本文主要是介绍尊嘟假嘟?三行代码提升接口性能600倍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、背景
业务在群里反馈编辑结算单时有些账单明细查不出来,但是新建结算单可以,我第一反应是去测试环境试试有没有该问题,结果发现没任何问题!!! 然后我登录生产环境编辑业务反馈有问题的结算单,发现查询接口直接504网关超时了,此时心里已经猜到是代码性能问题导致的,接来下就把重点放到排查接口超时的问题上了。
二、问题排查
遇到生产问题先查日志是基本操作,登录阿里云的日志平台,可以查到接口耗时竟然高达469245毫秒!
这个结算单关联的账单数量也就800多条,所以可以肯定这个接口存在性能问题。
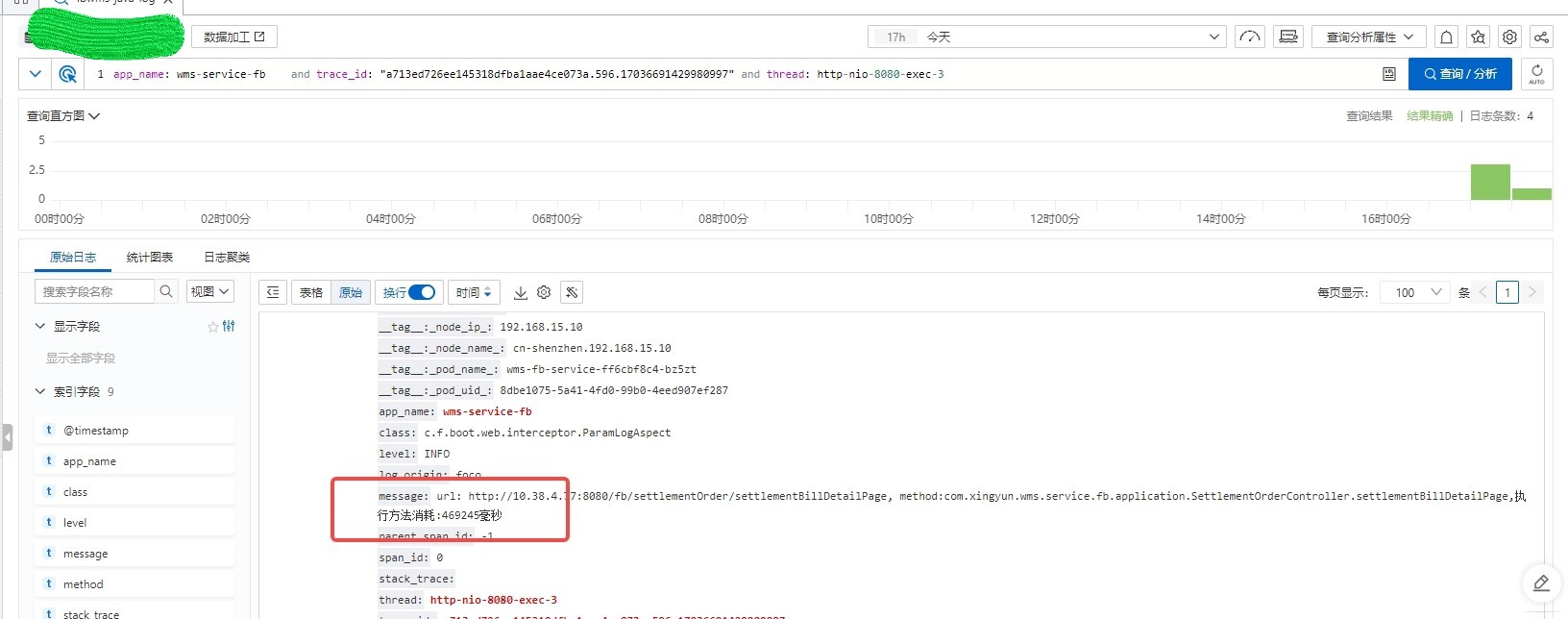
但是日志除了接口耗时,并没有其他报错信息或异常信息,看不出哪里导致了接口慢。
接口慢一般是由如下几个原因导致:
1. 依赖的外部系统慢,比如同步调用外部系统的接口耗时比较久
2. 处理的数据过多导致
3. sql性能有问题,存在慢sql
4. 有大循环存在循环处理的逻辑,如循环读取exel并处理
5. 网络问题或者依赖的中间件比较慢
6. 如果使用了锁,也可能由于长时间获取不到锁导致接口超时
当然也可以使用arthas的trace命令分析哪一块比较耗时。
由于安装arthas有点麻烦,就先猜测可能慢sql导致的,然后就登录阿里云RDS查看了慢sql监控日志。
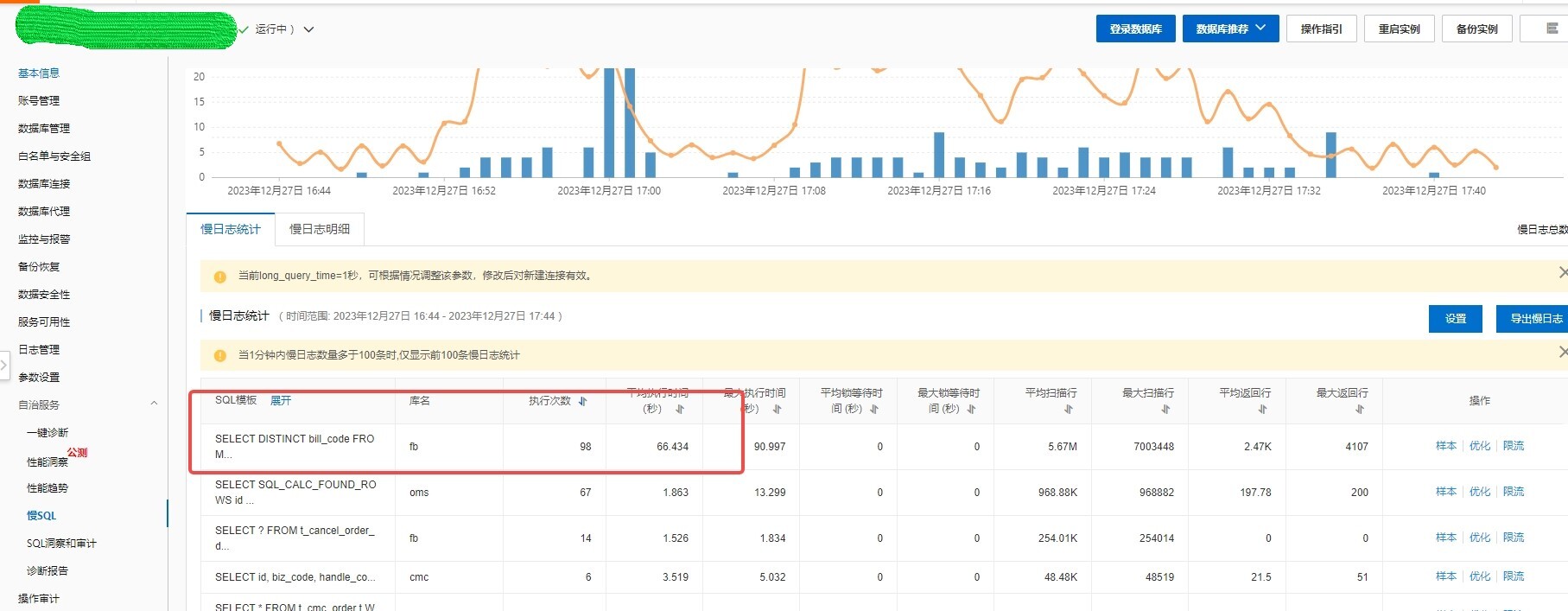
好家伙一看吓一跳,sql耗时竟然高达66秒,而且执行次数还挺多!
我赶紧把sql语句放到数据库用explain命令看下执行计划,分析这条sql为啥这么慢。
EXPLAIN SELECT DISTINCT(bill_code) FROM `t_bill_detail_2023_4` WHERE
(settlement_order_code IS NULL OR settlement_order_code = 'JS23122600000001');分析结果如下:

如果不知道explain结果每个字段的含义,可以看看这篇文章《长达1.7万字的explain关键字指南!》。
可以看到扫描行数达到了250多万行,ref已经是最高效的const,但是看最后的Extra列Using temporary 表明这个sql用到了临时表,顿时心里清楚什么原因了。
因为sql有个去重关键字DISTINCT,所以mysql在需要建临时表来完成查询结果集的去重操作,如果结果集数据量比较小没有超过buffer,就可以直接在内存中去重,这种效率也是比较高的。
但是如果结果集数据量很大,buffer存不下,那就需要借助磁盘完成去重了,我们都知道操作磁盘相比内存是非常慢的,时间差几个数量级。
虽然这个表里的settlement_order_code字段是有索引的,但是线上也有很多settlement_order_code为null的数据,这就导致查出来的结果集非常大,然后又用到临时表,所以sql耗时才这么久!
同时,这里也解释了为什么测试环境没有发现这个问题,因为测试环境的数据不多,直接在内存就完成去重了。
三、问题解决
知道了问题原因就很好解决了,首先根据SQL和接口地址很快就找到出现问题的代码是下图红框圈出来的地方

可以看到代码前面有个判断,只有当isThreeOrderQuery=true时才会执行这个查询,判断方法代码如下

然后因为这是个编辑场景,前端会把当前结算单号(usedSettlementOrderCode字段)传给后端,所以这个方法就返回了true。
同理,拼接出来的sql就带了条件(settlement_order_code IS NULL OR settlement_order_code = 'JS23122600000001')。
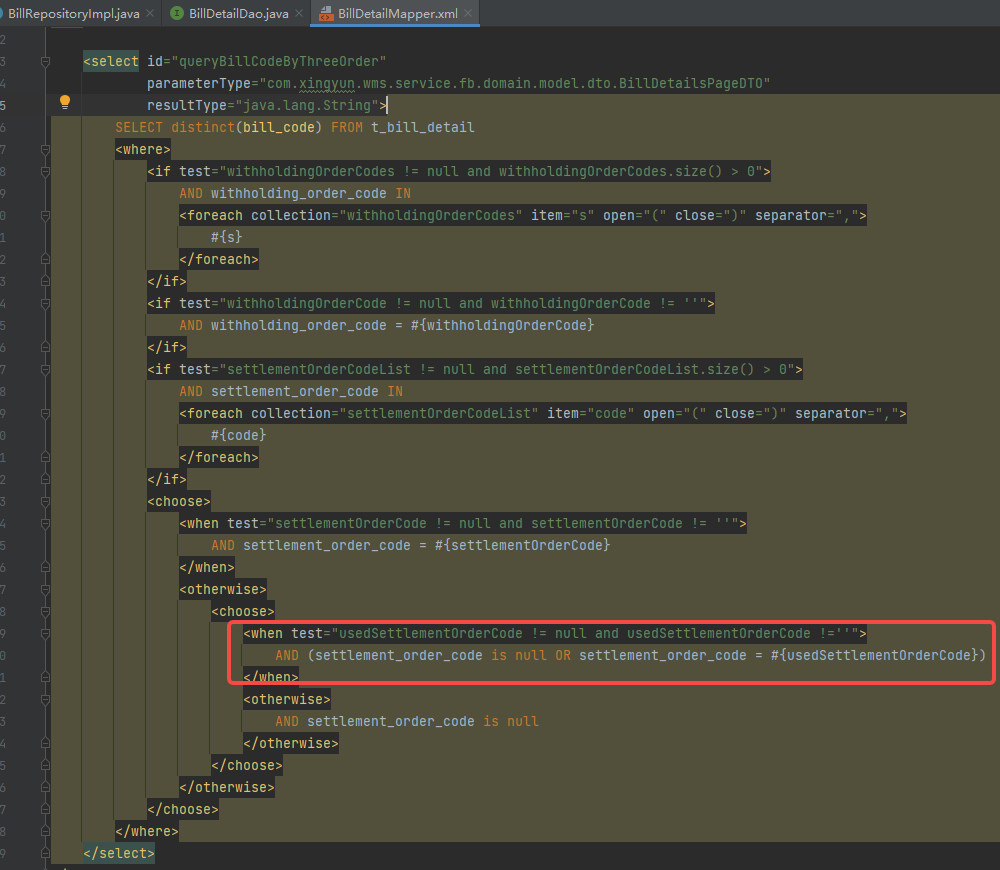
解决起来也很简单,把isThreeOrderQuery()方法圈出来的代码去掉就行了,这样就不会执行那个查询,同时也不会影响原有的代码逻辑,因为后面会根据筛选条件再查一次t_bill_detail表。
改代码发布后,再编辑结算单,优化后的效果如下图:
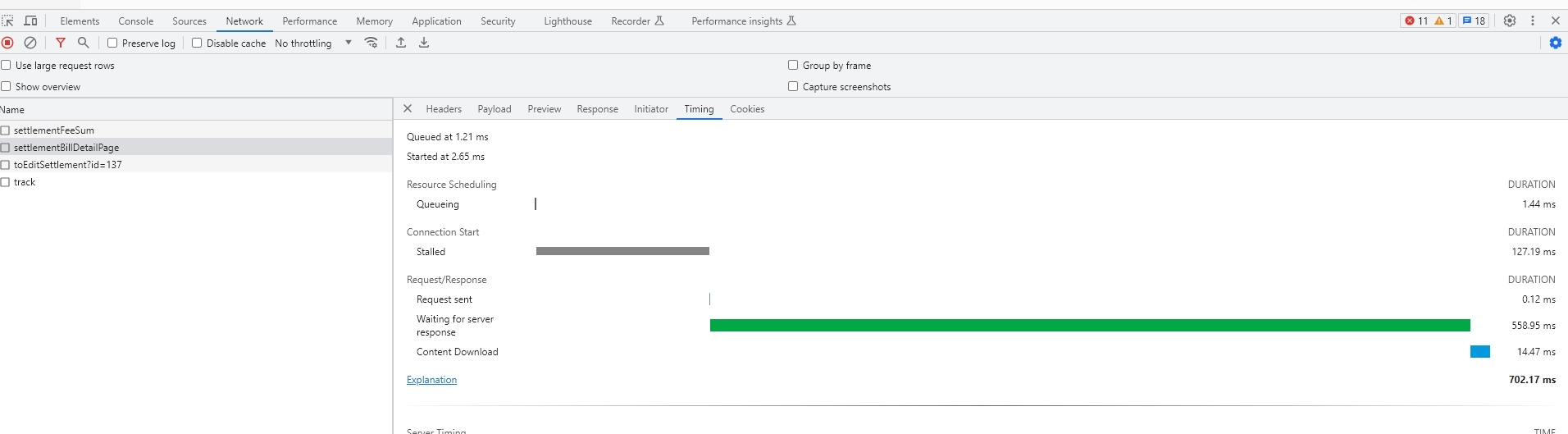
只改了三行代码,接口耗时就立马从469245ms缩短到700ms,性能提升了600多倍!
四、总结
感觉压测环境还是有必要的,有些问题数据量小了或者请求并发不够都没法暴露出来,同时以后写代码可以提前把sql在数据库explain下看看性能如何,毕竟能跑就行不是我们的追求😏。
文章转载自:烟味i
原文链接:https://www.cnblogs.com/2YSP/p/17955463
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构
这篇关于尊嘟假嘟?三行代码提升接口性能600倍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




