本文主要是介绍第88讲:XtraBackup实现增量数据备份以及故障恢复的应用实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.XtraBackup增量备份恢复的概念
- 2.XBK增量备份语法
- 3.使用XBK实现数据库的增量备份
- 3.1.周日全量备份数据库
- 3.2.周一产生增量数据并进行增量备份
- 3.3.周二产生增量数据并进行增量备份
- 3.4.查看两次增量以及全量的备份文件
- 3.5.核对全量和增量备份的准确性
- 4.使用XBK通过增量备份还原数据库数据
- 4.1.使用XBK增量备份还原数据库的过程
- 4.2.XBK增量备份与全量备份合并时的重要参数
- 4.3.损坏数据库数据
- 4.4.整理全量备份数据
- 4.5.整理周一的增量备份并合并到全量备份中
- 4.6.整理周二的增量备份并合并到全量备份中
- 4.7.再次整理全量备份数据
- 4.8.通过全量备份还原被破坏的数据
1.XtraBackup增量备份恢复的概念
1)增量备份
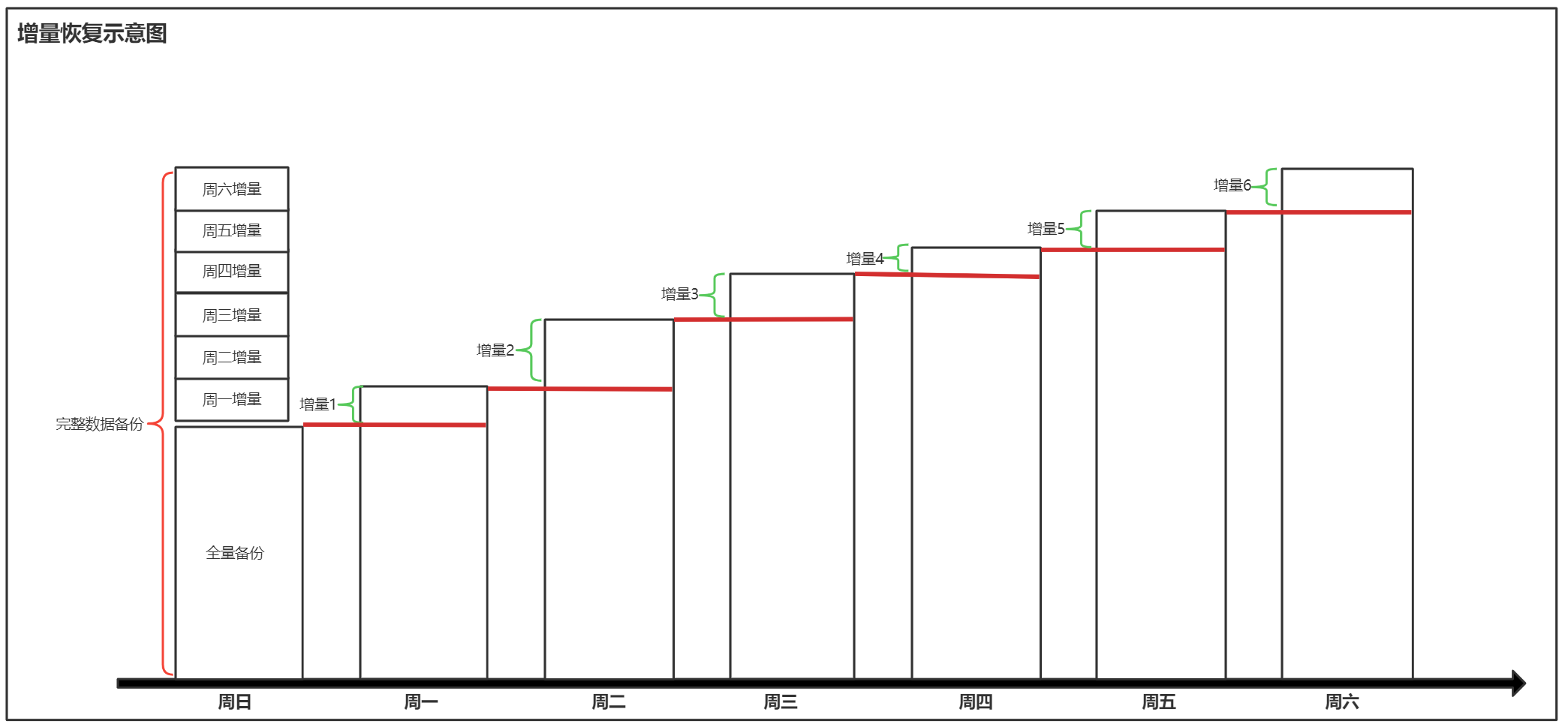
XBK增量备份的概念图如下,周日的时候进行全量备份,周一到周六进行增量备份,增量备份时并不是从全库备份处开始进行增量备份的,而是从前一天增量结束位置处,备份一天内的增量数据,相当于是基于上次的备份开始的增量备份。

2)增量恢复
XBK的使用增量恢复数据和其他的备份工具不用,但是比较有意思,XBK的增量备份不能单独恢复,需要将每日的增量数据与全量备份合并成一份完整的备份数据,然后进行还原。
2.XBK增量备份语法
XBK增量备份还是使用的innobackupex命令,其中有关于增量备份的参数:
--incremental:开启增量备份。
--incremental-basedir=xxx:指定上次备份的备份文件路径。
XBK增量备份案例:
innobackupex --user=root --password=123456 --no-timesteamp --incremental --incremental-basedir={上次备份的备份文件路径} {增量备份的备份文件路径}
3.使用XBK实现数据库的增量备份
首先对数据库进行一个全量备份(增量备份依赖于全量备份),然后模拟每天产生的增量数据,最后进行每天的增量数据备份。
创建全量备份和增量备份的备份路径
[root@mysql ~]# mkdir /data/dbbackup/all_db_bak
[root@mysql ~]# mkdir /data/dbbackup/inc_db_bak
3.1.周日全量备份数据库
[root@mysql ~]# innobackupex --user=root --password=123456 --no-timestamp /data/dbbackup/all_db_bak/all_bak_`date +%F`
3.2.周一产生增量数据并进行增量备份
1)模拟周一产生的增量数据
mysql> create table monday (id int,content varchar(10));mysql> insert into monday values (1,'haha'),(2,'heihei'),(3,'xixi');mysql> select * from monday;
+------+---------+
| id | content |
+------+---------+
| 1 | haha |
| 2 | heihei |
| 3 | xixi |
+------+---------+
2)对周一的增量数据进行增量备份
[root@mysql ~]# innobackupex --user=root --password=123456 --no-timestamp --incremental --incremental-basedir=/data/dbbackup/all_db_bak/all_bak_2022-07-03 /data/dbbackup/inc_db_bak/monday_inc_bak
3.3.周二产生增量数据并进行增量备份
1)模拟周二产生的增量数据
mysql> create table tuesday (id int,content varchar(10));mysql> insert into tuesday values (4,'k8s'),(5,'docker'),(6,'python');mysql> select * from tuesday;
+------+---------+
| id | content |
+------+---------+
| 4 | k8s |
| 5 | docker |
| 6 | python |
+------+---------+
2)对周二的增量数据进行增量备份
[root@mysql ~]# innobackupex --user=root --password=123456 --no-timestamp --incremental --incremental-basedir=/data/dbbackup/inc_db_bak/monday_inc_bak /data/dbbackup/inc_db_bak/tuesday_inc_bak
在企业生产环境中,增量备份和全量备份都会通过编写脚本的方式来时间,对于没有备份的文件都有时间戳,执行上一次备份文件也是通过变量来实现的,我这里没有按天备份,因此就使用固定的名称。
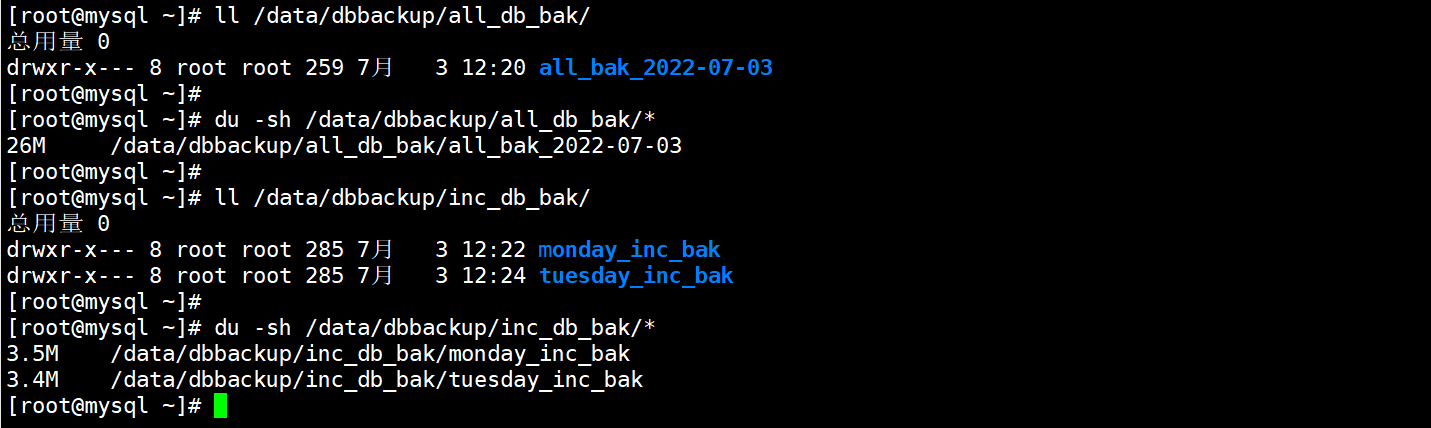
3.4.查看两次增量以及全量的备份文件
[root@mysql ~]# ll /data/dbbackup/
总用量 0
drwxr-xr-x 3 root root 32 7月 3 12:20 all_db_bak
drwxr-xr-x 4 root root 51 7月 3 12:24 inc_db_bak
[root@mysql ~]# ll /data/dbbackup/all_db_bak/
总用量 0
drwxr-x--- 8 root root 259 7月 3 12:20 all_bak_2022-07-03
[root@mysql ~]# ll /data/dbbackup/inc_db_bak/
总用量 0
drwxr-x--- 8 root root 285 7月 3 12:22 monday_inc_bak
drwxr-x--- 8 root root 285 7月 3 12:24 tuesday_inc_bak
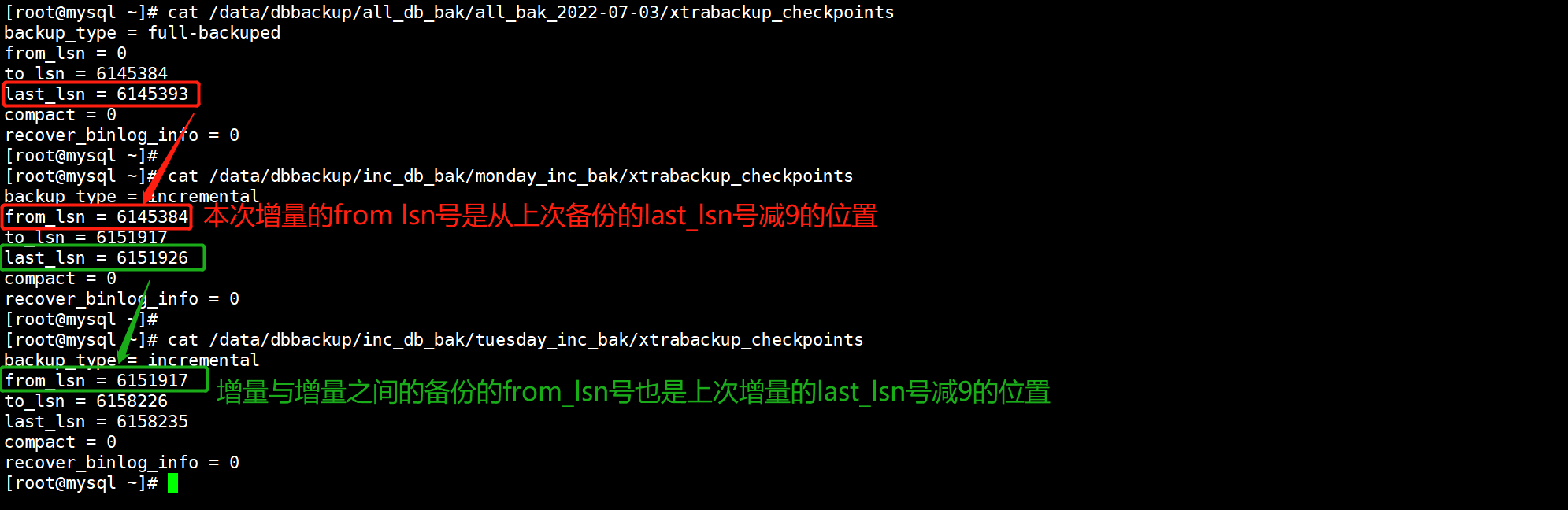
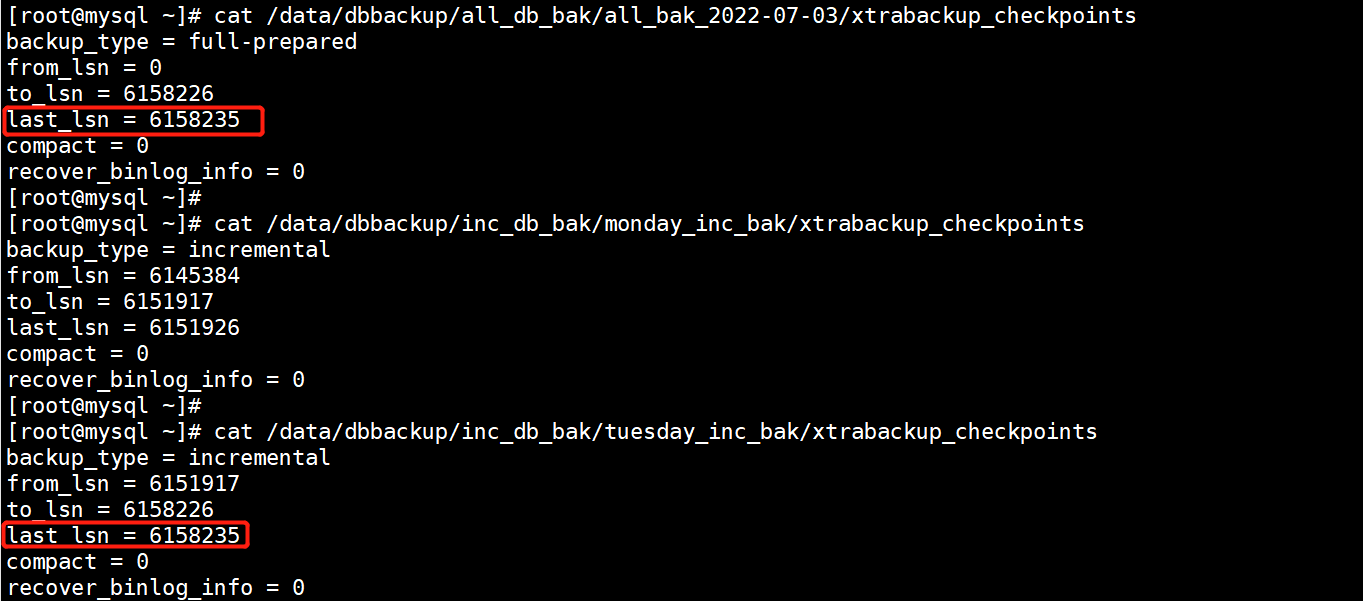
3.5.核对全量和增量备份的准确性
全量备份和增量备份已经完成了,下面我们来核对全量备份和增量备份的准确性。
我们核对时主要分析每个备份文件中的xtrabackup_checkpoints这个文件,观察相邻备份的last_lsn号和from_lsn号,当前增量备份的from_lsn号是上次备份的last_lsn号减9的位置号。
4.使用XBK通过增量备份还原数据库数据
4.1.使用XBK增量备份还原数据库的过程
在3小结中,数据库在周日的时候已经完成全量备份,以及在周一和周二都完成了增量备份,下面我们要模拟故障破坏数据库,然后通过XBK完成的全量备份以及增量备份去还原数据库的数据。
XBK的增量备份是不能直接还原的,需要先将多个增量备份合并到全量备份中,然后用全量备份去还原数据库的数据。
使用XBK增量备份还原数据库的过程:
- 1)首先整理全量备份数据,使用apply-log参数将全量备份数据进行整理,将备份时产生的“新的已提交事务的数据”通过备份redo log写入到备份文件中,将产生的“新的未提交事务的数据”通过备份的undo log回滚数据。
- 2)将周一的增量备份数据合并到全量备份数据中。
- 3)将周二的增量备份数据合并到全量备份数据中。
- 4)增量备份数据与全量备份数据全部合并后,然后再次整理全量备份数据。
- 5)最后通过全量备份数据还原被破坏掉的数据库即可。
4.2.XBK增量备份与全量备份合并时的重要参数
在XBK增量备份与全量备份合并时有几个的重要参数。
--apply-log:整理备份的数据,无论是全量备份还是增量备份,都需要先整理备份的数据,将备份过程中产生的“已提交事务的数据”通过redo log写入到备份文件中,将“未提交事务的数据”通过undo log回滚。
--redo-only:这个参数需要配合--apply-log这个参数一起使用,表示在整理备份数据时只执行redo前滚操作,不执行undo回滚操作。
意思就是说在整理数据时,只将备份过程中产生的“已提交事务的数据”通过redo log写入到备份文件中,对于“未提交事务的数据”不进行任何处理,此参数主要是为了防止在整理数据时,undo回滚会导致备份文件中记录的LSN号发生改变,从而影响备份合并。
这个参数只在特定的时机下使用:整理全备数据时使用、整理增量备份时使用、最后一个增量备份整理时不使用。
都是最后一次增量备份整理了,即使LSN号发生改变也没有任何影响。
整理备份数据、仅执行Redo前滚操作、合并增量到全量,这三步操作通常是一起执行的。
--incremental-dir=xxx:指定要将那个增量备份合并到全量备份中,指定增量备份的路径。
XBK增量备份合并全量备份的例子:
将/data/dbbackup/inc_db_bak/monday_inc_bak/这个增量备份合并到全量备份/data/dbbackup/all_db_bak/all_bak_2022-07-03/中innobackupex --apply-log --redo-only --incremental-dir=/data/dbbackup/inc_db_bak/monday_inc_bak /data/dbbackup/all_db_bak/all_bak_2022-07-03/
4.3.损坏数据库数据
直接将db_1、db_2、db_3的数据文件删除即可。此时数据库已经被损坏了,下面通过全量备份+增量备份还原数据库数据。
[root@mysql ~]# rm -rf /data/mysql/db_1/
[root@mysql ~]# rm -rf /data/mysql/db_2/
[root@mysql ~]# rm -rf /data/mysql/db_3/
4.4.整理全量备份数据
从这里开始正式进行增量备份数据还原。
[root@mysql ~]# innobackupex --apply-log --redo-only /data/dbbackup/all_db_bak/all_bak_2022-07-03/
4.5.整理周一的增量备份并合并到全量备份中
全量数据已经整理完毕了,下面将增量备份一个个的合并到全量备份中,首先将周一的增量备份合并到全量备份中。
[root@mysql ~]# innobackupex --apply-log --redo-only --incremental-dir=/data/dbbackup/inc_db_bak/monday_inc_bak /data/dbbackup/all_db_bak/all_bak_2022-07-03/
注意:全量备份整理和增量备份整理时都需要加上--redo-only参数,最后一次增量备份整理时除外。
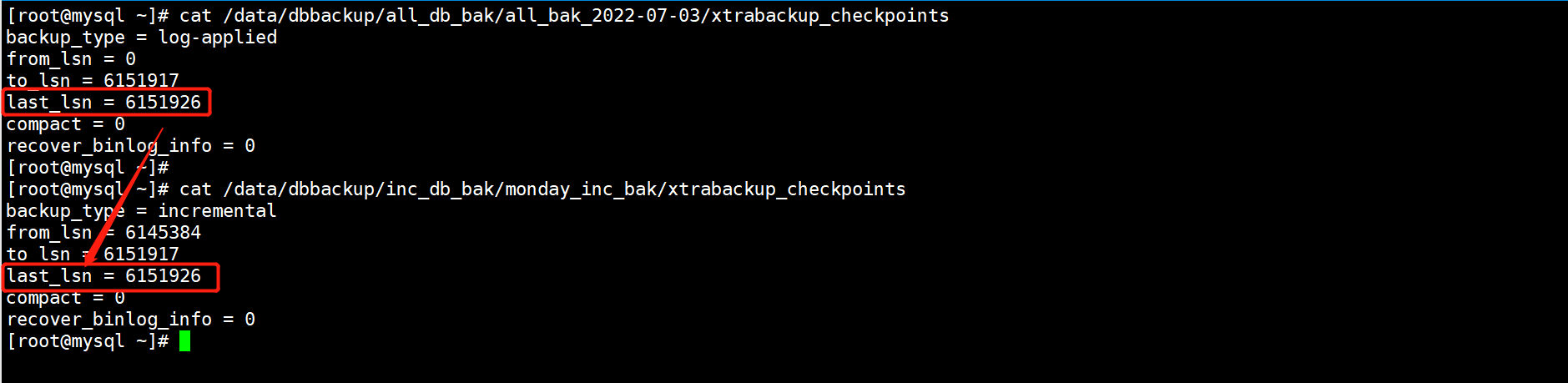
当周一的增量备份合并到全量备份之后,全量备份中的last_lsn号就发生了变化,lsn号已经记录到了周一增量备份的last_lsn号,此时就包含了周一增量的数据。
4.6.整理周二的增量备份并合并到全量备份中
下面将周二的增量备份整理,然后合并到全量备份中。
[root@mysql ~]# innobackupex --apply-log --incremental-dir=/data/dbbackup/inc_db_bak/tuesday_inc_bak /data/dbbackup/all_db_bak/all_bak_2022-07-03/
注意:周二的增量备份是最后一个增量备份了,此时不需要再加--redo-only参数。
当周二的增量备份与全量备份合并后,全量备份的last_lsn号再次发生变化,此时全量备份中已经包含了周一、周二的增量数据。
4.7.再次整理全量备份数据
增量备份和全量备份已经合并了,此时需要再次整理一下全量的备份数据。
[root@mysql ~]# innobackupex --apply-log /data/dbbackup/all_db_bak/all_bak_2022-07-03/
4.8.通过全量备份还原被破坏的数据
之前使用XBK备份还原都是直接拷贝的数据文件,下面我们通过XBK自带的还原工具来还原数据。
[root@mysql ~]# innobackupex --copy-back /data/dbbackup/all_db_bak/all_bak_2022-07-03/
[root@mysql ~]# chown -R mysql. /data/mysql/
[root@mysql ~]# systemctl restart mysqld
使用此方法还原数据时,要保证数据库的数据目录是空的,否则是无法还原的,如果不想覆盖掉数据目录的所有文件,那么还是通过cp进行还原。
[root@mysql ~]# \cp -ra /data/dbbackup/all_db_bak/all_bak_2022-07-03/db_1/* /data/mysql/db_1/
[root@mysql ~]# \cp -ra /data/dbbackup/all_db_bak/all_bak_2022-07-03/db_2/* /data/mysql/db_2/
[root@mysql ~]# \cp -ra /data/dbbackup/all_db_bak/all_bak_2022-07-03/db_3/* /data/mysql/db_3/
[root@mysql ~]# chown -R mysql. /data/mysql/
[root@mysql ~]# systemctl restart mysqld
数据还原成功,全备数据和增量数据都被恢复了。

这篇关于第88讲:XtraBackup实现增量数据备份以及故障恢复的应用实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





