本文主要是介绍Pinterest推荐系统四年进化之路,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文链接:
http://www.sohu.com/a/144747856_775742
1. 基于Pin-Board的关联图,两个Pin的相关性与他们在同一个Board中出现的概率成正比。(类似协同过滤的思想)
2. 在有了最基本的推荐系统后,我们对Related Pin的排序进行了初步的手调,手调信号包括但不局限于相同Board中出现的概率,两个Pin之间的主题相似度,描述相似度,以及click over expected clicks得分。
3. 渐渐地,我们发现单一的推荐算法很难满足产品想要优化的不同目标,所以引入了针对不同产品需求生成的候选集(Local Cands),将排序分为两部分,机器粗排,和手调。
4. 最后,我们引入了更多的候选集,并且提高了排序部分的性能,用机器学习实现了实时的个性化推荐排序。
候选集生成(召回):兵来将挡,新需求来,新候选集挡
Board Co-occurrence:主要的候选集生成算法还是基于用户的Pin和Board关联图,最初是Map/Reduce离线算法。对于每个Board,输出这个Board里面所有的Pin Pairs,然后在Reducer里面计算每组Pin Pair出现频率。
由于数据量太大,所以我们进行了随机取样。在排序过程中还引入了Pin的描述和主题相似度等特征进行手调,效果很好。
后来我们发现基于Map/Reduce取样的算法得到的相关度还有提升空间,对于罕见的Pin常常不能生成足够多的候选集,所以开始使用online的随机游走生成候选集。这个随机游走算法被称为Pixie,通过对Pin和Board关联图进行几十万步的模拟随机游走产生候选集,能够很好地解决上面提到的两个问题。
Pin2Vec通过学习用户在一定时间内的保存行为,得出N个最流行的Pin的嵌入向量。通过一个Pin的向量和学习网络,既可以预测用户接下来想保存什么Pin,也可以找到与用户询问Pin最为相似的几个Pin。
每一个Pin会有相应的描述,主题等文字信息,由此可以产生基于搜索的候选集。这个候选集里的Pin比以上两种算法生成的相关度要差,结果相对发散,但是能给用户带来更好的探索体验。
另一种是基于图片相似度产生的候选集,可以直接借用极度相似的图片生成的推荐结果,也可以把类似的图片Pin推荐给用户。
Segmented Candidates:最后,为了优化产品的生态系统,Related Pin引入了针对新鲜内容的推荐集合(热点池,精品池)。在Pinterest走向国际化的道路上,又针对不同的市场做了不同的推荐集合。
排序过程:从拍脑袋到机器半自动
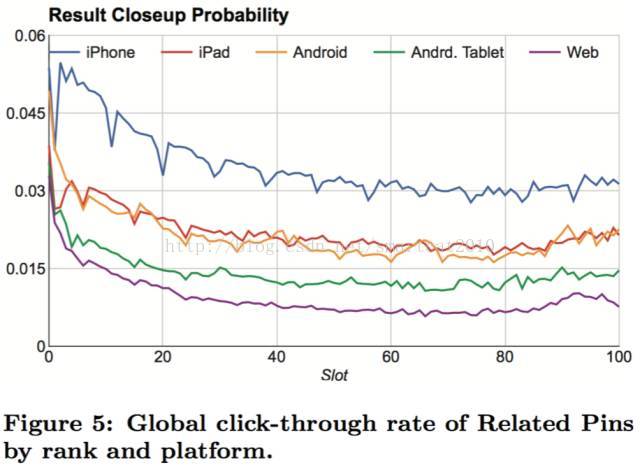
对于基本的搜索引擎和推荐系统,在有了大量数据之后,最容易实现的排序方式就是记住用户在每一个Related Pin页面与哪些Pin进行过互动。由于用户在使用不同客户端时,对不同位置的同一个Pin互动存在一定的偏差,所以我们在生成这个记忆的时候采用了clicks over expected clicks算法。一个Pin的Expected Click是这个Pin在不同位置上的impression数量与该位置的期望点击率的乘积。(记住点击率;不同机型,不同位置,平均点击率是不同的,要考虑进去)
我们设一个Pin的Memboost得分是clicks over expected clicks: (统计(query,候选)的点击率)
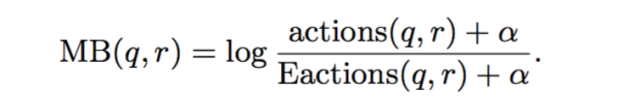
然后将Memboost得分和原始基于Pin和Board关联图,主题相似度和文字相似度得分线性结合在一起
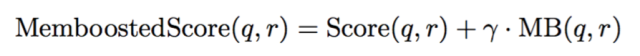 这种简单的排序被实验证明是非常有效的。
这种简单的排序被实验证明是非常有效的。
这个通过手调和记忆进行排序的过程在Pinterest度过了快三年的时光,在引入了越来越多的候选集后,人们逐渐意识到下一个大的提升可能来自于learning-to-rank。
Related Pins设计了ranker对候选集根据query pin,当前用户,以及当前用户的上下文进行重新排序。在排序的时候采用了四类不同的特征:

Pin的特征: 包括文字信息,图片信息,文字向量,主题类别信息以及Pin的人口信息 (如不同性别,不同国家和语言的统计信息)。
历史特征: 包括上文提到的Memboost,用户过去进行的不同类别的动作信息,点击,长点击,保存等等。
用户特征: 用户的性别,国家和语言。用户过去保存过的Pin,文字信息,主题信息等。
用户实时特征(短期用户画像):Query Pin是来源于主页,搜索还是哪一个Board。最近搜索过的问题,特征向量,最近保存过的,点击过的,长点击过的Pin。

在最初的版本里,我们从Memboost得分中生成训练目标,通常认为一个拥有高Memboost得分的Pin好于一个低Memboost得分的Pin,有Memboost得分的Pin好于一个随机的Pin,然后采用pairwise loss训练一个RankSVM模型。
但是上面的版本很难模拟不同用户对结果不同的反应,所以我们转移到一个基于Session的训练模型。每一个Session都包含一个Query Pin,当前用户,动作以及一系列的推荐pin。当用户保存一个pin时,我们把这个pin和之前的pin取出,做pairwise的学习。
(笔者认为:在这个实践过程中应该还引入了周边的pin,以及一些不相关的popular pin作为反例,不然学出来的结果有可能会反转原先排序)
版本三采用了RankNet loss和GBDT模型来模拟用户非线性的行为,新的模型也能更好的考虑“如果Query Pin的类别是艺术,那么视觉相似度是一个很强的信号”这样一类组合特征。
最后,版本4则由pairwise loss回归到pointwise loss,虽然学术界一直认为排序问题listwise优于pairwise,pairwise优于pointwise,但实践中pointwise常常能达到与pairwise一样好的推荐效果。从人理解角度来看,其实用pointwise来预测用户的点击率,保存率更容易解释,从而用得分作为一个参考,在排序过程中引入其他信号,全面的优化产品的生态系统。
论文:
图像用FC倒数第二层的向量表示;短期用户画像;
LR的结果和特征值的关系是线性的,因此特征构造麻烦,分桶,归一化等,要把特征值转为和结果程线性关系才行(或者0-1特征)
GBDT,叶子节点的深度,就是几个特征的组合。LR需要人工cross特征(也就是1~3层的深度)
正例太少,负例太多,模型会趋向于把所有都分成负例。一般如果正例比例<10%,要对正例进行加权(增大正例学习率,或者放到别的batch里重复训练);正例比例在20%左右,不需要加权;
这篇关于Pinterest推荐系统四年进化之路的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






