => new { p.FirstName,p.LastName});唯一索引: IsUnique0; 聚集索引: IsClustered()
9… 用EF Core太多高级特性的时候谨慎,尽量不要和业务逻辑混合在一起,以免“不能自拔”。比如Ignore、Shadow、Table Splitting等…
EFCORE Fluent API 其他
Fluent API众多方法
Fluent API中很多方法都有多个重载方法。比如HasIndexProperty().把Number属性定义为索引,下面两种方法都可以:
builder.HasIndex(“Number”);
builder.HasIndex(b=>b.Number);
推荐使用HasIndex(b=>b.Number)、Property(b => b.Number)这样的写法因为这样利用的是C#的强类型检查机制(字符串的方式,无法判断语法错误)

选择
1、Data Annotation 、Fluent API大部分功能重叠。可以混用但是不建议混用。
2、有人建议混用,即用了Data Annotation 的简单,又用到Fluent API的强大,而且实体类上标注的[MaxLength(50)][Required]等标注可以被ASPNET Core中的验证框架等复用。我为什么不建议混用。
3、我和业界很多人都倾向只使用Fluent API。本课以讲解FluentAPI为主(尽量用约定),如果项目强制用Data Annotation 请翻文档,知识都是通用的。
这篇关于杨中科 EFCore 第二部分 实体配置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




