本文主要是介绍k8s的node亲和性和pod亲和性和反亲和性 污点 cordon drain,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
node亲和性和pod亲和性和反亲和性 污点 cordon drain
集群调度:
schedule的调度算法
预算策略
过滤出合适的节点
优先策略
选择部署的节点
nodeName:硬匹配,不走调度策略,node01
nodeSelector:根据节点的标签选择,会走调度的算法
只要是走调度算法,在不满足预算策略的情况下,所有pod都是pending状态。
node节点的亲和性:
硬策略和软策略
硬策略:必须满足条件,匹配原则也是根据节点的标签
软策略:尽量满足你的要求而不是一定满足
pod的亲和性和反亲和性
| 调度策略: | 匹配标签 | 操作符 | 拓扑域 | 调度目标 |
| node的亲和性 | 主机标签 | In(在) Notin(不在) exists(:存在选择标签对象) DoesNotExist(不存在,选择不具有指定标签的对象) Gt(大于选择的标签值) Lt(小于选择标签值) | 不支持 | 指定主机 |
| pod的亲和性 | pod的标签 | In(在) Notin(不在) exists(:存在选择标签对象) DoesNotExist(不存在,选择不具有指定标签的对象) Gt(大于选择的标签值) Lt(小于选择标签值) | 支持 | pod和指定标签的pod部署同一拓扑域 |
| pod的反亲和性 | pod的标签 | In(在) Notin(不在) exists(:存在选择标签对象) DoesNotExist(不存在,选择不具有指定标签的对象) Gt(大于选择的标签值) Lt(小于选择标签值) | 支持 | pod和指定标签的pod部署不同拓扑域 |
拓扑域:k8s集群节点当中的一个组织机构,可以根据节点的物理关系或者逻辑关系进行划分。可以用来表示节点之间空间关系,网络关系或者其他关系
标签,主机标签

注意点
1、pod的亲和亲和性策略,在配置时,必须要加上拓扑域,必须要加上拓扑域的关键字topologyKet,指向节点的标签
2、pod的亲和性的策略也分为硬策略和软策略
3、pid亲和性notin可以替代反亲和性
4、pod亲和性只要是为了把相关联的pod部署在同一节点,lnmp
你在进行部署的时候怎么考虑node节点:
硬策略 软策略还有污点和容器可以配合node的亲和性一块使用
污点:是node调度机制,不是pod
被设为污点的节点不会部署pod
污点的亲和性相反,亲和性是尽量选择和一定选择
污点的节点一定不被选择
污点的名称taint
taint有三种:
1、NoSchedule:k8s是不会把pod调度这个节点上
2、PreferNoSchedule:如果污点类型是他,尽量避免把pod部署在该节点上,不是一定。(master节点的污点就是这个)
3、NoExecute:如果污点类型是它,k8s将会把该节点上pod全部驱除,而且也不会调度到这个节点,不是基于控制器创建pod的会被直接杀死,基于控制器创建pod的会在其他节点重新部署
基于控制器创建的pod,虽然被驱逐,会在其他节点重新部署
kubectl describe nodes node01 | grep -i taints #查看污点
kubectl taint node node01 key=1:NoSchedule #创建污点
kubectl taint node node01 key:NoSchedule- #删除NoSchedule污点
注意点:
节点服务器需要维护的,维护的情况下服务器关机,几点上的pod将会失效。在工作中主要主要部署pod的方式控制器部署,deployment控制器是最多的,一旦节点设置为驱逐,控制器创建的pod会在其他节点重新部署
1、所有的pod都会被驱逐,跟命名空间无关,所有的一切都会被驱逐
2、不会创建方式是什么,都会被驱逐
3、系统集群组件不会被驱逐

容忍机制:
即使节点上设置了污点有了容忍机制,依然可以在设置为污点的节点上部署pod.
特殊情况:NoExecute依然可以部署pod,但是有生命周期,时间一到pod会被销毁重新拉起 并不
生命周期结束之后,会驱逐一部分pod到其他节点,有的节点还是会保留在污点上,有的节点还是会保留在污点节点上
该节点维护完毕测试下节点的工作是否正常
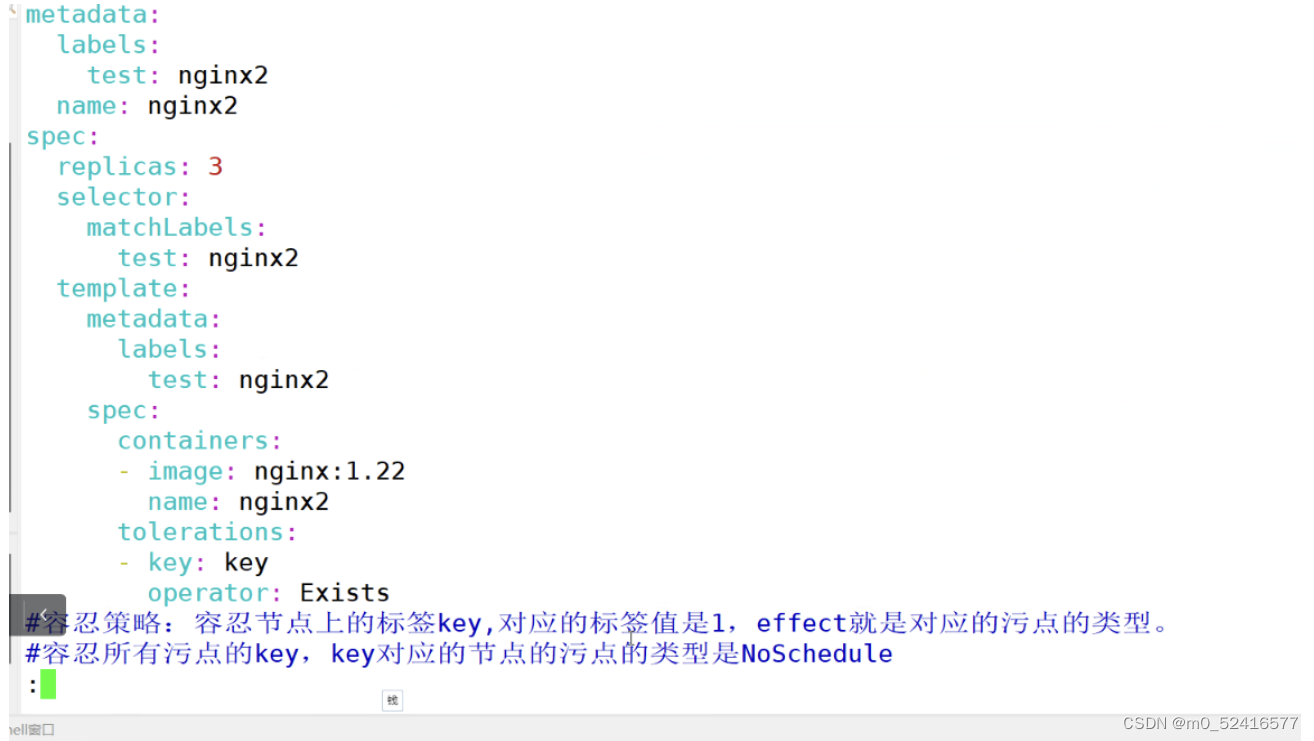
tolerations:
-key: key operator: Exists
指定key的值,指标节点的标签值,但是不指定污点的类型,要么所有节点上只要包含了这个指定的标签名,可以容忍所有的污点
tolerations
-operator: Exists
-effect: Noschedule
没有key,不匹配节点标签,会容忍所有污点,类型是我指定的类型
node的亲和性
pod亲和性和反亲和性
污点和容忍
如何选择node节点部署pod
选择一个我期望的节点来部署pod
第一个例子
有多个master节点 一般会把kubectl taint node master名称 node-role.kubernetes.io/master=:PreferNoschedule
尽量不忘master节点上部署pod,但是不是一定的,防止资源浪费,自定义一个标签
业务维护:
node02需要维护2个小时
但是这个节点还有业务pod在运行
就需要把这个节点的污点设置为:NoExecute
我们部署pod一般都使用deployment部署,会在其他的重新部署,并不是被杀死
自主式的pod会被杀死
一点节点恢复,一定要污点去除
cordon和drain
cordon可以直接把节点标记为不可用状态
kubectl cordon node01 标记节点不可用
kubectl uncordon node01 删除标记不可用
drain:排水,把该节点下的po全部转移到其他node节点上运行
1、一旦执行drain,被执行的节点会变成不可调用状态
2、驱逐该节点上的所有pod
kubectl drain node02 --ignore-daemonsets --delete-local-data --force
drarin:排水,标记node节点为不可调度,然后驱逐pod
--ignore-daemonsets:忽视daemonsets部署的pod,daemonsets部署的pod还在节点
--delete-local-data:有本地挂载卷的会被强制杀死
--force:强制释放不是控制器管的pod
--ignore-daemonsets
还是如何来管理和部署pod
node亲和性和pod亲和性和反亲和性
污点 cordon drain
如何部署pod是比价重要的子群资源调度机制,合理的配置pod的调度机制可以是资源最大化利用
这篇关于k8s的node亲和性和pod亲和性和反亲和性 污点 cordon drain的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





