本文主要是介绍使用 K8s Ingress 实现企业微信域名配置中的回调域名校验文件设置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
在企业微信中配置业务域名时,通常需要在该域名的根路径下放置一个校验文件,以验证域名的所有权。可以使用Nginx来实现,将校验文件放在Nginx服务器即可,假如应用是部署在kubernetes中的话可以通过Ingress来实现,下面介绍具体实现
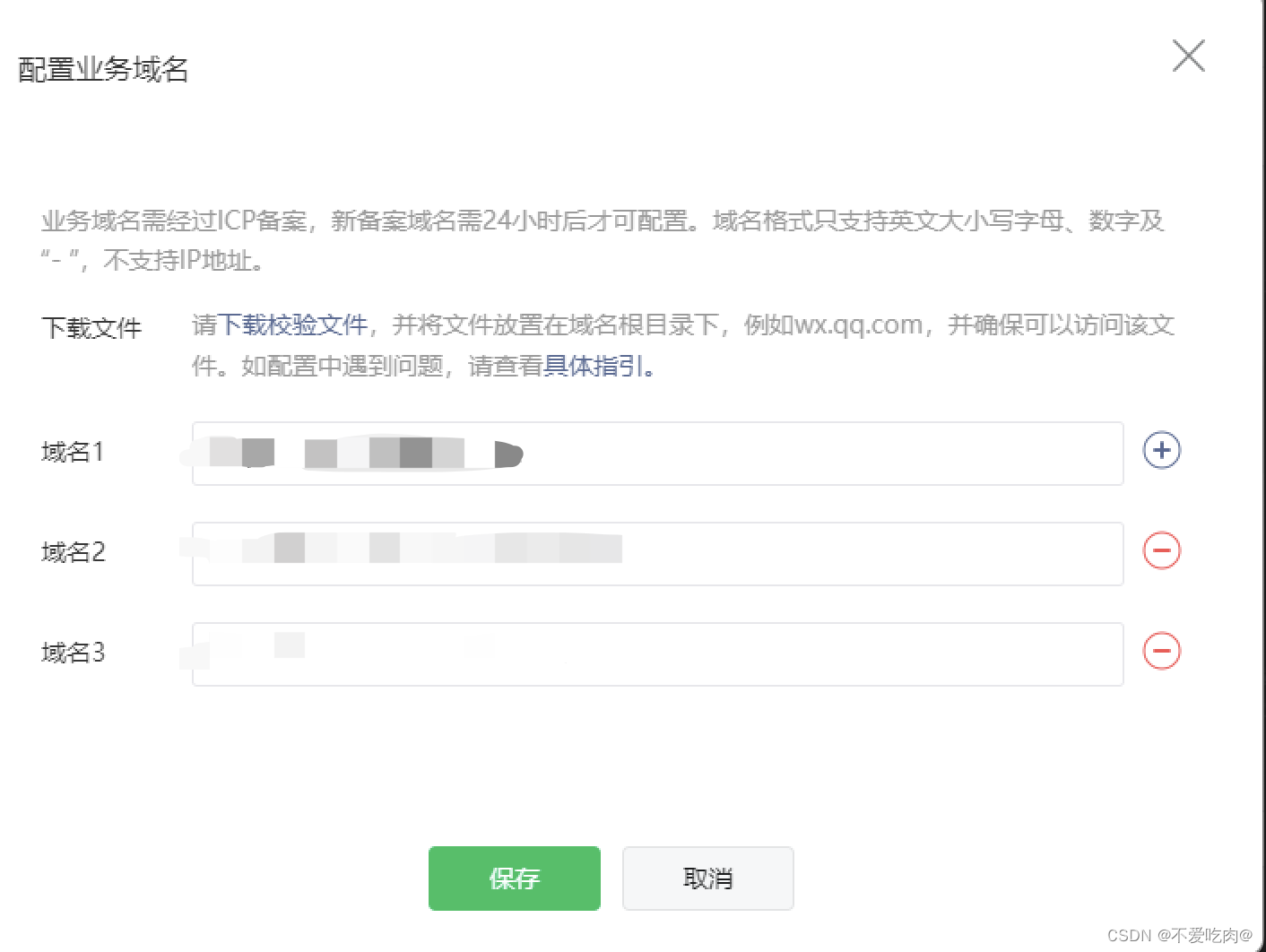
实现方法
下载校验文件
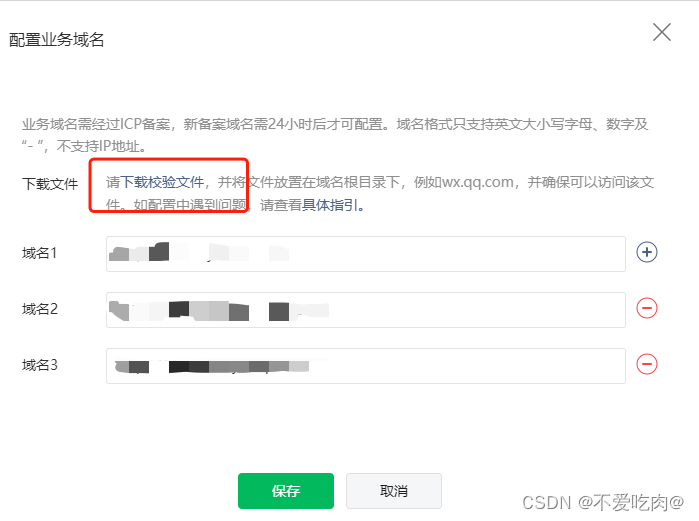
1.配置ingress(以阿里云ACK容器服务为例)
方法1编写yaml
找到回调域名应用的ingress,编辑该应用的ingress yaml
在
metadata:annotations:nginx.ingress.kubernetes.io/server-snippet: |location /verification.txt {default_type text/plain;return 200 "校验文件中的内容";#示例# return 200 "9er5742t19j9le8sndpc2caw3puidhog";}
方法2图形化操作
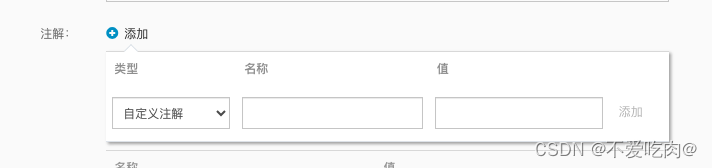
nginx.ingress.kubernetes.io/server-snippet # key
location /verification.txt { default_type text/plain; return 200 "9er5742t19j9le8sndpc2caw3puidhog";} # value
2.在公网dns服务器添加该域名解析记录
微信回调是通过公网回调的,所以要确保该回调域名公网可访问
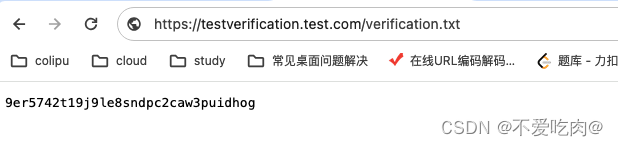
3.验证
这篇关于使用 K8s Ingress 实现企业微信域名配置中的回调域名校验文件设置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




