本文主要是介绍【得物技术】基于自注意机制的图像识别算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
对于做 CV 同学的人来说,图像识别是入门中最简单的模型,也是最最基础的模型。在不同的 CV 任务重,即使发展多年,都一直保留着利用训练好的图像识别任务重的模型权重,作为 backbone 用于加速训练收敛的作用。但是面对一些图像识别的任务,我们如何根据业务需求去改造一个已经比较完备的识别任务,还是蛮有意思的一个话题。
业务需求
能够筛选出用户上传的球鞋图片中带有干净统一背景的图片,我们暂且就叫这个项目为 背景复杂度检测 任务。帮助后续估价以及出售环节算法降低难度,以及维持整个 app 图像质量在一个水平线上。

项目要求
- 能够在测试集的准确率达到 80% 以上,可以用于给予用户提示,但是并不强制;而达到 90% 以上,可以强制用户按照要求达到上传图片质量的要求。
- 能够实现端侧应用。
模型设计
mobilenet backbone + FPN + modified SAM

最终做出来的模型各个模块分解来看其实很简单,没有什么特别难懂的地方。
整体需要努力的方向无外乎以下几点:
- 分析业务特点,这是一个典型的空间型识别任务,即是通过图像的某部分或者某几部分区域的内容完成目的。对于 背景复杂度 我们要刨去主体之外的部分,判断剩余部分是否是“复杂的”,即可,所以想到可以用空间系列的注意力机制。
- 我们不可能对于用户严格控制拍照中的主体占据图片中比例的大小。有些用户习惯将主体占满屏,有些用户喜欢留白多一些。对于不同的尺度,如果想做到精细分类,是需要在较高分辨率下的 feature map 做文章,所以这里用 FPN。
- 为了能够在端侧实现应用,选用 mobilenet 系列是很天然的想法。
以上几点的设计思路其实就是完全围绕当前 业务场景 而去做出的设计。
最终在测试集上,利用设计好的 CNN 模型达到了 96% 的正确率。可以作为强制用户上传高品质图片质量的依据。
如果想了解(白嫖)这个项目所用模型,其实分享到这就可以达到目标了。每一个模块的设计,其实都不难,没有新的概念。代码也很简明,实现也很方便。
但项目本身最有趣的实际上是实现整个项目的思想,为什么最后选用这样的模型,中间其他的思路是如何被排除,如何试错的!!!
项目过程
传统 CV
项目需要在端侧实现,虽然没有明确手机实时性的要求,但是需要整个算法文件,所引用的 库 占据内存足够的小。第一能够想到的就是如果不用深度网络,这个问题是否能够解决。
错误的思路
分析 背景复杂度,我曾想到用
- 对于和整个业务无关但是又严重影响结果的主体内容,用一个固定大小的高斯核进行过滤,然后进行其他处理。
- 利用边缘检测、梯度信息分析一张图片的背景复杂度
- 傅里叶频率信息分析图片的高低频信息来判断:高频代表背景信息多,较为复杂;低频代表干净。
- 通过多张背景干净的图片做简单像素加权平均当做模板,然后利用异常检测的方法,筛选出背景复杂的图片。
以上都是在项目初期,我能想到的一些简单的 idea。但是观察图片样本后,这些想法,除去第一条的思路是对的(空间维度的信息),其他三条的思路都是错的。举个例子,一双鞋放在地毯上,地毯本身是干净的,图片也除去主体和地毯没有其他任何物体。但是地毯有自己的纹路,高频信息很多,梯度信息很多。按照上述 idea 2、3、4 条的原则,这样的背景属于复杂度很高的背景。但是实际上,在样本中,这样的背景算是干净的。
通过分析数据的样本以及反思业务逻辑得出以下结论:
- 背景复杂度概念不是针对不同图片之间背景的差异。
- 背景复杂度的概念是针对每张图片自身是否出现了不同的背景和不是主体的一些前景物体。
那么,整体的思路就要做出一些改变,就是要通过 自相似度 的方式来判断背景复杂度。这也是对于业务越来越熟悉之后做出策略上的调整。
模板匹配
那么需要用到哪些部分可以用于自相似度的判断呢?
- 四个角
上面说过,错误的 idea 中,有一个思路是对的,就是要利用空间维度去思考业务,去掉主体信息思路是对的。即我们在判断背景自相似度的情况,是需要避免划到主体信息的。根据这个思路,我们可根据经验,4 个角可以在一定程度上可以代表一张图的背景信息。如果 4 个角上的内容相似,可以解决大部分业务的目标。利用 4 个角的信息计算两两自相似度,有 6 个值。6 个值越高,说明 4 个角的相似度越高,是干净背景的概率也就越大。

- 两个角
通过观察实际的 业务 样本后发现,用户拍照的习惯往往是上面的留白会比下面的多。也就是说,下方的 2 个角经常会含有主体信息。所以最终确认的方案就是只利用 上方的 2 个角进行相似度匹配。
- 还没完
但是,只利用 2 个角的相似度匹配只有 1 个值的输出,那这样的值对于整个业务来说,太不稳定了,存在很大的风险。于是我分别利用上方两个角自己作为模板,然后分别去做滑窗做匹配,记录大于一定阈值的个数,作为一个相似度评价的一个指标。所以,最终有 3 个指标来衡量一张图背景的相似度情况。一个是上方两个角彼此的相似度值。另外两个是每一个角,独自作为模板,与整幅图上其他空间上内容能够匹配的个数。根据预设定好的权重,进行加权,最终得到一个分数。这个分数用来判断最后这幅图是否是背景复杂。

最终,通过这种方法,输入图片进行统一的 resize,保持图像在一定大小,让模板匹配速度控制在合理的范围内,根据以上的做法,在测试机就可以达到 80% 的正确率。这个算法可以在产品端作为引导晕乎拍照的工具。当算法判断为复杂背景时,给予提示希望用户重新拍照。
CNN
以上传统 CV 没有听懂,没有关系。它只是叙述下整个项目利用业务分析,得到一些宝贵思路的过程。下面的方式才是此文章的重点。
baseline
为了项目快速迭代优化,选用识别的思路做这个项目。也就是很普通的图像识别任务。由于希望能够放在手机里的模型,自己能够想到也比较熟悉的是 mobilenet v1。
优化模型
目标检测
在文章开始的时候,我提到过,这是一个标准的空间行识别问题。对于这样的识别问题,我通常的做法就是利用 检测模型 解决识别任务。
这种思路很常见。比如在社区中,我们想识别一个图文帖子中,图中达人他的穿搭是什么样的,有没有背什么牌子的包包,穿了什么品牌的鞋。不考虑实际算法难度,端对端的思路就是一个识别问题。输入一张图,输出几个标签。但是实际上,直接利用识别模型是很难的,因为有很多冗余背景的信息。我们面对这样的问题还是需要利用检测模型去做。最后只是不需要输出 bounding box 就好,可能还需要做一些去重的策略上的工作。

回到本业务,有一点不同的是,我们最终关心的区域恰恰是去除主体的区域。在 传统 CV 中有一个思路就是用一个固定大小的高斯核去做这样类似的事情。但是恰恰是因为这一点,我们不能像上文社区那样的例子利用一个目标检测模型加上一些策略就直接拿到输出。
首先需要一个目标检测模型拿到主体。然后用 mask 过滤的方案,接上传统 CV 算法也好,CNN 的 baseline 也罢,就可以得到最终的答案。
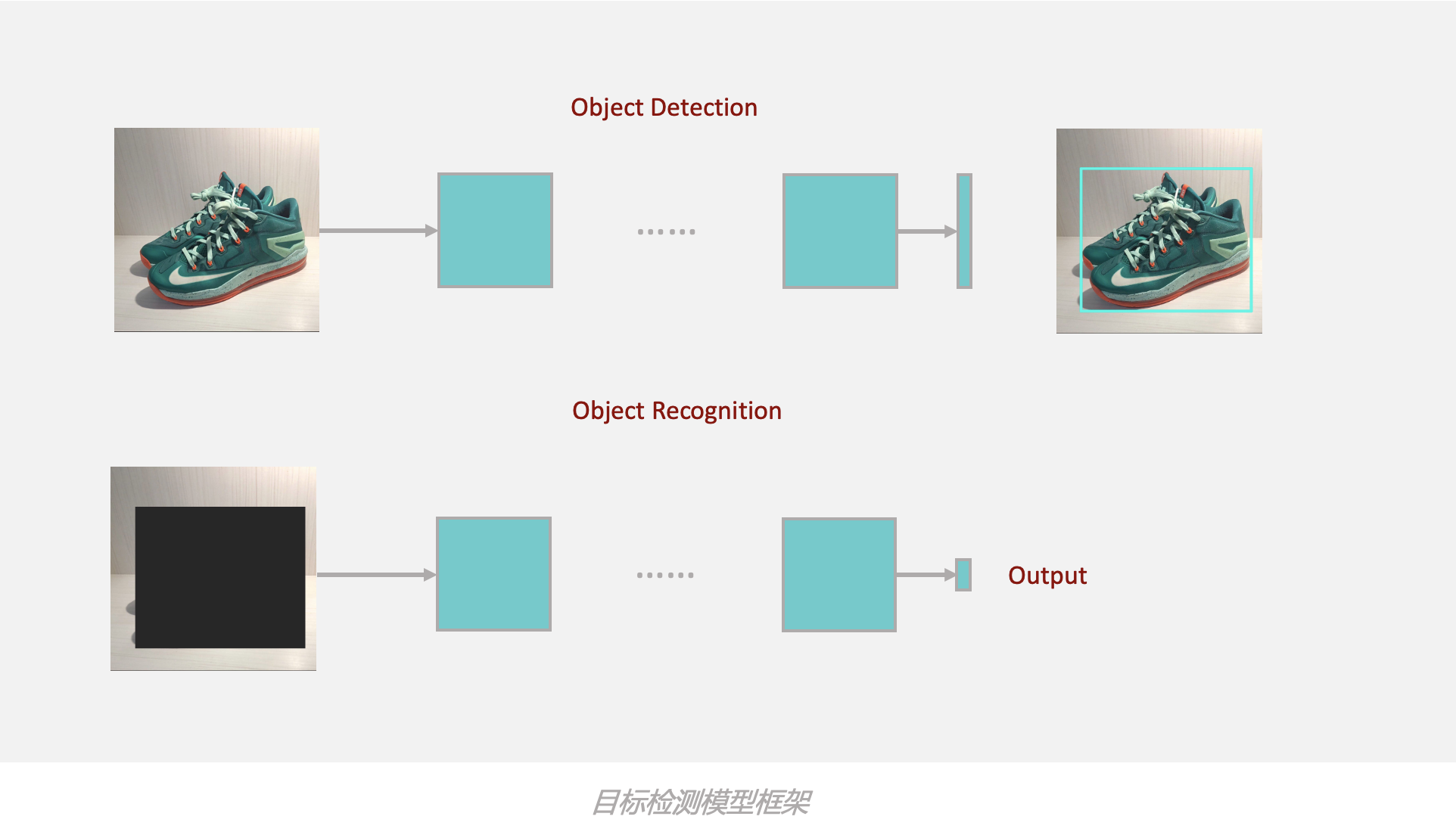
利用目标检测的方法,是可以很明晰地解决这样的一个业务问题,也是最直观的选择。
隐性目标检测
目标检测的方法虽然直观,但是存在两个巨大的缺陷:
- 不能够端对端,至少需要两个步骤,或者两个模型,对于速度,和内存空间来说都是一个负担。
- 目标检测需要标签的成本也比识别的成本大的多。
那么,是否我们可以优化掉上述的这两个缺陷呢?答案是肯定的。
我们可以像目标检测的步骤那样,在中间的模型的过程中,预测一个区域,就是一个 bounding box。输出也就是 4 个维度。通常是可以输出 左上角、右下角;左上角、宽高;或者中心坐标、宽高。然后利用原图像和这 4 个维度的结果做一个 mask 过滤,过滤掉主体,再进行下一步的识别作用。
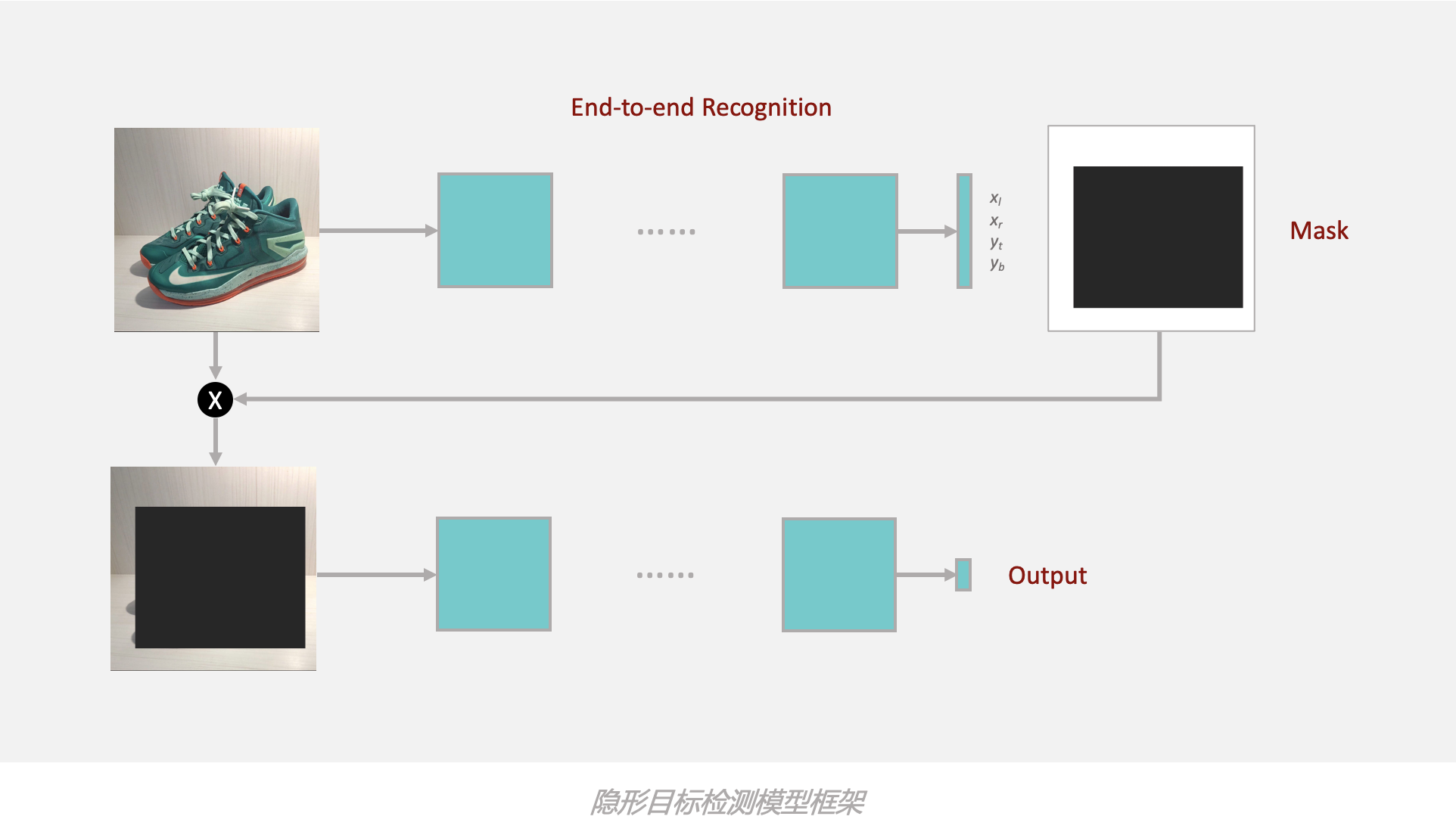
这样做的好处就可以避免直接用 目标检测 任务所有的缺陷。他把上一种方案分步做合并成一个模型。中间标签也是自己学出来的而不是人工标出来的,省去很多训练之前的准备工作时间。
其实著名的 拍立淘 的图搜算法就是利用了这样的思路进行图搜识别的。一般的图搜也是分为 目标检测 + 识别的方法,但是 拍立淘的方案利用上述这种方法去除了目标检测的前置任务。
隐性分割
既然目标检测可以,那么其实语义分割,或者实例分割也可以做这样的内容。我们看看隐性目标检测也有这个他的局限性:
- 由于 bounding box 本身的问题,他依然囊括了一些或者去除了一些必要信息。
- 对于多个物体的话,这种方式就很不灵活。(当然这个问题不是不可以解决。也可以用到目标检测设计一些卷积得到 feature map 的方式解决多目标检测的问题,但是那样参数量也会上升。)
同样,我们利用典型的分割思路,在 mask 生成的阶段,抛弃 bounding box 这种规整的形状,去省城一个物体的外轮廓边界。这个边界同样也是隐性的,是不需要人工标注的,然后用输入图像去过滤这个mask。
空间注意力机制
隐性分割固然很有道理,但是实际上参数量会上升,计算量会加大。其实无论是目标检测还是分割的方法,其实从广义上讲就是一个空间注意力强监督。也就是我们人为划定好的空间注意力机制。但是还是那个问题,我们最终的目标不是学习 bounding box 的坐标,不是学习到背景的外轮廓信息 mask 有多么精确。这些中间结果对于最终目标不是很关键。或者说,模型可以学习到自己的一套关注的区域就可以了,不需要可解释性很强的区域也是可以的。那么对于这样的场景,我们没有必要在分割模型上做到最上层,也就是分辨率最高那层的 mask。只要做到中间层效果就已经出来了,无需浪费更多的参数量。
对于“U”型的图像分割模型,我们只需做到“J”型就够了。“J”型结构就是标准的 backbone + FPN。FPN 即保留了一定高分辨率的信息,又结合了底层上来的语义信息,是一个完美的“融合体”。在这一层再做一个 mask 就相当于是在这一层做了语义分割。其实这就是属于空间注意力机制。
空间 + channel 注意力机制
既然有了空间注意力,来都来了,我们也可以加上 channel 维度的注意力机制。我们耳熟能详的 attention 模块像 SE 属于 channel 维度的。BAM/CBAM 是空间维度 + channel 维度都有的注意力机制。但是他是分开做的。无论是串行还是并行,都是分为两个模块做。这个项目中利用 YOLOV4 中改写的 Modified SAM 模块,一步合成了 空间 + channel 的权重。简单而又便于理解。但是 channel 维度,确实就是个“顺便”,在此业务中,我觉得加不加都可以。
我们看一下中间的 grad CAM 结果

结果对比
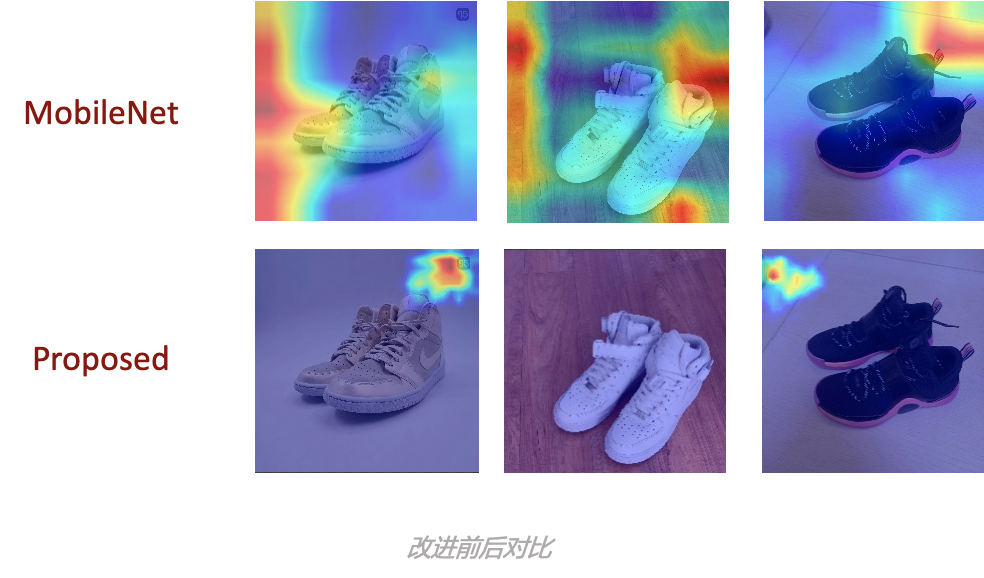
通过与没有加入上述 attention 模块以及 FPN 的模型对比改进之后的模型。原有模型在验证集上的正确率为 93%,改进后的模型在 96%。但更重要的是,改进后的模型在可解释性上有明显的增强。当可解释性增强之后,才会有明确的优化方向的可能性。
总结
以上就是对于如何在图像识别中做出创新的一种思路。但是创新的目的不是为了创新,整个项目下来最重要的核心就是为了 解决业务问题。
文/诗诗
关注得物技术,做最潮技术人!
这篇关于【得物技术】基于自注意机制的图像识别算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






