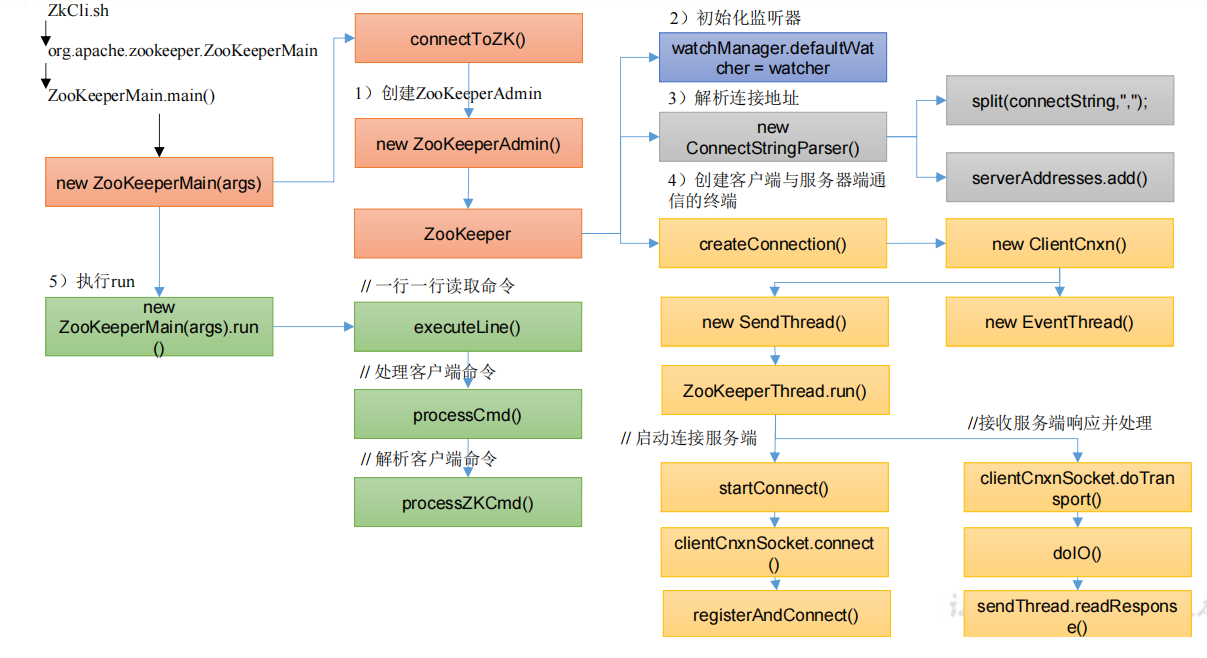
本文主要是介绍Zookeeper3.5.7,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
从设计模式角度理解
观察者模式设计的分布式服务管理框架,负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,zk就将负责通知已经在zk上注册的那些观察者做出响应的反应;zk=文件系统+通知系统;
1.一个leader和多个follower组成的集群
2.只要半数以上节点存活,就可以提供服务,适合安装奇数台服务器
3.全局数据一致,每个server保存一份相同数据的副本,client无论连到哪个server,数据都是一致
4.来自同一个client的更新请求按其发送顺序依次执行
5.数据更新原子性,一次数据更新要么成功要么失败
6.实时性,在一定时间范围内,client能读到最新数据
节点数多,好处:提高可靠性,坏处,增加通信延迟
数据结构
与unix文件系统类似,整体上可以看做一棵树,每个节点称做一个znode,默认存储1MB数据,每个znode都可以通过其路径唯一标识;
应用场景
统一命名服务
分布式环境下,经常需要对应用/服务进行统一命名,便于识别
统一配置管理
一个集群中所有节点配置信息一致;修改后快速同步到各个节点;
统一集群管理
实时掌握每个节点的状态,将节点信息写入zk上的一个znode
服务器动态上下线
客户端实时洞察到服务器上下线的变化
软负载均衡
记录每个server的访问数,让访问最少的server去处理最新的客户端请求
节点类型
1.持久节点(PERSISTENT)
所谓持久节点,是指在节点创建后,就一直存在,直到有删除操作来主动清除这个节点——不会因为创建该节点的客户端会话失效而消失
2.持久顺序节点(PERSISTENT_SEQUENTIAL)
给创建的持久节点后面加上序号后缀。 非常适用于分布式锁、分布式选举等场景
3.临时节点(EPHEMERAL)
如果客户端会话失效,那么这个节点就会自动被清除掉。会话失效,而非连接断开。临时节点下面不能创建子节点
4.临时顺序节点(EPHEMERAL_SEQUENTIAL)
配置参数解读
配置文件zoo.cfg中参数含义解读
1.tickTime=2000
通信心跳时间,zk服务器与客户端心跳时间,单位毫秒
2.initLimit=10
LF初始通信时限,leader和follower初始连接时,能容忍的最多心跳数(tickTime的数量)
3.syncLimit=5
LF同步通信时限,超时就会从服务器列表中删除follower
4.dataDir
保存zk中的数据,默认tmp目录,容易被linux系统定期删除(需要修改)
5.clientPort=2181
客户端连接端口,通常不做修改
选举机制
首次
先选自己,然后把选票投给myid较大的,如果leader被选出,其它自动变为follower,再新增服务直接变为follower
sid:服务器id,用来唯一标识一台zk集群中的机器,每台机器不能重复,和myid一致
zxid:事务id,用来标识一次服务器状态的变更。在某一时刻,集群中的每台机器的zxid值不一定完全一致,这和zk服务器对于客户端”更新请求“的处理逻辑有关
epoch:每个leader任期的代号。没有leader时同一轮投票过程中的逻辑时钟值是相同的,每投完一次票这个数据就会增加。
非首次
以下两种情况,就开始leader选举:
1.服务器启动
2.运行期间无法和leader保持连接
当一台机器进入leader选举流程时,当前集群也可能处于两种状态:
1.集群中本来已经存在一个leader,只能建立连接作为follower
2.集群中确实不存在leader
选举规则:按照优先级比较epoch---zxid---sid
客服端写入流程
1.写入leader
写入follower,获得应答,超过半数写入成功,则leader发送ack给客户端
2.写入follower
转发给leader先写入,自己再写入,超过半数写入成功,则leader发送ack给接收的follower,最后follower发送ack给客户端
服务器动态上下线案例
1.服务端注册到zk集群临时节点(/servers)-e -s
2.客户端监听znode(/servers)下面子节点的增加或删除
分布式锁案例
1.接收请求后,在locks节点下建立一个临时顺序节点
2.判断自己是不是最小节点,是则获取锁,如果不是则监听前一个;
3.业务处理结束,删除顺序节点释放锁,后面的节点将收到通知,重复步骤2判断;
有现成分布式锁框架使用,curator框架
拜占庭将军问题
参考
深入剖析Zookeeper原理(二)ZK集群选举原理_麦神-mirson的博客-CSDN博客_zk集群选举1. PAXOS选举算法Paxos算法概述背景:主流分布式一致性算法包括Paxos,Raft和ZAB,它们之间有怎样的区别与关系?Google Chubby的作者Mike Burrows说过,世上只有一种一致性算法,那就是Paxos,所有其他一致性算法都是Paxos算法的不完整或衍生版。什么是Paxos?Paxos算法是基于消息传递且具有高度容错特性的一致性算法,是目前公认的解决分布式一致性问题最有效的算法之一,其解决的问题就是在分布式系统中如何就某个值(决议)达成一致。Paxos的作用:https://blog.csdn.net/hxx688/article/details/119621308?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164921238816780269841482%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164921238816780269841482&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-5-119621308.142%5Ev5%5Econtrol,157%5Ev4%5Enew_style&utm_term=zk+%E6%8B%9C%E5%8D%A0%E5%BA%AD&spm=1018.2226.3001.4187
这篇关于Zookeeper3.5.7的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!