本文主要是介绍大模型日报-20240113,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
击败 8 名人类规划师:清华团队提出强化学习的城市空间规划模型

https://mp.weixin.qq.com/s/GkL5peKCOJLh4pLjiTeIFw
近年来,以更加宜居为导向,「15 分钟城市」概念得到了更多关注,其核心是居民在 15 分钟内可步行或骑行到基本服务设施,体现了人们对于城市社区内高效率空间布局的期待。然而,由于城市地理空间的多样性,城市用地布局和道路规划是一件非常复杂且困难的任务,一直高度依赖专业规划师的经验。针对于此,清华大学电子系城市科学与计算研究中心和建筑学院跨学科合作,创新地提出了基于深度强化学习的城市社区空间规划方法,提出的 AI 模型能够从海量数据中学习城市规划,不断优化空间效率,并最终达到超越人类专家的规划水平。
GauHuman开源:基于Gaussian Splatting,高质量3D人体快速重建和实时渲染框架

https://mp.weixin.qq.com/s/ObJFBj1tZ7TG6nN2RnMHbg
南洋理工大学 - 商汤科技联合研究中心 S-Lab 团队提出了基于 Gaussian Splatting 的高质量 3D 人体快速重建 (1~2 分钟) 和实时渲染 (高达 189 帧每秒) 框架 GauHuman。GauHuman 可以基于用户输入的一段单目人体视频,以及相应的相机和人体动作体型(SMPL)参数,快速重建该 3D 人体,并实时渲染该 3D 人体。
ChatGPT应用商店终上线,全网GPTs超300万,和OpenAI分钱时代来了
https://mp.weixin.qq.com/s/UHgRj3kisPxutoFB
ChatGPT 也要像微信、钉钉那样变成全功能 App 了?1 月 10 日,OpenAI 的应用商店 GPT Store 正式上线,分类、趋势、每周精选等栏目一应俱全。正像大部分应用商店那样,GPT Store 包括流行下载的社区排行榜,用户可以按类别搜索,例如写作、生活方式和教育。OpenAI Greg Brockman 表示,这是打造自己的 ChatGPT 的第一步。该产品仍在试验阶段,但希望在未来几周内更广泛地推广。
国内多所高校共建开源社区LAMM,加入多模态语言模型大家庭的时候到了

https://mp.weixin.qq.com/s/qLkYJgAb2EnM4gecXPyPFw
来自北航、复旦大学、悉尼大学、香港中文大学(深圳)等高校与上海人工智能实验室的学者共同推出多模态语言模型最早的开源社区之一 ——LAMM(Language-Assisted Multi-modal Model)。我们旨在将 LAMM 建设成一个不断发展的社区生态,支持 MLLM 训练和评测、MLLM 驱动的 Agent 等方向的研究。作为多模态大语言模型领域最早的开源项目之一,LAMM 的目标是建立一个开放的研究社区生态,让每个研究和开发人员都可以基于此开展研究,共同建设开源社区。
上海AI实验室等开源,音频、音乐统一开发工具包Amphion

https://mp.weixin.qq.com/s/JIiis1pgstfN9elQZpD2cg
上海AI实验室、香港中文大学数据科学院、深圳大数据研究院联合开源了一个名为Amphion的音频、音乐和语音生成工具包。Amphion可帮助开发人员研究文本生成音频、音乐等与音频相关的领域,可以在一个框架内完成,以解决生成模型黑箱、代码库分散、缺少评估指标等难题。Amphion包含了数据处理、通用模块、优化算法等基础设施。同时针对文本到语音、歌声转换、文本到音频生成等任务,提供了特定的框架、模型和开发说明,还内置了各类神经语音编解码器和评价指标。尤其是对于那些刚接触生成式AI开发的新手来说,Amphion非常容易上手。
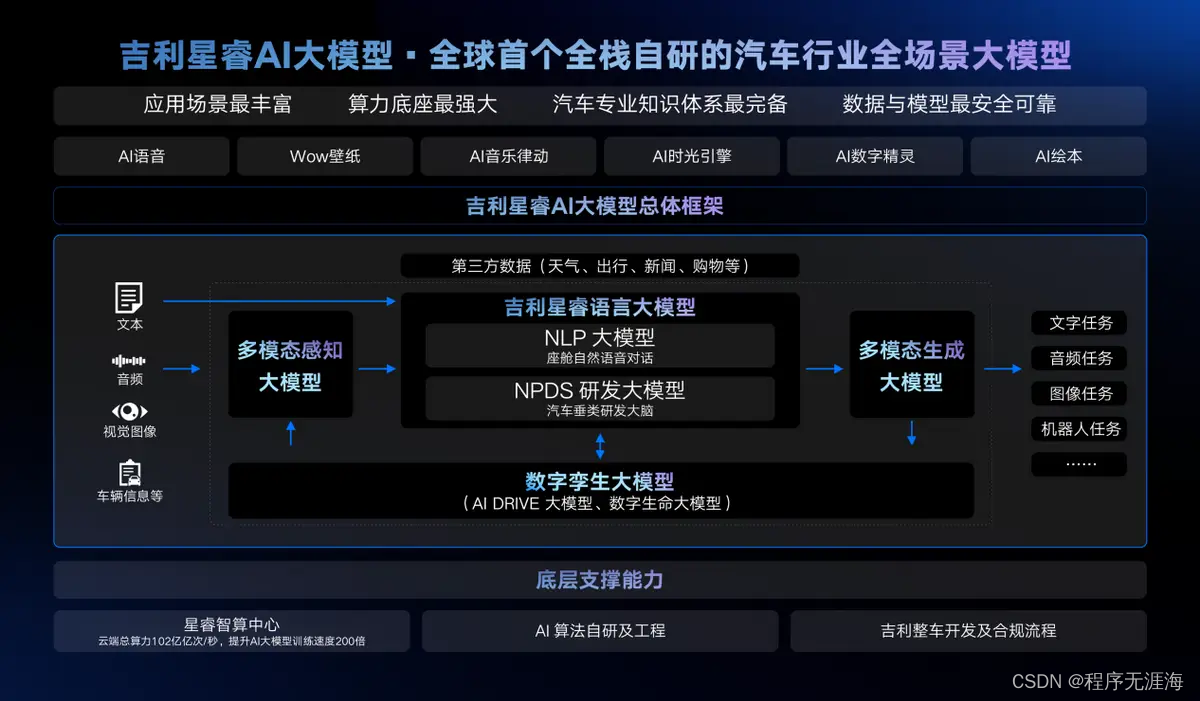
全球首个汽车行业全栈自研全场景AI大模型!吉利星睿AI大模型正式发布
https://www.sohu.com/a/751143992_121072032
吉利汽车集团CEO淦家阅在吉利银河E8上市发布会上,发布了AI大模型的相关能力及多款应用后,1月11日,吉利正式发布全球首个汽车行业全栈自研全场景AI大模型——吉利星睿AI大模型。
DeepLearningAI 新课程:使用 LangChain.js 构建 LLM 应用程序
https://x.com/DeepLearningAI/status/1745120890776441250?s=20
与 @LangChainAI : 使用 LangChain.js 构建 LLM 应用程序。
探索用于构建 LLM 的顶级 JavaScript 框架 LangChain.js,学习如何检索数据并将数据呈现给 LLM,以实现会话检索链等。
免费注册: https://hubs.la/Q02f-f7M0
fixkey.ai:用私人LLM解决语法问题
https://x.com/Karmedge/status/1745011856089960941?s=20
用私人LLM解决语法问题 @OLLAMA
我关闭了网络,触发了 fixkey,并使用本地 LLM [mistral 7B] 在一秒钟内修复了语法。
在 16GB 的 M1 和 M2 上完美运行
下周将在 http://fixkey.ai 上提供设置功能
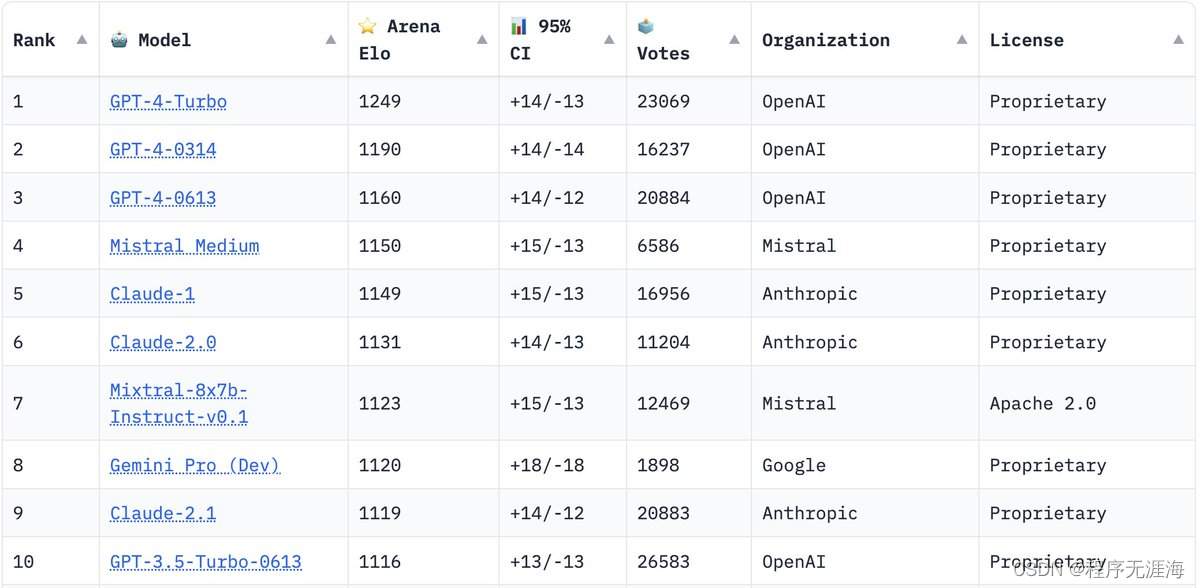
Mistral Medium在elo排行榜超越Claude,仅次于GPT-4
https://x.com/bindureddy/status/1745123316162310443?s=20
Mistral Medium 现在在 elo 排行榜上仅次于 GPT-4,而开源的 MoE 也不遑多让
我们在生产中使用 GPT-4 或开源 Mistral,但很快也将提供 Mistral Medium。
所有其他选项都是闭源的、非高性能的,甚至更糟的是,想要禁止开源 AI
理想情况下,不要使用它们 🙏 🙏
一种从人类反馈强化学习的 Minimax 方法

链接:http://arxiv.org/abs/2401.04056v1
我们提出了自我对弈偏好优化(SPO)算法,这是一种从人类反馈中进行强化学习的方法。我们的方法是极简主义的,因为它不需要训练奖励模型,也不需要不稳定的对抗训练,因此实现起来相当简单。我们的方法是极大主义的,因为它能处理非马尔可夫、不传递和随机偏好,并且对于困扰离线方法的复合误差具有鲁棒性。为了实现上述特点,我们建立在最小最大决胜者(MW)的概念上,这是社会选择理论文献中对偏好聚合的一种表述,将从偏好学习视为两个策略之间的零和游戏。通过利用该游戏的对称性,我们证明了与传统的竞争两个策略来计算MW的技术不同,我们可以简单地让一个智能体自我对弈,并且能够保证强收敛性。实际上,这对应于从一个策略中采样多个轨迹,要求评审员或偏好模型进行比较,并使用获胜比例作为特定轨迹的奖励。我们通过在一系列连续控制任务上的实验表明,相比于基于奖励模型的方法,我们能够更有效地学习,同时保持对不传递和随机偏好的鲁棒性,这在实践中在聚合人类判断时经常出现。
推理步长对大语言模型的影响

链接:http://arxiv.org/abs/2401.04925v1
“Chain of Thought(CoT)”对于改善大语言模型(LLMs)的推理能力具有重要意义。然而,CoT的效果与提示中推理步骤的长度之间的关联关系仍然很大程度上未知。为了揭示这一点,我们进行了几个实证实验来探索这些关系。具体而言,我们设计了一些实验来扩展和压缩CoT演示中的理由推理步骤,同时保持其他因素不变。我们得出了以下几个关键发现。首先,结果表明,在提示中延长推理步骤,即使没有向提示中添加新信息,也能显著提高LLMs在多个数据集上的推理能力。相反,缩短推理步骤,即使保留关键信息,也会显著降低模型的推理能力。这一发现凸显了CoT提示中步骤数量的重要性,并为在复杂问题解决场景中更好地利用LLMs的潜力提供了实际指导。其次,我们还研究了CoT的性能与演示中使用的理由之间的关系。令人惊讶的是,结果显示,即使是不正确的理由,如果它们保持必要的推理长度,也可能产生良好的结果。第三,我们观察到增加推理步骤的优势是任务相关的:简单任务需要较少的步骤,而复杂任务则大幅度受益于更长的推理序列。
视觉和语言编码器以相似方式表示世界吗?

链接:http://arxiv.org/abs/2401.05224v1
摘要:如CLIP这样的文本-图像编码器已成为视觉语言任务的事实标准模型。此外,特定于模态的编码器在各自的领域中取得了令人印象深刻的性能。这就引发了一个核心问题:由于它们基本上表示同一个物理世界,单模态视觉和语言编码器之间是否存在对齐?通过使用中心核对齐(CKA)在图像-标题基准上分析视觉和语言模型的潜在空间结构,我们发现未对齐和对齐编码器的表示空间在语义上是相似的。在像CLIP这样的对齐编码器中缺乏统计上的相似性的情况下,我们证明了可能存在一种不需要任何训练的未对齐编码器的匹配。我们将这视为一个基于图形的种子图匹配问题,并提出了两种方法-快速二次分配问题优化和基于新颖的局部CKA度量的匹配/检索。我们通过多个下游任务展示了这种方法的有效性,包括跨语言、跨领域的标题匹配和图像分类。
Potis AI
https://potis.ai/
Potis 是一个 AI 面试工具,帮助用人企业辅助进行行为面试,发现被面试者的潜能和优势,并对其与岗位的匹配度进行评估。
Fliz AI

https://fliz.ai/
Fliz是一个 AI 驱动的平台,让每个人都能轻松创建个性化的视频内容。用户只需通过简单的URL,即可使用Fliz制作产品推广、房地产广告、文章等各种视频故事。
Rabbit r1

https://www.rabbit.tech/
rabbit 创建了首款装有 rabbit OS 的移动设备,R1搭载了全新操作系统,Rabbit OS。Rabbit OS采用底层AI技术,基于“大型动作模型(Large Action Model,LAM)”在听到人类自然语言发出的指令后,Rabbit OS能理解人的复杂意图,然后帮人操作App完成任务。R1兼容现有的所有应用程序,用户无需抛弃已有的任何数据。
DeepSeekMoE
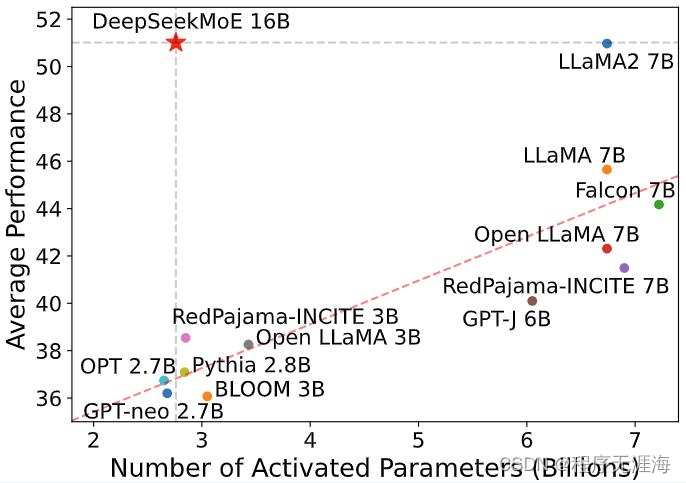
https://github.com/deepseek-ai/DeepSeek-MoE
DeepSeekMoE 16B 是一个具有 16.4B 参数的混合专家 (MoE) 语言模型。它采用了创新的 MoE 架构,该架构涉及两个主要策略:细粒度专家细分和共享专家隔离。它是在 2T tokens 从头开始训练的,并表现出与 DeekSeek 7B 和 LLaMA2 7B 相当的性能,只有大约 40% 的计算量。
SpeechAgents:使用多模态多智能体系统进行人机交流模拟
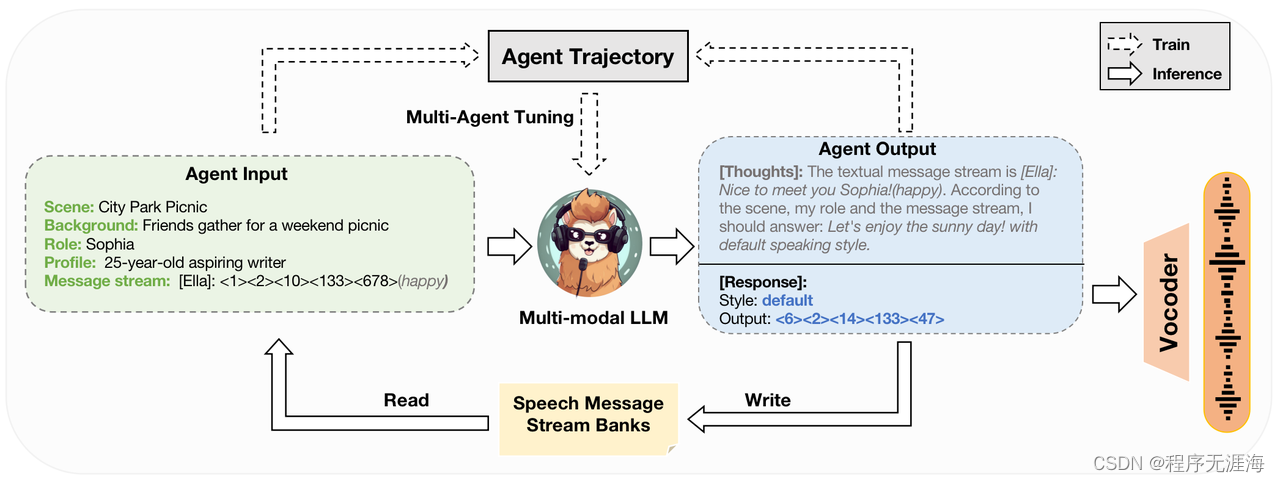
https://github.com/0nutation/speechagents
SpeechAgents 是一个基于多模态LLM的多智能体系统,专为模拟人类通信而设计。与目前LLM基于多智能体的多智能体系统不同,SpeechAgents利用多模态LLM作为单个智能体的中央控制,并使用多模态信号作为智能体之间交换消息的媒介。并且提出了多智能体调优,LLM以在不影响一般能力的情况下增强多智能体能力。为了加强和评估人类通信仿真的有效性,建立了人类通信仿真基准。
陶哲轩用AI证明数学猜想实乃误读,但数学界仍大受震
https://mp.weixin.qq.com/s/d9RSkRhlKH5ZMek3yTqe4Q
2023年,数学家陶哲轩与其他三位数学家合作,证明了加性组合学中的多项式Freiman-Ruzsa猜想,这是组合学领域的重大突破。陶哲轩随后使用Lean编程语言将证明形式化,这一过程在数学史上具有里程碑意义,因为它允许通过计算机验证证明的正确性。这一成就不仅展示了数学数字化的潜力,还可能改变数学期刊和学术交流的传统方式,推动数学研究和论文写作的未来发展
【模型量化系列1】float数据类型
https://zhuanlan.zhihu.com/p/676689081
模型量化是深度学习中的一种优化技术,通过降低模型权重和激活函数的数值精度来减小模型大小和加速推理速度。这一过程类似于简化语言交流,用基本词汇代替丰富词汇,以提高效率。量化的主要好处包括降低存储需求、提高推理速度和减少能耗,尤其适用于资源受限的设备。文章详细介绍了浮点数(如FP32)的表示方式,包括符号位、指数位和尾数位,以及它们如何决定数字的精度和范围。同时,文章讨论了半精度(FP16)和双精度(FP64)浮点数的特点。量化过程中可能出现的舍入误差和溢出错误在深度学习中尤为关键,因为它们可能影响模型的训练和推理。
Agent产品设计(1)|开篇:不破不立!用第一性原理解构这一切吧!
https://mp.weixin.qq.com/s/pbCg1KOXK63U9QY28yXpsw
本文是“Agent产品设计”系列的开篇,旨在探讨如何利用第一性原理来解构和设计智能体(Agent)产品。文章首先定义了Agent为能够通过传感器感知环境并通过执行器作用于环境的智能实体。随后,作者提出了“think thinking”方法论,即用思考去剖析思考本身,以辅助Agent产品设计。文章强调了技术、产品和价值之间的关系,并讨论了技术突破对产品和价值的影响。作者通过分析当前Agent系统的关键组成模块,提出了未来个体与Agent结合可能形成的“超级个体”概念,并探讨了企业如何从岗位级别引入Copilot智能体以适应这一变革。最后,文章预告了后续将深入探讨Agent产品设计的细节,以及如何实现Human based Agent和AI based Agent之间的有效交互。
这篇关于大模型日报-20240113的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









