本文主要是介绍PiflowX如何快速开发flink程序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PiflowX如何快速开发flink程序
参考资料
Flink最锋利的武器:Flink SQL入门和实战 | 附完整实现代码-腾讯云开发者社区-腾讯云 (tencent.com)
Flink SQL 背景
Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。
自 2015 年开始,阿里巴巴开始调研开源流计算引擎,最终决定基于 Flink 打造新一代计算引擎,针对 Flink 存在的不足进行优化和改进,并且在 2019 年初将最终代码开源,也就是我们熟知的 Blink。Blink 在原来的 Flink 基础上最显著的一个贡献就是 Flink SQL 的实现。
Flink SQL 是面向用户的 API 层,在我们传统的流式计算领域,比如 Storm、Spark Streaming 都会提供一些 Function 或者 Datastream API,用户通过 Java 或 Scala 写业务逻辑,这种方式虽然灵活,但有一些不足,比如具备一定门槛且调优较难,随着版本的不断更新,API 也出现了很多不兼容的地方。

在这个背景下,毫无疑问,SQL 就成了我们最佳选择,之所以选择将 SQL 作为核心 API,是因为其具有几个非常重要的特点:
- SQL 属于设定式语言,用户只要表达清楚需求即可,不需要了解具体做法;
- SQL 可优化,内置多种查询优化器,这些查询优化器可为 SQL 翻译出最优执行计划;
- SQL 易于理解,不同行业和领域的人都懂,学习成本较低;
- SQL 非常稳定,在数据库 30 多年的历史中,SQL 本身变化较少;
- 流与批的统一,Flink 底层 Runtime 本身就是一个流与批统一的引擎,而 SQL 可以做到 API 层的流与批统一。
Flink SQL 常规实战应用
案例来自(Flink最锋利的武器:Flink SQL入门和实战 | 附完整实现代码-腾讯云开发者社区-腾讯云 (tencent.com))!详细流程有兴趣可以参考原文示例。(如有侵犯,请请联系!)。
在此,简单总结一下flink sql的开发流程:
1.首先需要创建maven工程,确认需要的各种依赖,运气好的话,还需要花费大量的精力和时间去排查依赖冲突的问题(oh God bless me!);
2.开始balabala编写模板代码,如:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment tableEnv = BatchTableEnvironment.getTableEnvironment(env);
3.数据准备和预处理;
DataSet<String> input = env.readTextFile("score.csv");DataSet<PlayerData> topInput = input.map(new MapFunction<String, PlayerData>() {@Overridepublic PlayerData map(String s) throws Exception {String[] split = s.split(",");return new PlayerData(String.valueOf(split[0]),String.valueOf(split[1]),String.valueOf(split[2]),Integer.valueOf(split[3]),Double.valueOf(split[4]),Double.valueOf(split[5]),Double.valueOf(split[6]),Double.valueOf(split[7]),Double.valueOf(split[8]));}});
其中的PlayerData类为自定义类:
public static class PlayerData {/*** 赛季,球员,出场,首发,时间,助攻,抢断,盖帽,得分*/public String season;public String player;public String play_num;public Integer first_court;public Double time;public Double assists;public Double steals;public Double blocks;public Double scores;public PlayerData() {super();}public PlayerData(String season,String player,String play_num,Integer first_court,Double time,Double assists,Double steals,Double blocks,Double scores) {this.season = season;this.player = player;this.play_num = play_num;this.first_court = first_court;this.time = time;this.assists = assists;this.steals = steals;this.blocks = blocks;this.scores = scores;}}
4.终于到了真正的业务处理了,有了flink sql的强大和方便,倒是省了不少代码;
Table queryResult = tableEnv.sqlQuery("
select player, count(season) as num FROM score GROUP BY player ORDER BY num desc LIMIT 3
");
5.ok,到此,数据处理和计算逻辑完毕,处理结果写入到sink,可以完结散花咯,哈哈;
DataSet<Result> result = tableEnv.toDataSet(queryResult, Result.class);
result.print();
6.哦!好像还需要调试运行,好吧,再辛苦一会,便可大功告成!


7.完美,上线。。。。。。

(以上,纯属娱乐,如有不当,敬请谅解!)
可见,在平日开发一个flink任务虽已尽可能简单,但开发周期也得1-2个工作日,甚至更长,有没有简单粗暴的,让我分分钟领盒饭,不,让我分分钟高效完成任务的!


当然有啦!!!接下来让我隆重的介绍一下今天的主角—PilfowX—大数据流水线系统。有兴趣可以查看之前的文章(StreamPark + PiflowX 打造新一代大数据计算处理平台-CSDN博客)。

PiflowX是基于Piflow和StreamPark二开实现的,在其基础上,实现了图像化拖拉拽的方式开发spark或flink作业,这里我将介绍flink任务的开发流程,以及如何零代码实现flink sql的开发。
PiflowX的flink组件算子基本都是基于flink table和sql实现的,我们只需在UI界面填写组件相关参数,之后的工作交给底层框架即可。
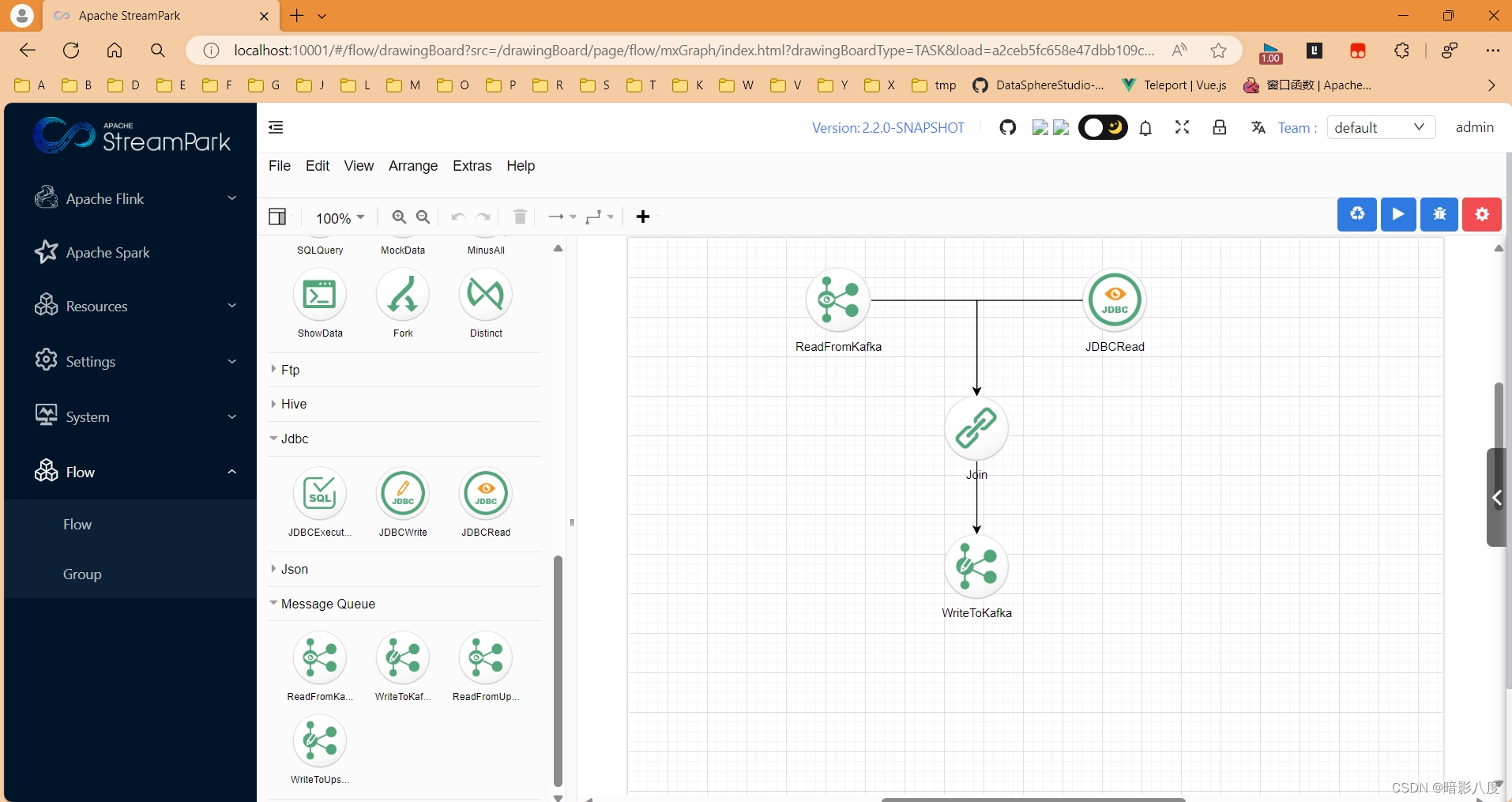
我们回顾一下flink sql语法定义。
Flink SQL 的语法和算子
Flink SQL 核心算子的语义设计参考了 1992、2011 等 ANSI-SQL 标准,Flink 使用 Apache Calcite 解析 SQL ,Calcite 支持标准的 ANSI SQL。
CREATE TABLE [IF NOT EXISTS] [catalog_name.][db_name.]table_name({ <physical_column_definition> | <metadata_column_definition> | <computed_column_definition> }[ , ...n][ <watermark_definition> ][ <table_constraint> ][ , ...n])[COMMENT table_comment][PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]WITH (key1=val1, key2=val2, ...)[ LIKE source_table [( <like_options> )] | AS select_query ]<physical_column_definition>:column_name column_type [ <column_constraint> ] [COMMENT column_comment]<column_constraint>:[CONSTRAINT constraint_name] PRIMARY KEY NOT ENFORCED<table_constraint>:[CONSTRAINT constraint_name] PRIMARY KEY (column_name, ...) NOT ENFORCED<metadata_column_definition>:column_name column_type METADATA [ FROM metadata_key ] [ VIRTUAL ]<computed_column_definition>:column_name AS computed_column_expression [COMMENT column_comment]<watermark_definition>:WATERMARK FOR rowtime_column_name AS watermark_strategy_expression<source_table>:[catalog_name.][db_name.]table_name<like_options>:
{{ INCLUDING | EXCLUDING } { ALL | CONSTRAINTS | PARTITIONS }| { INCLUDING | EXCLUDING | OVERWRITING } { GENERATED | OPTIONS | WATERMARKS }
}[, ...]
PiflowX组件flink table实现
在了解了flink sql的定义后,一切便简单多了,那么,我们只需要根据业务需要,设计出一个表单输入,填写我们的业务参数,然后,由框架自动生成sql不就可以了么。
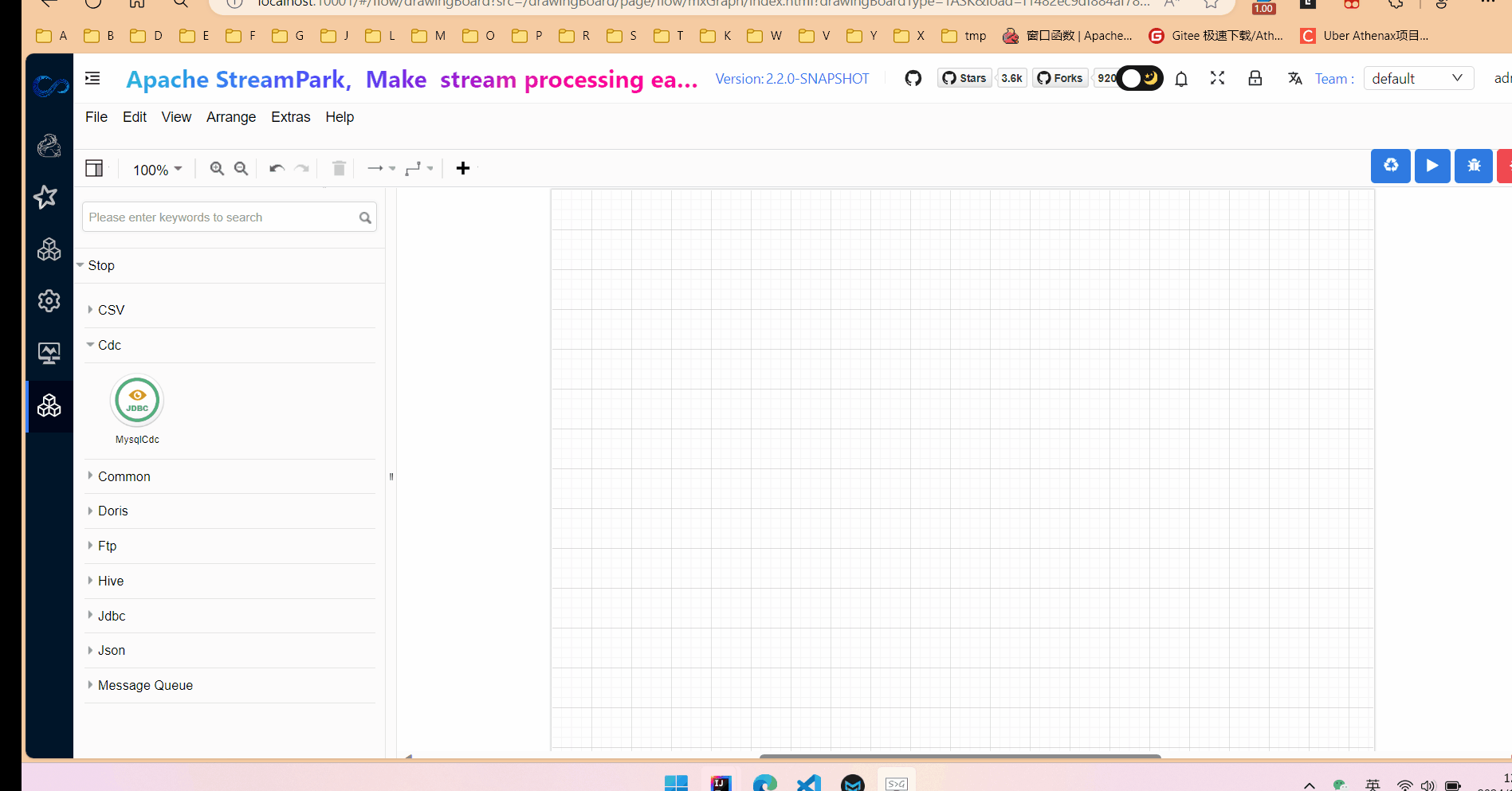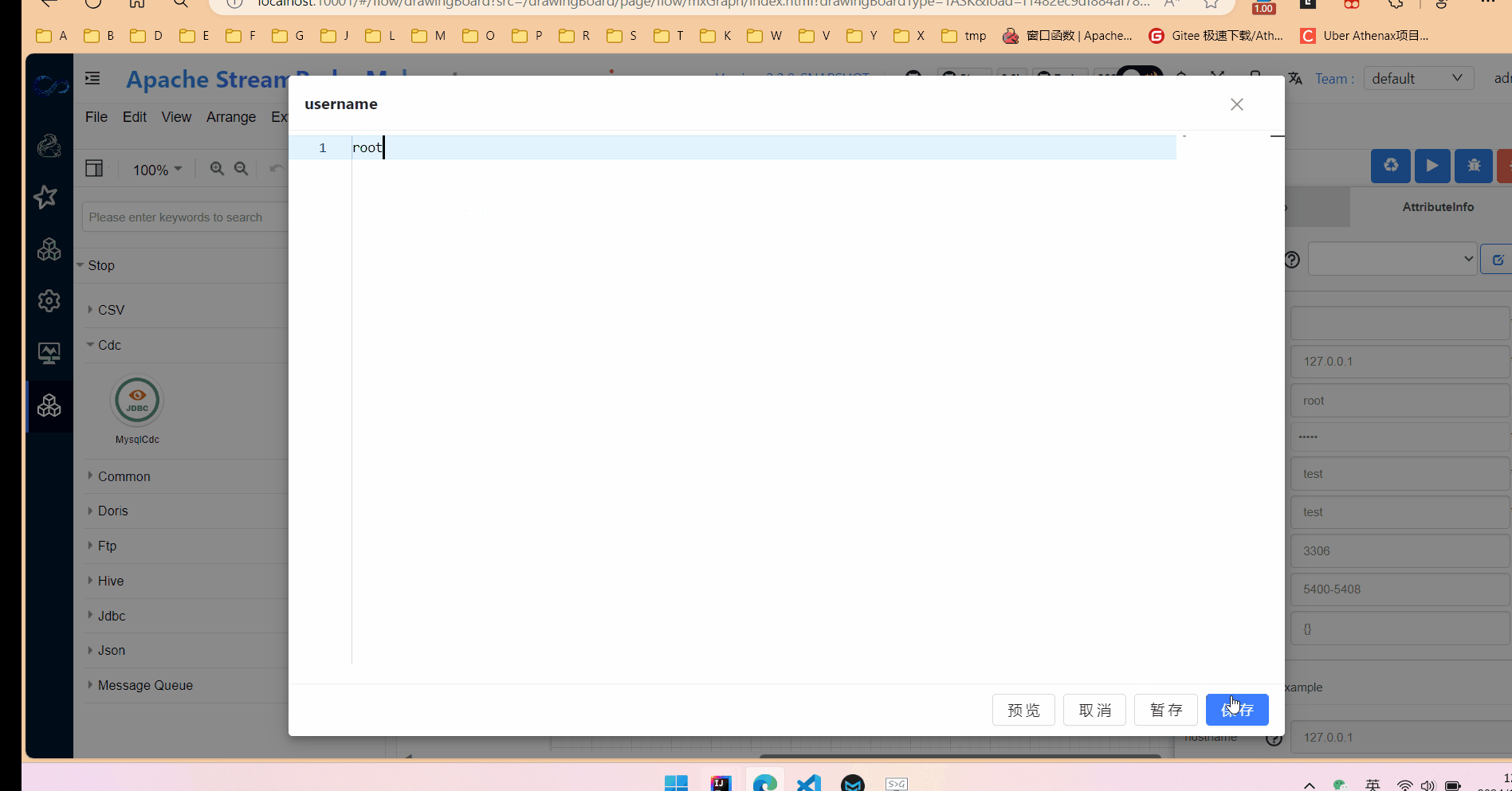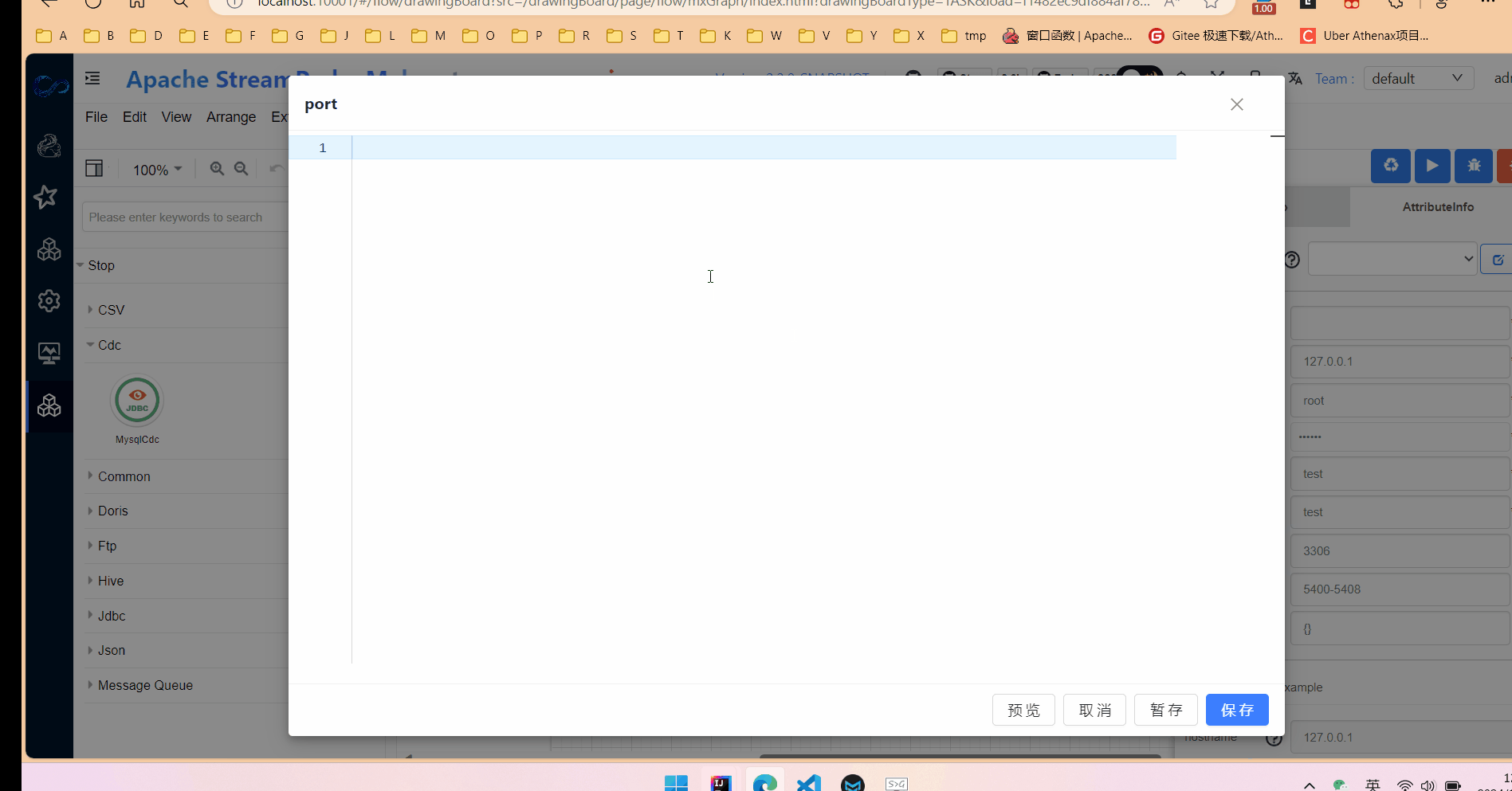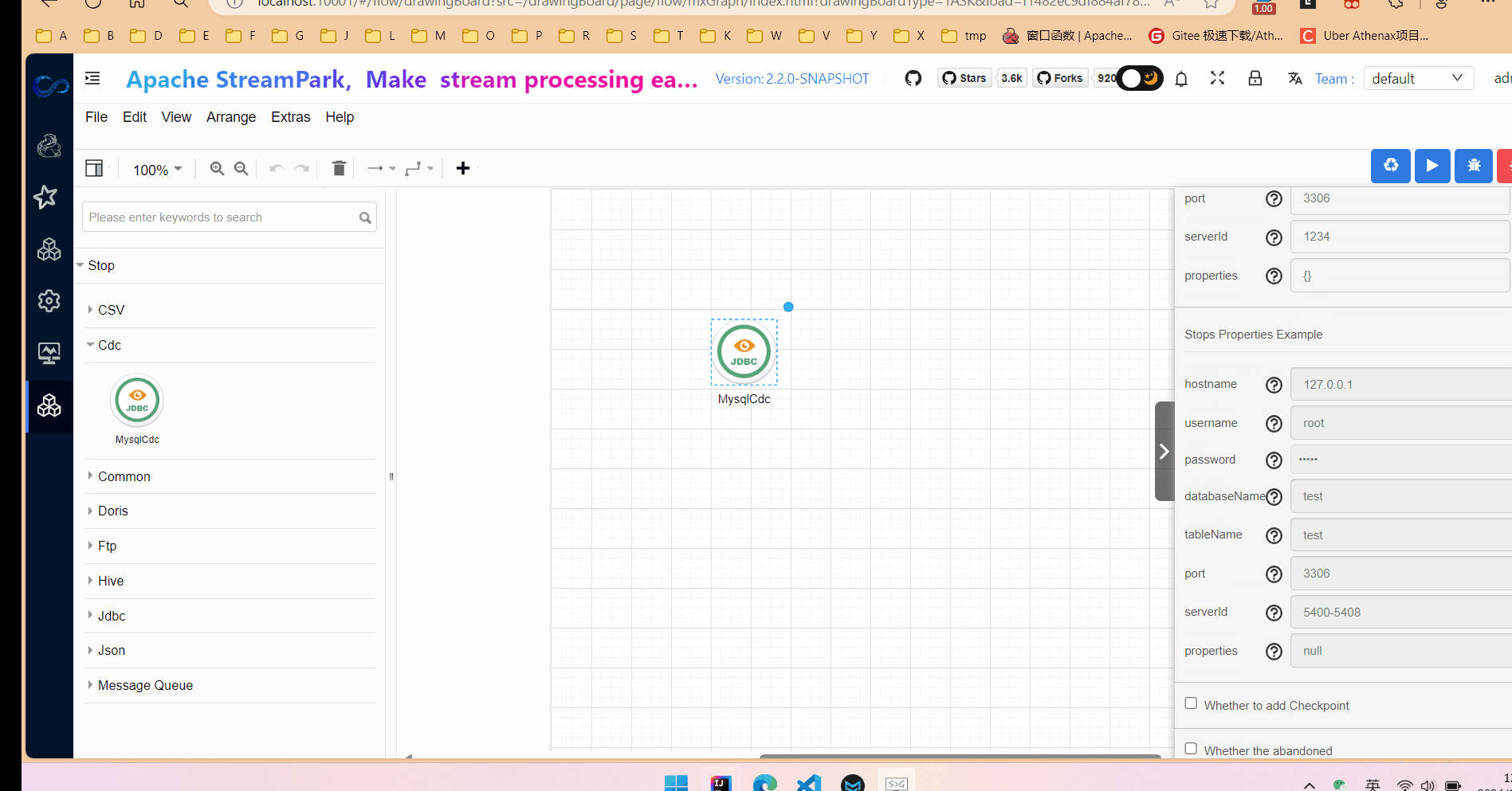
以下介绍如何配置一个mysqlcdc组件:
1.首先从组件列表中拖入一个MysqlCdc组件到画布中,点击节点,右侧会显示出节点参数表单区域和参数说明和示例。参数解释可以查看之前的文章(PiflowX-MysqlCdc组件-CSDN博客)。


2.填写相关参数,其实就是在定义flink table中的with属性。
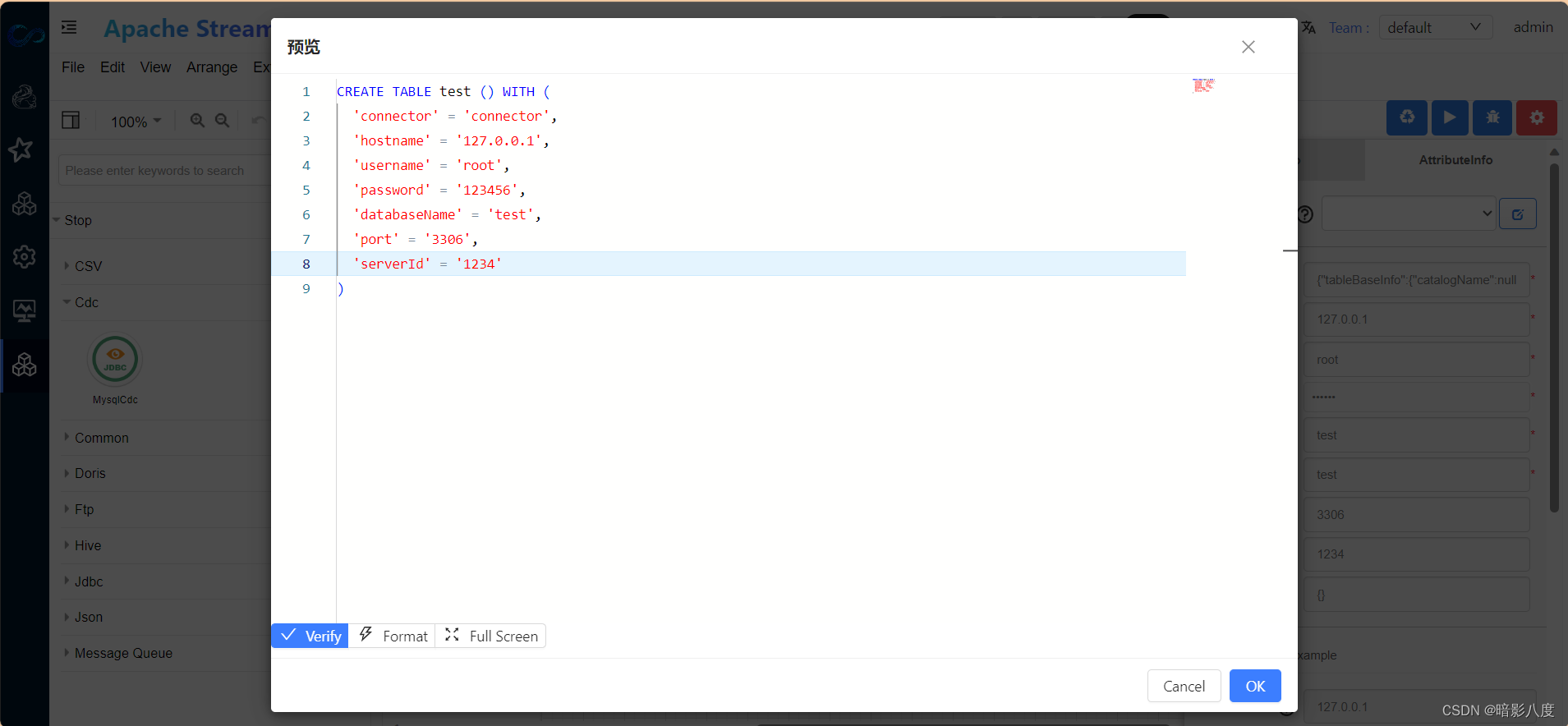
在属性输入框中,点击预览可以实时查看生成的flink sql。

生成的flink sql 语句仅供参考,最终执行的语句会在引擎执行侧生成。
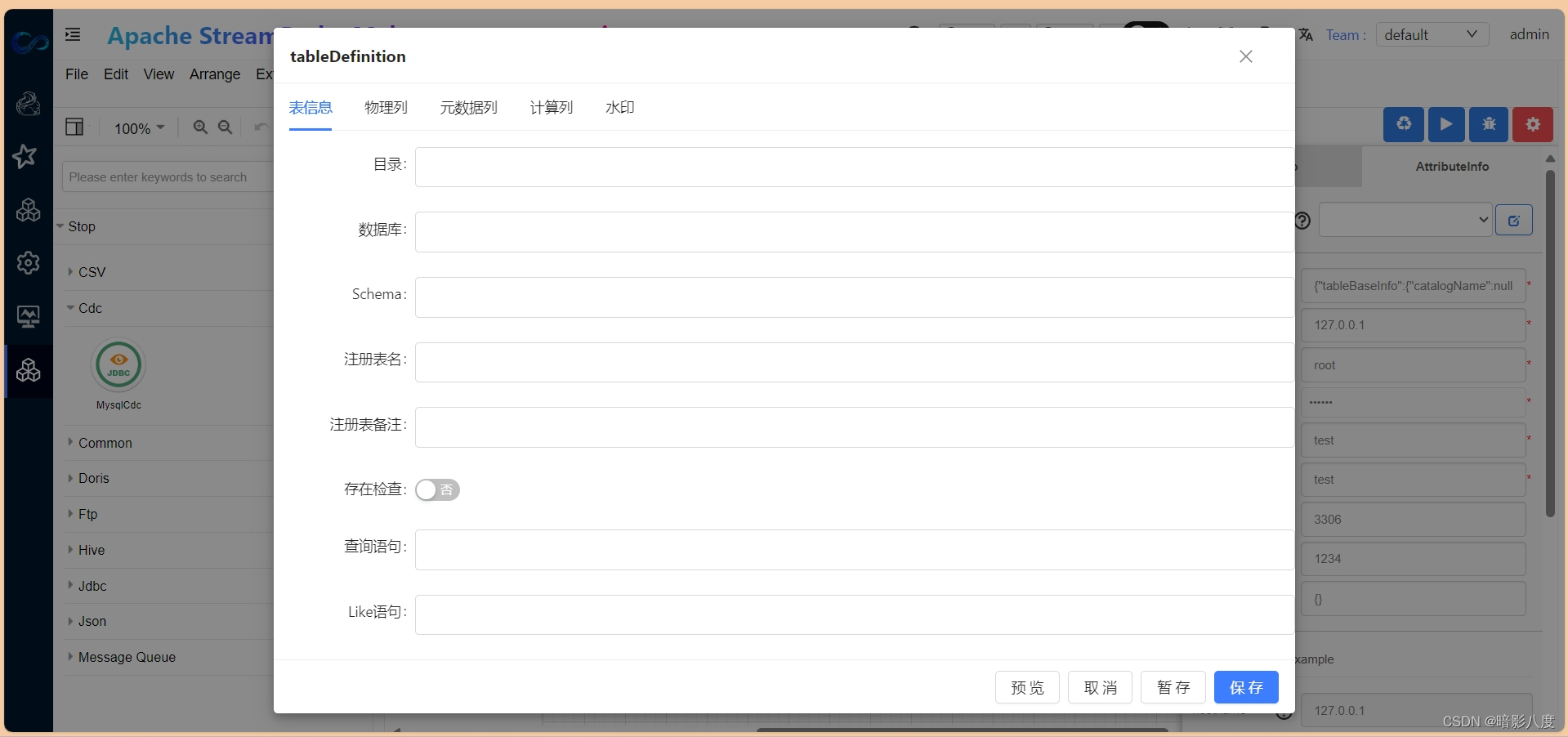
3.接下来我们可以根据需要来定义flink table结构,此步骤和其他步骤没有先后顺序。点击表单属性tableDefinition,在此表单中我们可以输入flink table中的结构属性定义。
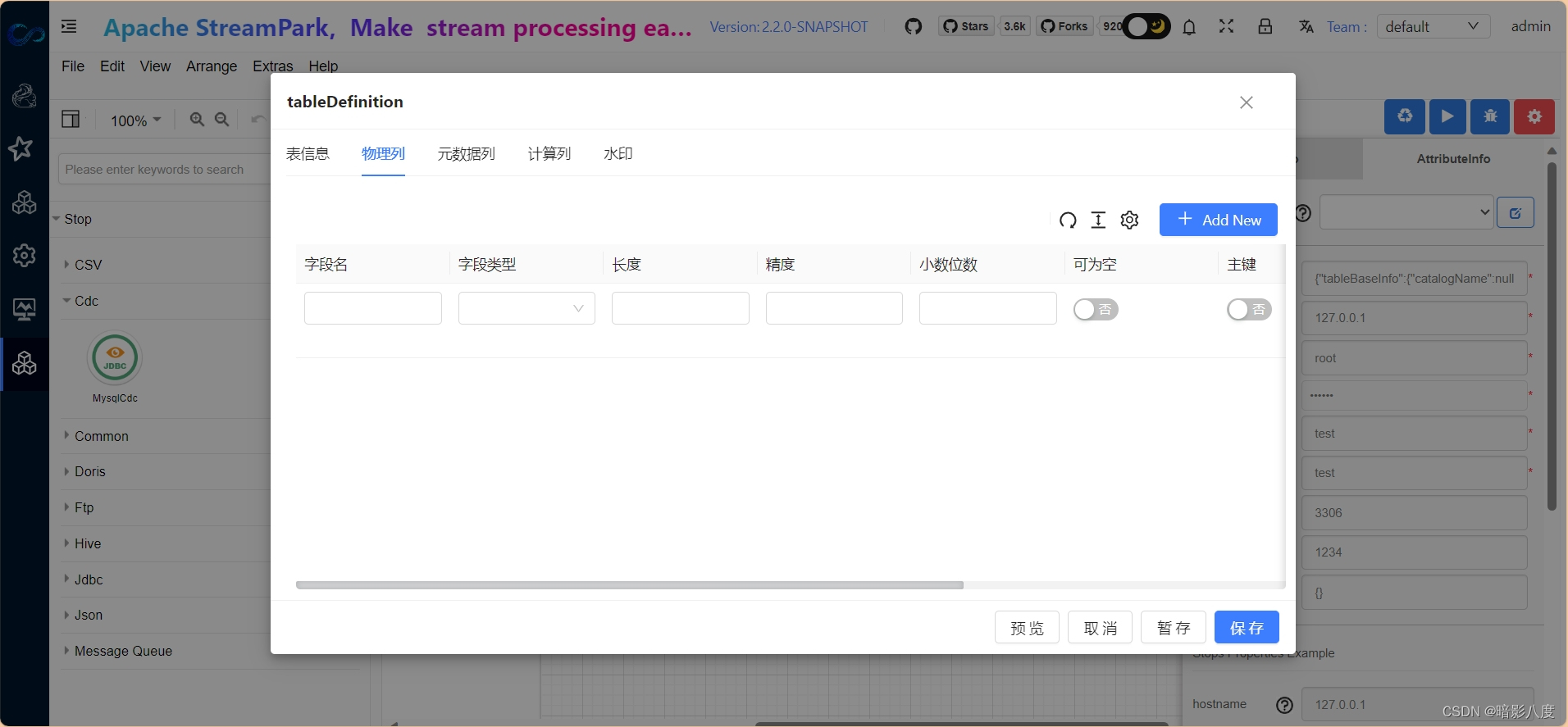
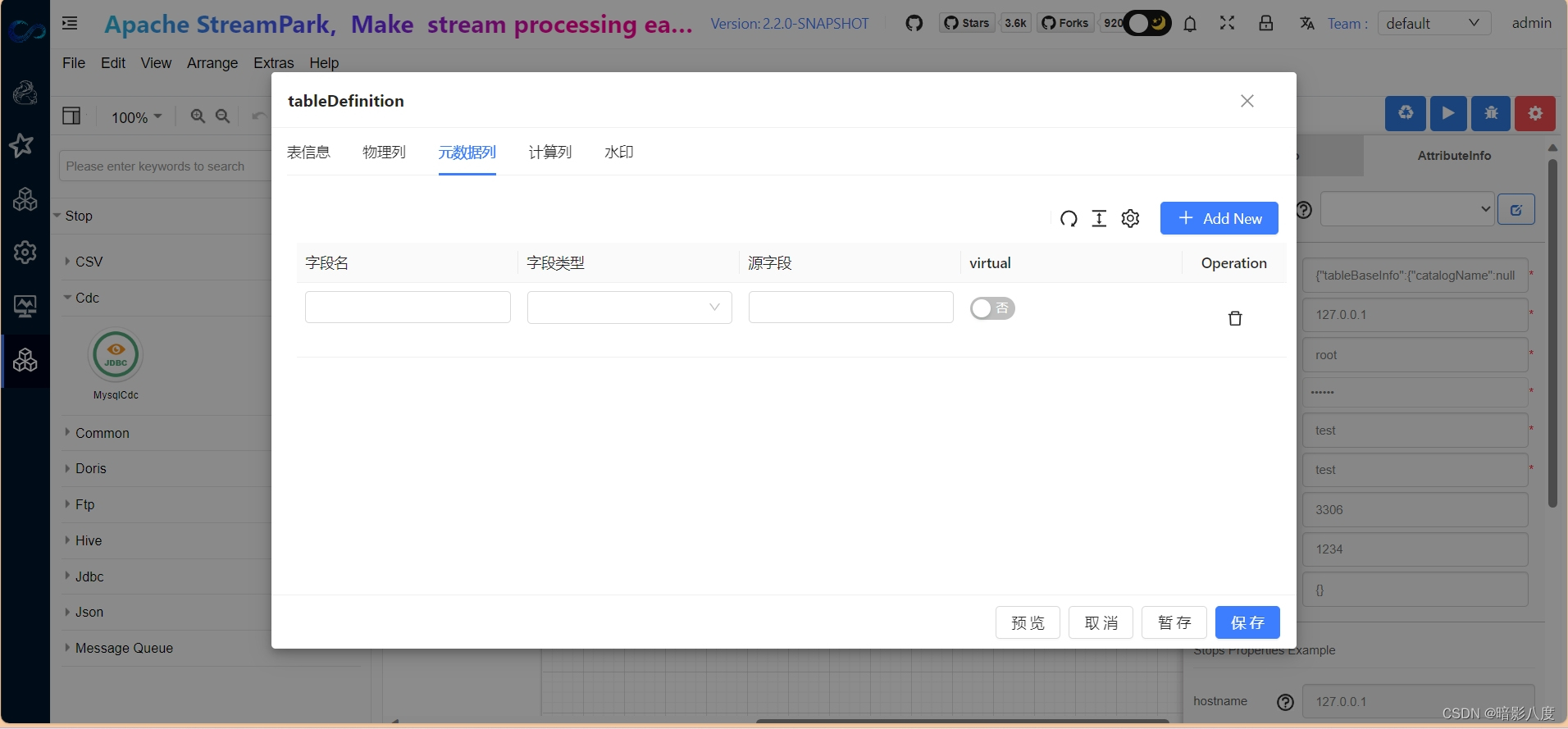
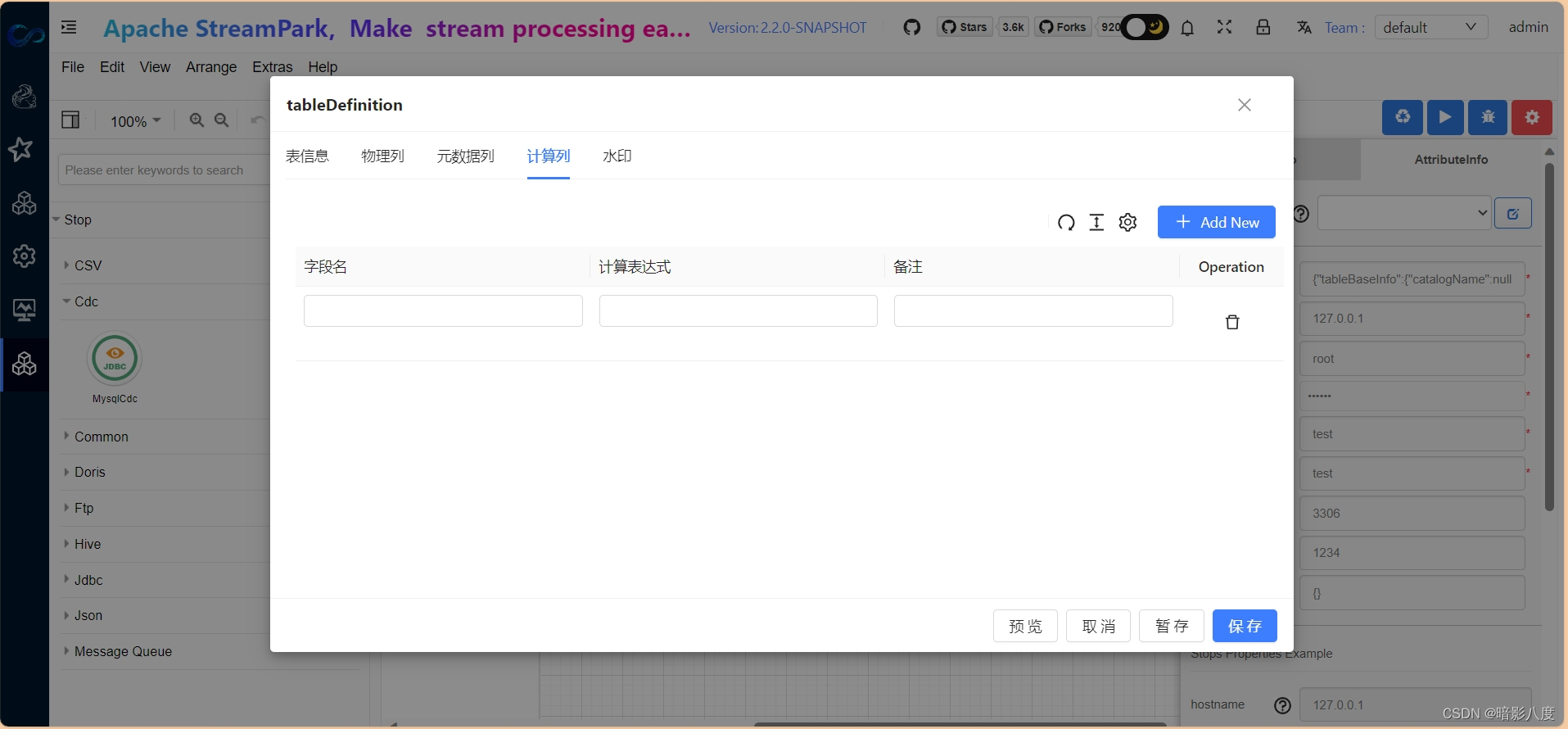
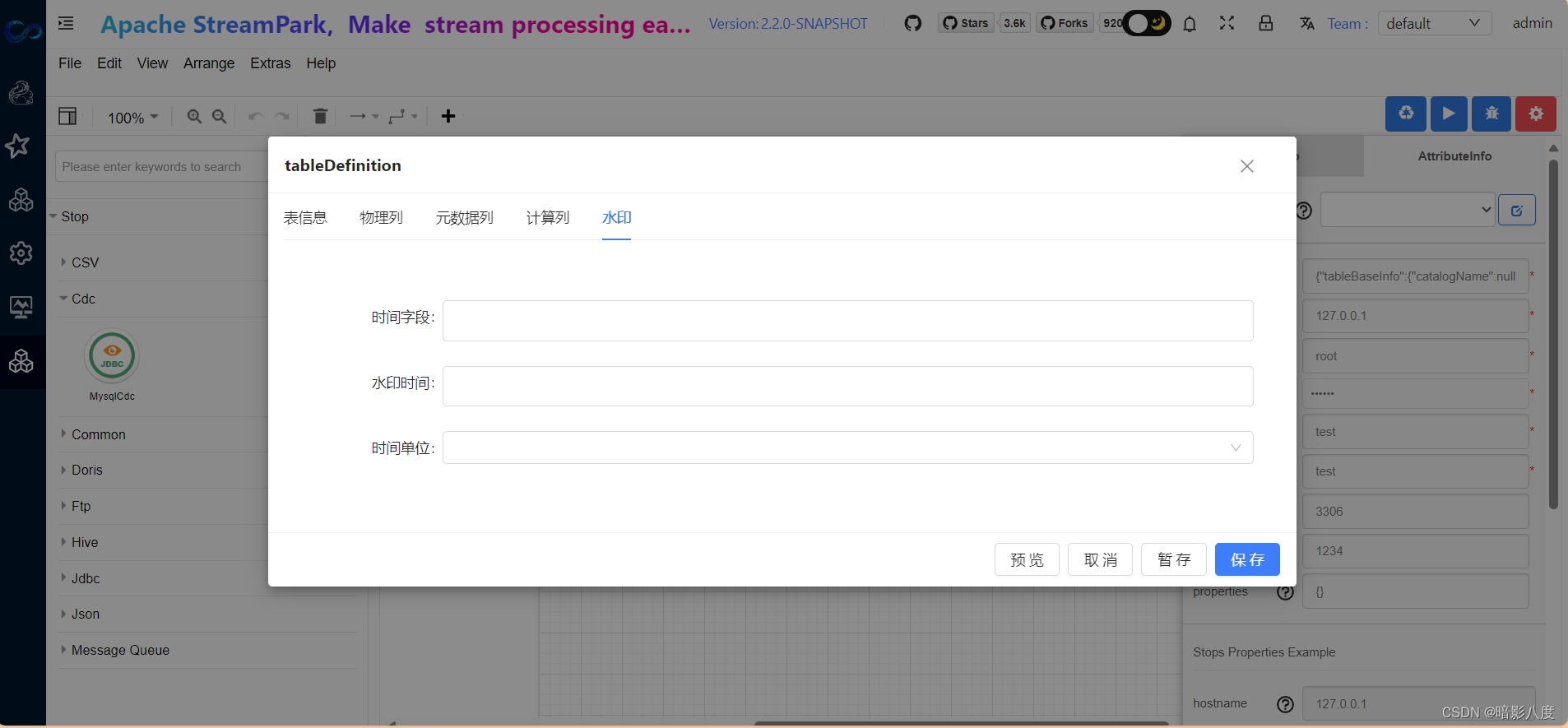
可以看到,我们可以在此定义flink table中的表基本信息,物理列,元数据列,计算列,水印等,具体说明在此就不赘述了,以后会有具体文章来说明。看看最终的效果:
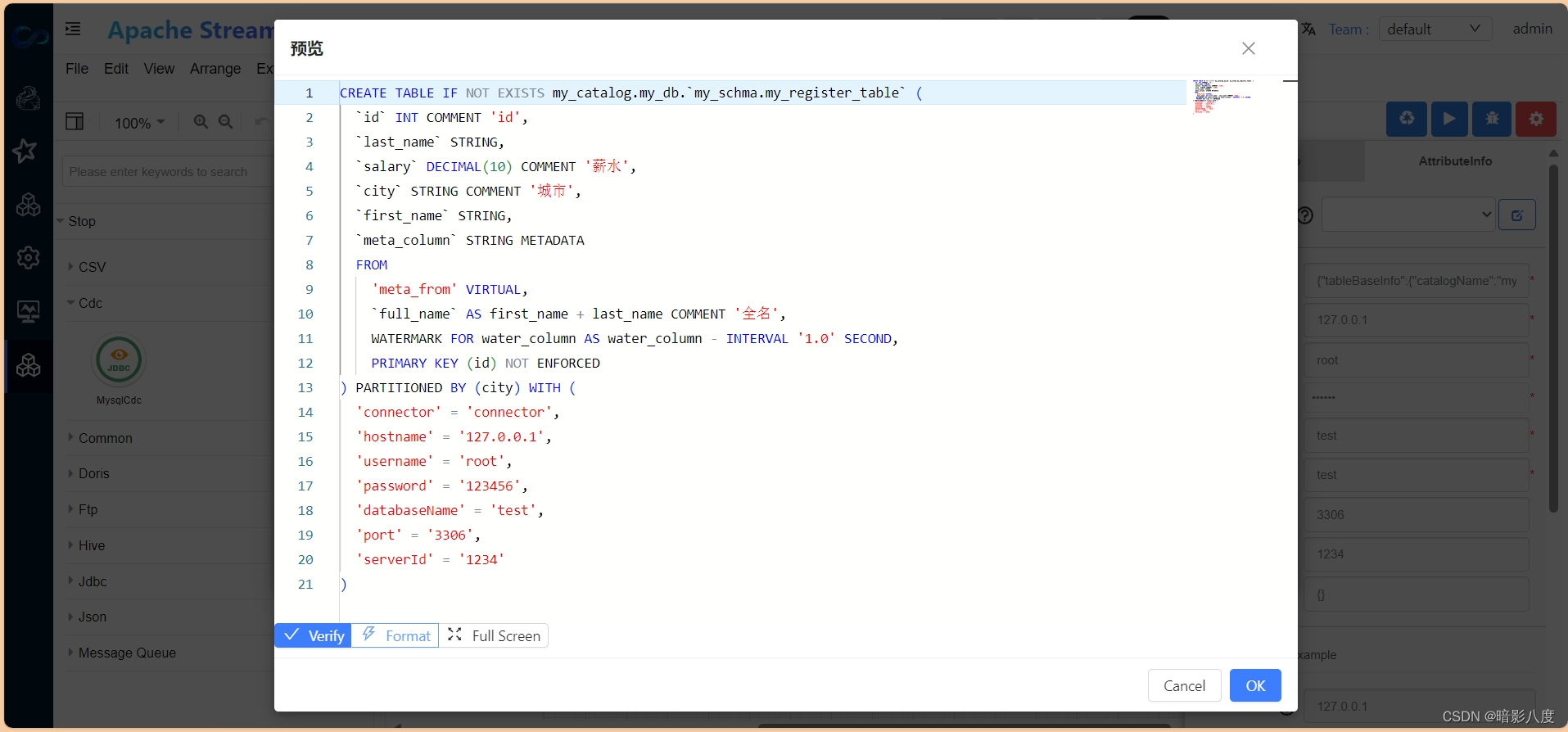
至此,我们通过简单的表单填写,便可开发一个flink任务,最后,点击运行,系统便可自动提交到flink环境,并可实时查看运行日志,是不是很方便快捷!
当然,目前系统处于初期研发阶段,还有很多不完善的地方,敬请谅解。最后,我们来看一个简单的实例,如果通过PiflowX开发一个mysql cdc实时同步和flink读取doris的任务。
PiflowX-Droris读写组件
PiflowX-MysqlCdc组件
这篇关于PiflowX如何快速开发flink程序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







