本文主要是介绍TensorFlow的广播机制(Broadcasting),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Broadcasting 也叫广播机制(自动扩展也许更合适),它是一种轻量级张量复制的手段,在逻辑上扩展张量数据的形状,但是只要在需要时才会执行实际存储复制操作。
Broadcasting 和 tf.tile 复制的最终效果是一样的,操作对用户透明,但是 Broadcasting 机制节省了大量计算资源。
import tensorflow as tf
x = tf.random.normal([2,4])
w = tf.random.normal([4,3])
b = tf.random.normal([3])
y = x@w+b
y<tf.Tensor: id=19, shape=(2, 3), dtype=float32, numpy=
array([[ 1.989155 , -1.2222767, 2.6319995],[-1.653671 , 4.364832 , 2.905215 ]], dtype=float32)>
上面代码中y是shape[2,3]的张量和shape[3]的张量相加,为什么没有报错呢?
这是因为它自动调用 Broadcasting函数 tf.broadcast_to(x, new_shape),将 2 者 shape 扩张为相同的[2,3],即上式等效为:
y = x@w + tf.broadcast_to(b,[2,3])
这样最终的结果就会是一个shape为[2, 3]的张量。
有了Broadcasting机制后,只要运算的逻辑都正确,shape不一致的张量哦都可以直接完成运算,Broadcasting机制并不会扰乱正常的计算逻辑。
Broadcasting 机制的核心思想是普适性,即同一份数据能普遍适合于其他位置。在验证普适性之前,需要将张量 shape 靠右对齐,然后进行普适性判断:对于长度为 1 的维度,默认这个数据普遍适合于当前维度的其他位置;对于不存在的维度,则在增加新维度后默认当前数据也是普适性于新维度的,从而可以扩展为更多维度数、其他长度的张量形状。
下面来看看Broadcasting的原理:
比如一个shape为[w, 1]的张量A,需要扩展成为shape为[b, h, w, c]的张量
首先将两个shape靠右对齐,看看是否可以广播:
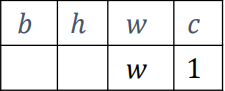
插入新维度:

然后扩展为相同的长度:
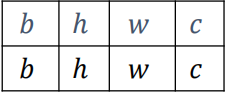
如下的例子满足满足普适性原则,可以广播。
A = tf.random.normal([32, 1])
tf.broadcast_to(A, [2, 32, 32, 4])<tf.Tensor: id=34, shape=(2, 32, 32, 4), dtype=float32, numpy=
array([[[[ 1.0603684 , 1.0603684 , 1.0603684 , 1.0603684 ],[-0.36812386, -0.36812386, -0.36812386, -0.36812386],[ 1.6407963 , 1.6407963 , 1.6407963 , 1.6407963 ],
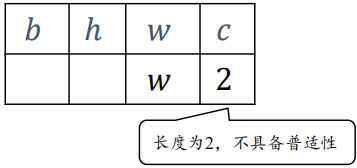
但是如下情况不满足普适性原则,如果广播会报错:
A = tf.random.normal([32, 2])
tf.broadcast_to(A, [2, 32, 32, 4])InvalidArgumentError Traceback (most recent call last)
<ipython-input-4-97cf9a5a8ab8> in <module>1 A = tf.random.normal([32, 2])
----> 2 tf.broadcast_to(A, [2, 32, 32, 4])
InvalidArgumentError: Incompatible shapes: [32,2] vs. [2,32,32,4] [Op:BroadcastTo]
这篇关于TensorFlow的广播机制(Broadcasting)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





