本文主要是介绍mysql的数据存在linux的哪个目录——数据目录(有图有真相),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
mysql的存储引擎都是把表存储在磁盘上,而操作系统用文件系统管理磁盘。所以总而言之,存储引擎把表存储在文件系统上。
下面说下数据是如何在文件系统中存储的。
mysql服务器程序在启动时会到文件系统的某个目录下加载一些文件,在运行过程中也会把产生的数据存储到这个目录下的某些文件。
捋关系:操作系统用文件系统管理磁盘,mysql产生的数据存到文件系统的某个目录下的某个文件,而启动mysql的某些文件也存在这个目录下,这个目录就叫数据目录。
数据目录和安装目录的区别:
安装目录下有个重要的bin目录,它存储了许多控制客户端程序和服务器程序的命令(mysql,mysqld,mysqld_safe等等好几十个命令)。
而数据目录是用来存储mysql运行过程中产生的数据。两个不是一回事,一定要区分开,不是一个目录。
查看数据目录sql语句:
sql> show variables like 'datadir';


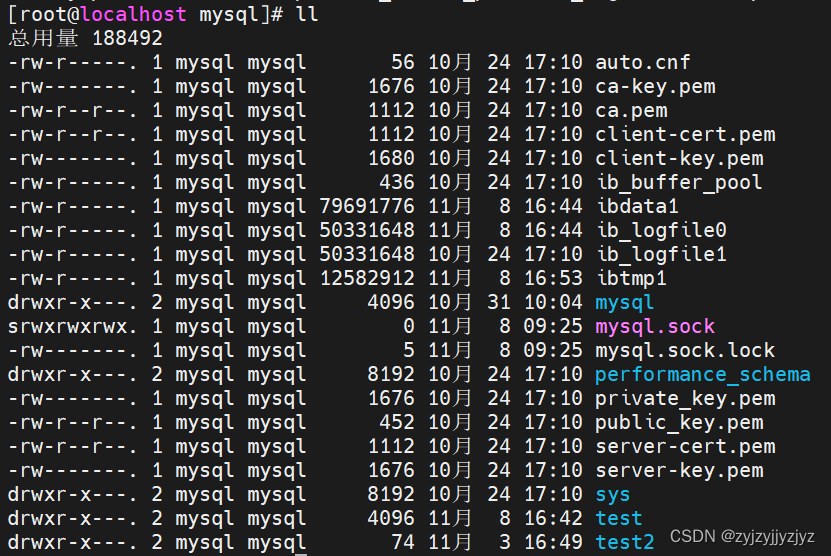
数据目录结构:
当我们create database 数据库名语句创建一个数据库的时候,在文件系统的数据目录下实际发生了什么?
每个数据库都对应数据目录下的一个子目录,或者说一个文件夹,每当创建一个数据库时,mysql会干两件事:
1)在数据目录下创建一个同数据库名的文件夹
2)在此文件夹下创建一个名为db.opt的文件,这个文件中包含该数据库的各种属性,比如数据库的字符集和比较规则等等。
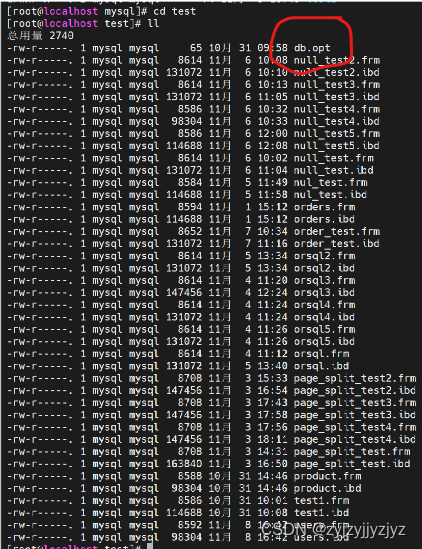
表在文件系统中的表示:
我们的数据其实都是以记录的形式插入到表中的,每个表的信息其实可以分为两种:
1)表结构的定义
表结构就是该表的名称,表里有多少列,每个列的数据类型,约束条件和索引,字符集和比较规则。这些信息都体现在建表的语句中。
为了保存表结构的信息,InnoDB和MyISAM都在数据目录下对应的数据库文件夹下创建了一个专门用于描述表结构的文件:表名.frm
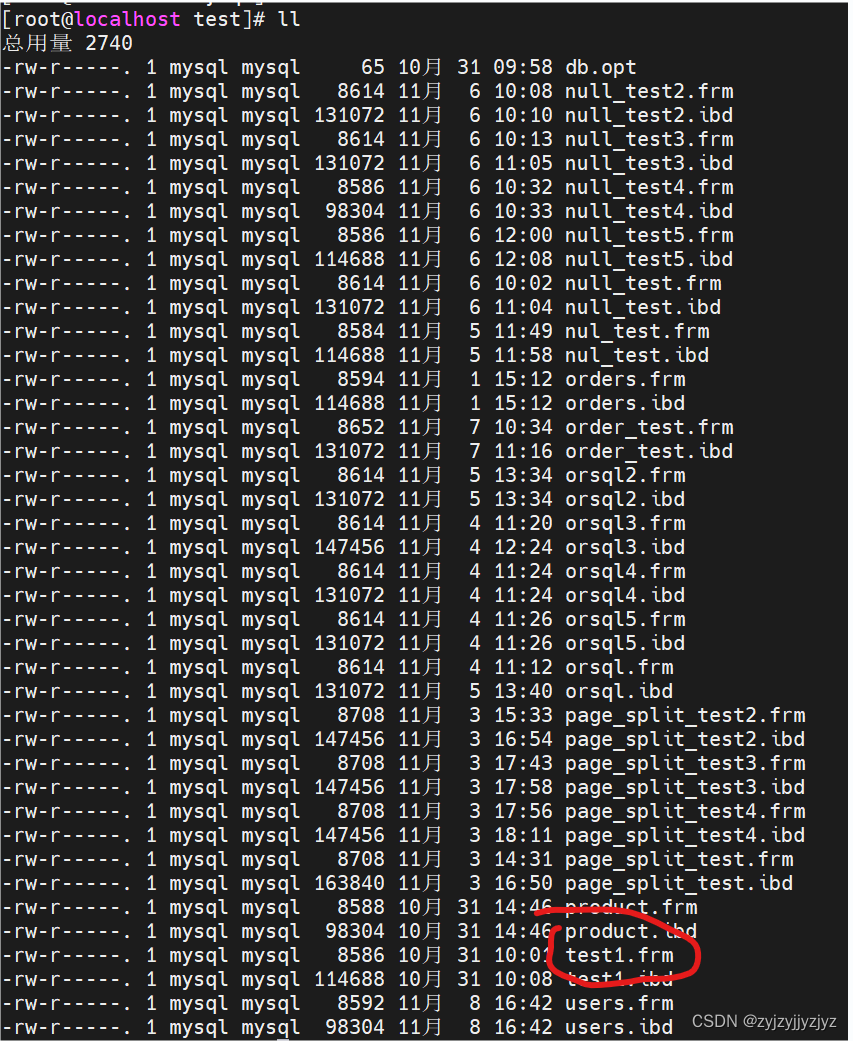
2)表中的数据
对于存储数据的文件不同存储引擎产生不通的文件。InnoDB、MyISAM在创建表时产生不同的文件-CSDN博客
下面换行继续聊。
InnoDB中如何存储表数据:
InnoDB设计这提出个概念:表空间
表空间是一个抽象的概念,它可以对应文件系统上一个或者多个真实文件。每个表空间可以被划分为很多页,我们的表数据就是存放在某个表空间下的某个页里。表空间划分为不同的类型。
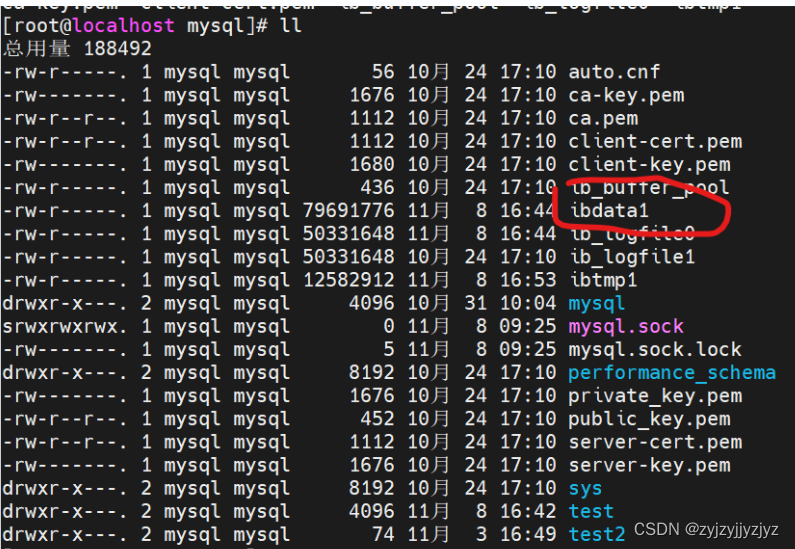
系统表空间:
这个所谓的系统表空间可以对应文件系统上一个或者多个实际文件,默认情况下,InnDB会在数据目录下创建一个名为ibdata1。这个文件就是系统表空间在文件系统上的表示。并且是子扩展文件,会自己增加文件大小。
独立表空间:
InnoDB不会默认把各个表的数据存储到系统表空间中,而是为每个表建立一个独立表空间,创建多少个表,就有多少独立表空间。使用独立表空间来存储表数据的话,会在数据库文件夹中创建一个独立表空间的文件,文件名和表明相同,后缀.ibd
我们可以指定使用系统表空间还是独立表空间来存储数据,默认存储独立表空间。
其他类型表空间:
undo表空间,临时表空间,后面的文章再介绍。
MyISAM中如何存储表数据:
和InnoDB中不同的是,MyISAM没有表空间一说,表数据都存储在对应的数据库子目录下。假设test表使用MyISAM存储引擎的话,在所在数据库文件夹下会为test表创建三个文件:
test.frm test.myd数据文件 test.myi索引文件
mysql的几个系统数据库介绍:

mysql:
这个数据库很核心,存储了mysql的用户账户和权限信息,⼀些存储过程、事件的定义信息,⼀些运行过程中产生的日志信息,一些帮助信息以及时区信息等。
information_schema:
这个数据库保存着MySQL服务器维护的所有其他数据库的信息,比如有哪些表、哪些视图、哪些触发器、哪些列、哪些索引。这些信息并不是真实的用户数据,而是⼀些描述性信息,有时候也称之为元数据。
performance_schema:
这个数据库里主要保存MySQL服务器运行过程中的⼀些状态信息,算是对MySQL服务器的⼀个性能监控。包括统计最近执行了哪些语句,在执行过程的每个阶段都花费了多长时间,内存的使用情况等等信息。
sys:
这个数据库主要是通过视图的形式把information_schema和performance_schema结合起来,让程序员可以更方便的了解MySQL服务器的⼀些性能信息。
这篇关于mysql的数据存在linux的哪个目录——数据目录(有图有真相)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






