本文主要是介绍Qt::qcustomplot 和 qchart数据填充相关,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考文章
QCustomPlot 使用整理 - Biiigfish - 博客园
QCustomPlot :曲线数据的填充_Fu_Lin_的博客-CSDN博客b
自绘制饼图:
Qt之自绘制饼图 - 朝十晚八 - 博客园
qcustomplot
折线图
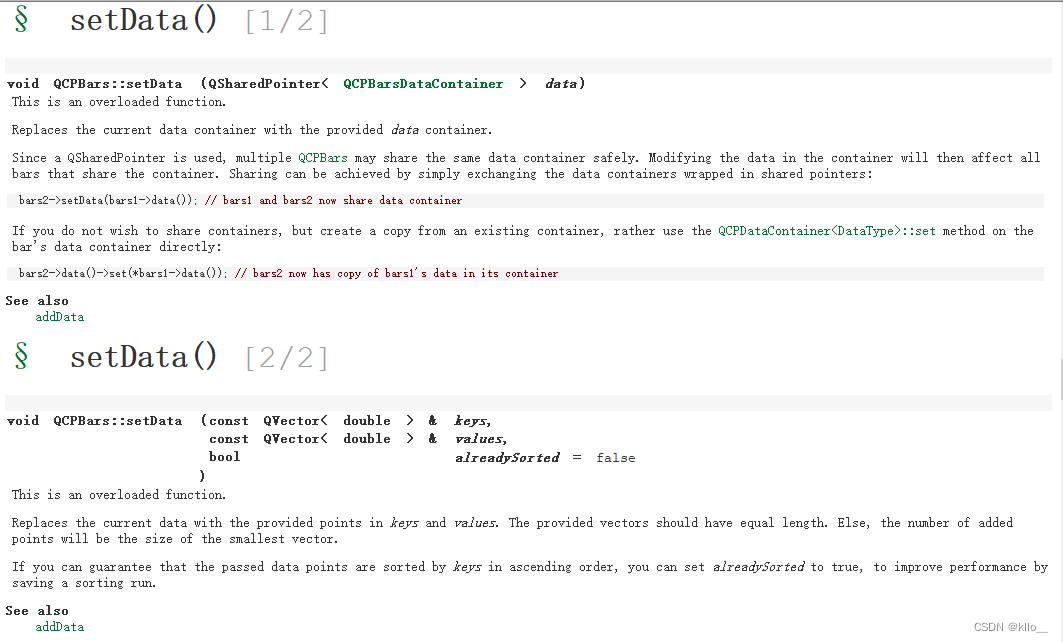
setData()
void QCPGraph::setData(QSharedPointer<QCPGraphDataContainer> data)
//用提供的数据容器替换当前数据容器。//由于使用了 QSharedPointer,多个 QCPGraph 可以安全地共享同一个数据容器。修改容器中的数据将影响共享该容器的所有图表。共享可以通过简单地交换包含在共享指针中的数据容器来实现:
//使用示例 两条曲线共享数据容器graph2->setData(graph1->data()); // graph1 and graph2 now share data container
如果您不希望共享容器,而是从现有容器创建副本,则直接在图形的数据容器上使用QCPDataContainer<DataType>::set方法:graph2->data()->set(*graph1->data()); // graph2 现在在其容器中拥有 graph1 数据的副本void QCPGraph::setData(const QVector<double> & keys, const QVector<double> & values, bool alreadySorted = false)
//将当前的数据替换成提供的 keys 和 values,keys 和 values 必须长度相等,否则添加的点的数量为最短的向量的长度
//如果你能保证传递的数据点按key升序排序,你可以设置alreadySorted 为true,通过保存排序运行来提高性能。addData
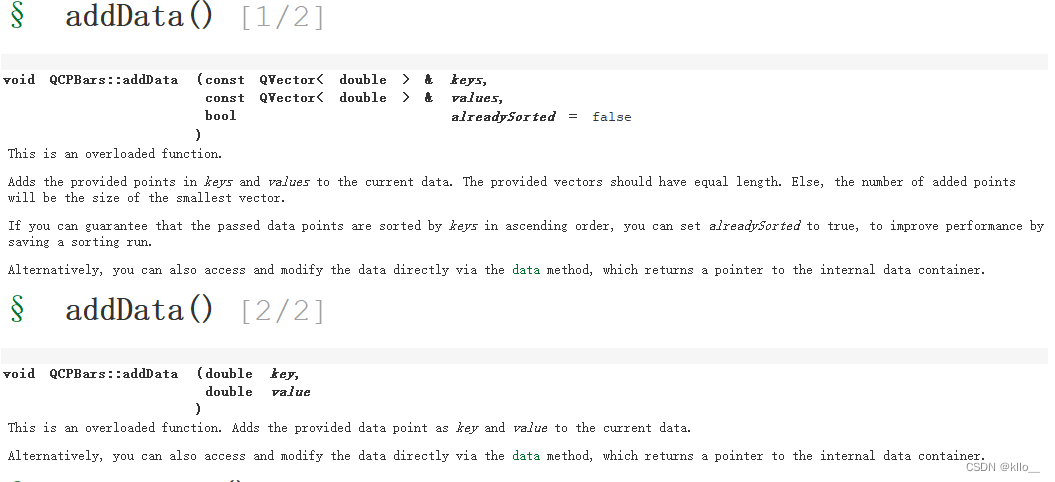
//addDatavoid QCPGraph::addData ( const QVector< double > & keys, const QVector< double > & values, bool alreadySorted = false )
//将 keys 和 values 中提供的点添加到当前数据。提供的向量应该具有相同的长度。否则,添加点的数量将是最小向量的大小。如果你能保证传递的数据点按key升序排序,你可以设置alreadySorted 为true,通过保存排序运行来提高性能。或者,您也可以直接通过data方法访问和修改数据,该方法返回指向内部数据容器的指针。void QCPGraph::addData ( double key, double value )
将提供的数据点作为 key 和 value 添加到当前数据。或者,您也可以直接通过data方法访问和修改数据,该方法返回指向内部数据容器的指针。柱状图
和折线图的差不多,基本一致
qchart
折线图
折线图没有使用qchart画
柱状图

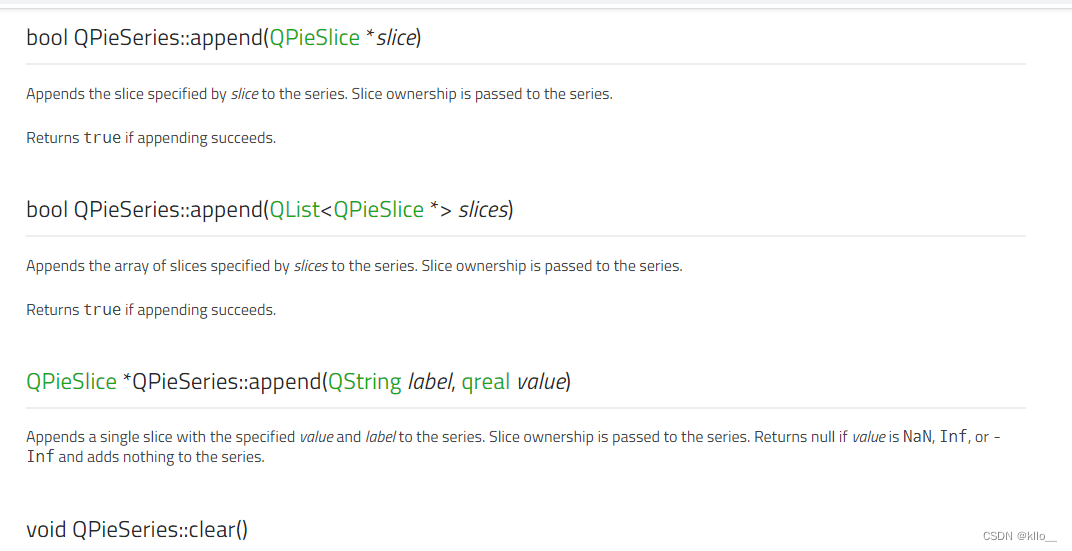
饼状图
这篇关于Qt::qcustomplot 和 qchart数据填充相关的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





