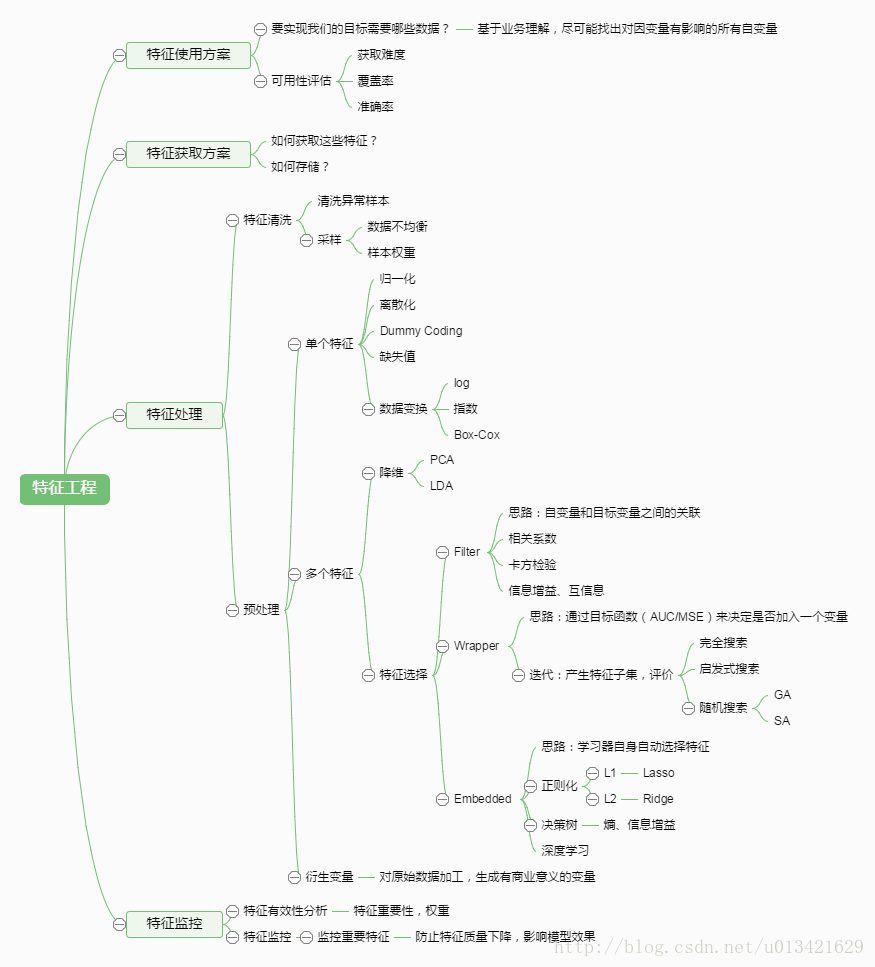
本文主要是介绍100-Days-Of-ML oneday,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这个博客是基于github上项目,Avik Jain致力于通过这个项目,让机器学习入门者学习机器学习的理论与实战,话不多说,现在开始:
https://github.com/Avik-Jain/100-Days-Of-ML-Code

注意:
1、pandas包生成的DF使用切片方式不同于python中的切片([:],包左不包右),DF.loc[0:3] 一共是四行
2、pandas中的df.concat()方法参数axis=0 和 axis=1,相当于sql中的union和join,他和fd.merge的区别
https://codeday.me/bug/20180824/225799.html
https://www.jb51.net/article/134615.htm pandas函数
pd.merge(df1, df2, on=‘col1’,
how=‘inner’,sort=True) 合并两个DataFrame,按照共有的某列做内连接(交集),outter为外连接(并集),结果排序
pd.merge(df1, df2, left_on=‘col1’,
right_on=‘col2’) df1 df2没有公共列名,所以合并需指定两边的参考列
pd.concat([sr1, sr2, sr3,…], axis=0) 多个Series堆叠成多行,结果仍然是一个Series
pd.concat([sr1, sr2, sr3,…], axis=1) 多个Series组合成多行多列,结果是一个DataFrame,索引取并集,没有交集的位置填入缺省值NaN
3、
一、导包
import nu
二、
准备数据:
Country,Age,Salary,Purchased
France,44,72000,No
Spain,27,48000,Yes
Germany,30,54000,No
Spain,38,61000,No
Germany,40,Yes
France,35,58000,Yes
Spain,52000,No
France,48,79000,Yes
Germany,50,83000,No
France,37,67000,Yes
Jupyter Notebook
ML100Day_1
最后检查: 8 分钟前
(自动保存)
Current Kernel Logo
Python 3
File
Edit
View
Insert
Cell
Kernel
Widgets
Help
实际代码:
import numpy as np
import pandas as pd
df = pd.read_csv(‘C:\Users\Administrator\Desktop\ml 100day\MLDayOneData.csv’)
print(df)
Country Age Salary Purchased
0 France 44.0 72000.0 No
1 Spain 27.0 48000.0 Yes
2 Germany 30.0 54000.0 No
3 Spain 38.0 61000.0 No
4 Germany 40.0 NaN Yes
5 France 35.0 58000.0 Yes
6 Spain NaN 52000.0 No
7 France 48.0 79000.0 Yes
8 Germany 50.0 83000.0 No
9 France 37.0 67000.0 Yes
#从qdf中取出x和y,并将他们转换成ndarray
x = df.iloc[ : ,:-1].values
print(type(df.iloc[ : ,3]))
print(type(x))
y = df.iloc[:,3].values
<class ‘pandas.core.series.Series’>
<class ‘numpy.ndarray’>
#处理空值
#首先创建异常值处理器对象
from sklearn.preprocessing import Imputer
imp = Imputer(missing_values = “NaN”,strategy = “mean”,axis = 0)
print(x)
[[‘France’ 44.0 72000.0]
[‘Spain’ 27.0 48000.0]
[‘Germany’ 30.0 54000.0]
[‘Spain’ 38.0 61000.0]
[‘Germany’ 40.0 nan]
[‘France’ 35.0 58000.0]
[‘Spain’ nan 52000.0]
[‘France’ 48.0 79000.0]
[‘Germany’ 50.0 83000.0]
[‘France’ 37.0 67000.0]]
C:\Users\Administrator\AppData\Roaming\Python\Python37\site-packages\sklearn\utils\deprecation.py:58: DeprecationWarning: Class Imputer is deprecated; Imputer was deprecated in version 0.20 and will be removed in 0.22. Import impute.SimpleImputer from sklearn instead.
warnings.warn(msg, category=DeprecationWarning)
#将有异常值的列进行处理(所有行,所有特征x)
imp = imp.fit(x[ : ,1:3])
print(imp)
print(type(imp))
Imputer(axis=0, copy=True, missing_values=‘NaN’, strategy=‘mean’, verbose=0)
<class ‘sklearn.preprocessing.imputation.Imputer’>
x[ : , 1:3] = imp.transform(x[ : ,1:3])
print(x)
[[‘France’ 44.0 72000.0]
[‘Spain’ 27.0 48000.0]
[‘Germany’ 30.0 54000.0]
[‘Spain’ 38.0 61000.0]
[‘Germany’ 40.0 63777.77777777778]
[‘France’ 35.0 58000.0]
[‘Spain’ 38.77777777777778 52000.0]
[‘France’ 48.0 79000.0]
[‘Germany’ 50.0 83000.0]
[‘France’ 37.0 67000.0]]
#比如处理y值,y值可能是好坏,矩阵中需要数值型,我们通过encode categorical data,将y转换成y值
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
#创建标签编码器对象
le_x = LabelEncoder()
print(x[ : , 0])
[‘France’ ‘Spain’ ‘Germany’ ‘Spain’ ‘Germany’ ‘France’ ‘Spain’ ‘France’
‘Germany’ ‘France’]
x[ : , 0] = le_x.fit_transform(x[ : , 0])
#fit_transform是fit和transform的简写,fit的作用简单来说,就是求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性
#transform的简写是利用这些fit出来的结果进行转换
print(x[ : , 0])
[0 2 1 2 1 0 2 0 1 0]
print(x)
[[0 44.0 72000.0]
[2 27.0 48000.0]
[1 30.0 54000.0]
[2 38.0 61000.0]
[1 40.0 63777.77777777778]
[0 35.0 58000.0]
[2 38.77777777777778 52000.0]
[0 48.0 79000.0]
[1 50.0 83000.0]
[0 37.0 67000.0]]
#现在将变量转成了数字类型,现在就要使用虚拟变量哑变量(Dummy variable)将数据归一化,
… https://www.cnblogs.com/king-lps/p/7846414.html
拿到获取的原始特征,必须对每一特征分别进行归一化,比如,特征A的取值范围是[-1000,1000],特征B的取值范围是[-1,1].如果使用logistic回归,w1x1+w2x2,因为x1的取值太大了,所以x2基本起不了作用。所以,必须进行特征的归一化,每个特征都单独进行归一化。
对于连续性特征:
Rescale bounded continuous features: All continuous input that are bounded, rescale them to [-1, 1] through x = (2x - max - min)/(max - min). 线性放缩到[-1,1]
Standardize all continuous features: All continuous input should be standardized and by this I mean, for every continuous feature, compute its mean (u) and standard deviation (s) and do x = (x - u)/s. 放缩到均值为0,方差为1
对于离散性特征:
Binarize categorical/discrete features: 对于离散的特征基本就是按照one-hot(独热)编码,该离散特征有多少取值,就用多少维来表示该特征。
##独热变量的优缺点:优点:one-hot变量解决了分类器不好处理属性数据的问题,她在一定程度上起到了 扩充特征 的作用,他的值只有0和1,不同类型存储在垂直的空间
#缺点:当类别很多时,特征空间会变得特别大,这种情况下,一般可以用 PCA 来减少维度。而且 one-hot encoding+PCA 这种组合在实际中也非常有用
#什么情况下用(不用)独热编码?
#用 独热编码用来解决类别型数据的离散值问题
#不用: 将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码。 有些基于树的算法在处理变量时,并不是基于向量空间度量,数值只是个类别符号,即没有偏序关系,所以不用进行独热编码。 Tree Model不太需要one-hot编码: 对于决策树来说,one-hot的本质是增加树的深度。
什么情况下(不)需要归一化? 需要:基于参数模型或者基于距离的模型,都是需要进行特征的归一化
不需要:基于树的方法是不许用进行特征的归一化的,例如随机森林、bagging、BOOSTING等
#哑变量与One-hot编码的区别在于:哑变量将定性特征转化为n-1个特征,而One-hot则是转化为n个特征。意思就是哑变量在编码时会去除第一个状态,而One-hot则对所有的状态都会进行编码。
#创建独热编码器对象
oneHotEncode= OneHotEncoder(categorical_features = [0])
print(oneHotEncode)
OneHotEncoder(categorical_features=[0], categories=None,
dtype=<class ‘numpy.float64’>, handle_unknown=‘error’,
n_values=None, sparse=True)
x = oneHotEncode.fit_transform(x).toarray()
print(type(x))
<class ‘numpy.ndarray’>
x
array([[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.40000000e+01,
7.20000000e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 2.70000000e+01,
4.80000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 3.00000000e+01,
5.40000000e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.80000000e+01,
6.10000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.00000000e+01,
6.37777778e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 3.50000000e+01,
5.80000000e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.87777778e+01,
5.20000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.80000000e+01,
7.90000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 5.00000000e+01,
8.30000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 3.70000000e+01,
6.70000000e+04]])
这篇关于100-Days-Of-ML oneday的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!