本文主要是介绍用python将一份数据文件均等分拆,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
将一份数据文件,指定数据文件量来进行分拆,又或者指定分成指定的份数。
1.获取数据
file_path = 'D:\data\数据处理\拆分\汇总.xlsx'
data = pd.read_excel(file_path)

2.指定数据量进行拆分
# 按照每份数量进行拆分,例如指定每份为10条数据
def quantity_split(source_data, num):# 获取总共多少条数据count = len(source_data)# 需要进行遍历的次数,向上取整row = math.ceil(count/num)# 遍历生成数据文件for i in range(row):df1 = source_data[num * i: num * (i+1)]data_file_path = 'D:\data\数据处理\拆分\数量拆分\拆分后数据(数据量){}.xlsx'.format(i+1)df1.to_excel(data_file_path,index=None)
quantity_split(data, 10)
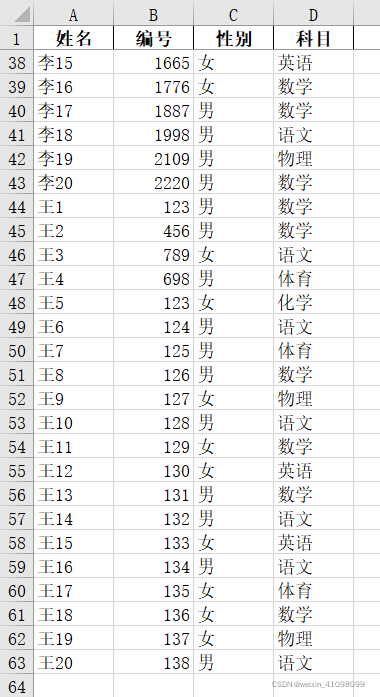
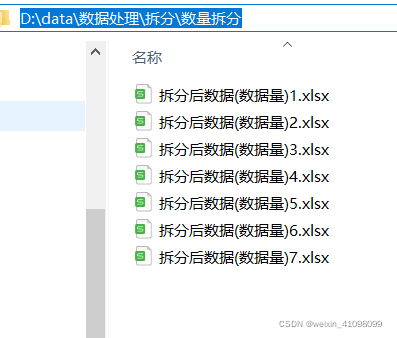
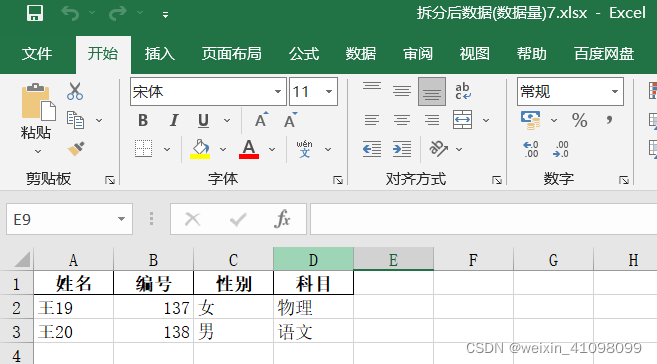
可以看出这里62条数据,前6份按照每份10条数据,最后一份2条数据进行拆分。
3.指定份数进行拆分
# 按照份进行拆分,例如指定分成3份
def copies_split(source_data, data_count):# 获取总共多少条数据count = len(source_data)# 获取每份的数据量num = math.ceil(count/data_count)for i in range(data_count):df1 = source_data[num * i: num * (i+1)]data_file_path = 'D:\data\数据处理\拆分\份数拆分\拆分后数据(份数){}.xlsx'.format(i+1)df1.to_excel(data_file_path,index=None)
copies_split(data, 3)
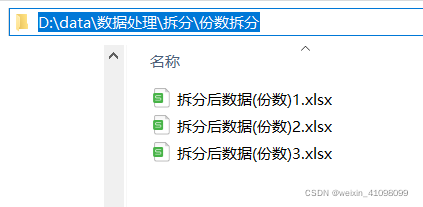
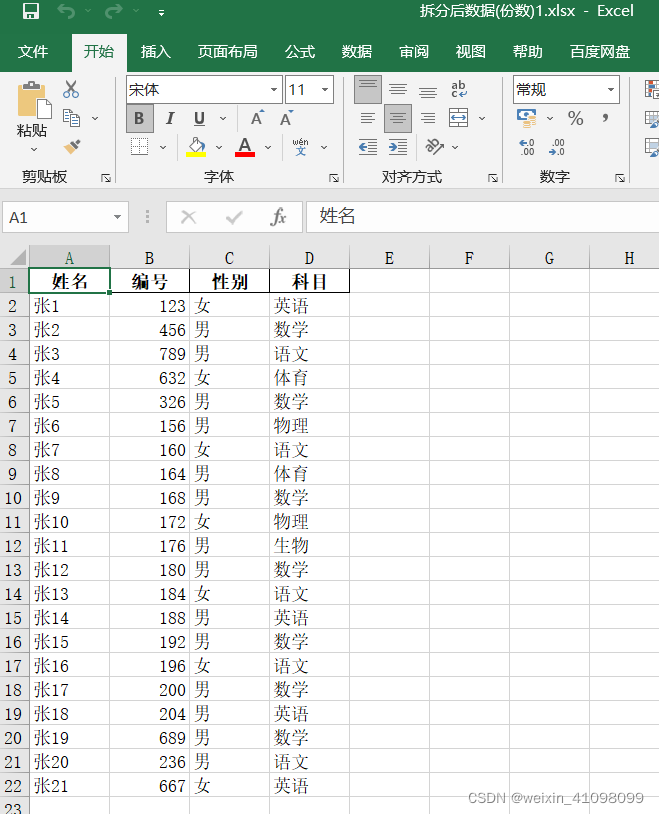
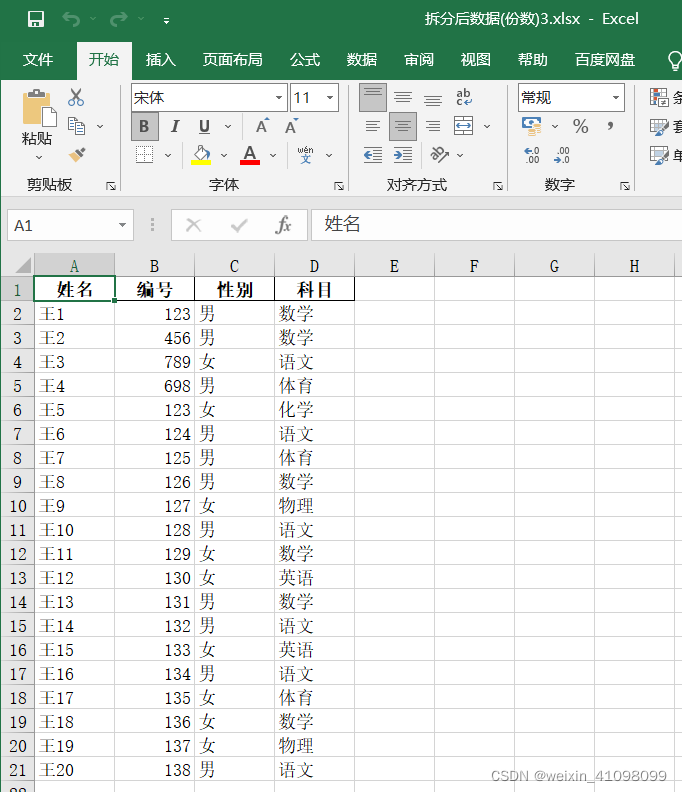
可以看出62条数据,拆分为3份,前两份每份数据为21条最后一份为20条进行拆分。
完整代码
import os
import pandas as pd
import mathfile_path = 'D:\data\数据处理\拆分\汇总.xlsx'
data = pd.read_excel(file_path)# 按照每份数量进行拆分,例如指定每份为10条数据
def quantity_split(source_data, num):# 获取总共多少条数据count = len(source_data)# 需要进行遍历的次数,向上取整row = math.ceil(count/num)# 遍历生成数据文件for i in range(row):df1 = source_data[num * i: num * (i+1)]data_file_path = 'D:\data\数据处理\拆分\数量拆分\拆分后数据(数据量){}.xlsx'.format(i+1)df1.to_excel(data_file_path,index=None)
quantity_split(data, 10)# 按照份进行拆分,例如指定分成3份
def copies_split(source_data, data_count):# 获取总共多少条数据count = len(source_data)# 获取每份的数据量num = math.ceil(count/data_count)for i in range(data_count):df1 = source_data[num * i: num * (i+1)]data_file_path = 'D:\data\数据处理\拆分\份数拆分\拆分后数据(份数){}.xlsx'.format(i+1)df1.to_excel(data_file_path,index=None)
copies_split(data, 3)
这篇关于用python将一份数据文件均等分拆的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







