本文主要是介绍关于外连接、内连接和子查询的使用(2),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一. 前言
二. 使用外连接、内连接和子查询进行解答
三. 思维导图
一. 前言
在前面我们对外连接、内连接和子查询的使用有了一些了解,今天我们将继续更深入的进行学习。(这里缺少的八个题目在博主的前面博客有解答,大家可以移步前面一篇博客)
二. 使用外连接、内连接和子查询进行解答
- 09)查询学过「张三」老师授课的同学的信息
- 涉及表:t_mysql_course,t_mysql_student,t_mysql_teacher,t_mysql_score
- 表之间的关系:老师可以绑定课程,课程里面有分数,分数可以绑定学生
SELECTs.*,c.cname,t.tname,sc.score
FROMt_mysql_teacher t,t_mysql_student s,t_mysql_course c,t_mysql_score sc
WHEREt.tid = c.tid AND c.cid = sc.cid AND sc.sid = s.sid AND tname = '张三'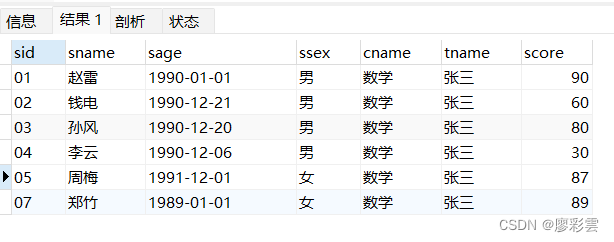
- 10)查询没有学全所有课程的同学的信息
- 涉及表:t_mysql_student s ,t_mysql_score
- ① 统计一共有多少门学科
② 统计每个学生学了多少门 (不管有没有学都有(每个学生)--- 外联)
③ 做比较
SELECTs.sid,s.sname,count( sc.score ) n
FROMt_mysql_student sLEFT JOIN t_mysql_score sc ON s.sid = sc.sid
GROUP BYs.sid,s.sname
HAVINGn < (SELECTcount(*) FROMt_mysql_course )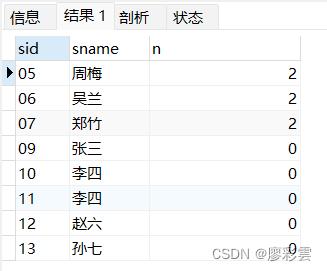
- 11)查询没学过"张三"老师讲授的任一门课程的学生姓名
寻找张三老师教了那些课程
没学过:那么对应的课程就没有分数
使用 not in
重复了结果要使用分组
SELECTs.sid,s.sname
FROMt_mysql_score sc,t_mysql_student s
WHEREs.sid = sc.sid AND sc.cid NOT IN ( SELECT cid FROM t_mysql_course c, t_mysql_teacher t WHERE c.tid = t.tid AND t.tname = '张三' )
GROUP BYs.sid,s.sname
- 12)查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
- 涉及表:_mysql_student s, t_mysql_score sc
SELECTs.sid,s.sname,count(sc.score) n,ROUND(avg( sc.score ),2)
FROMt_mysql_student s,t_mysql_score sc
WHEREs.sid = sc.sid AND sc.score < 60
GROUP BYs.sid,s.sname
HAVING n>=2 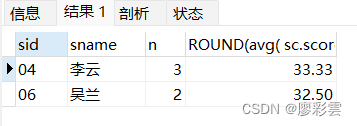
- 13)检索" 01 "课程分数小于 60,按分数降序排列的学生信息
- 涉及表:t_mysql_student s, t_mysql_score sc
SELECTs.*,sc.score
FROMt_mysql_student s,t_mysql_score sc
WHEREs.sid = sc.sid AND sc.cid = '01' AND sc.score < 60
ORDER BYsc.score DESC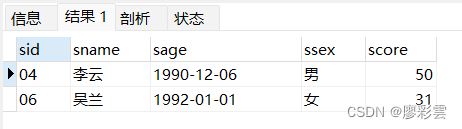
- 14)按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
平均 avg --- GROUP BY分组
从高到低 --- ORDER BY
所有学生的所有课程的成绩 --- 行转列
所有学生 --- 外联(所有)--- RIGHT JOIN右联
平均值:取两位ROUND( AVG(sc.score) , 2 )
SELECTs.sid,s.sname,sum(( CASE WHEN sc.cid = '01' THEN sc.score END )) 语文,sum(( CASE WHEN sc.cid = '02' THEN sc.score END )) 数学,sum(( CASE WHEN sc.cid = '03' THEN sc.score END )) 英语,ROUND( AVG(sc.score) , 2 ) 平均分
FROM t_mysql_score sc
RIGHT JOIN t_mysql_student s ON sc.sid = s.sid
GROUP BYs.sid,s.sname
ORDER BY 平均分 DESC 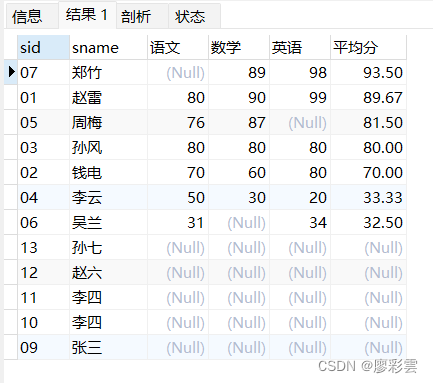
推荐: 但是我们可以很明显的看到查询出来的数据有非常多的 null 值,十分不美观,那么我们可以试试 if
- 如果cid等于 '01' ,那么就取分数,如果没有就取0(类似于三元运算符)
- sum( if( sc.cid = '01', sc.score, 0 )) 语文
SELECTs.sid,s.sname,sum( if( sc.cid = '01', sc.score, 0 )) 语文,sum( if( sc.cid = '02', sc.score, 0 )) 数学,sum( if( sc.cid = '03', sc.score, 0 )) 英语,ROUND( AVG(sc.score) , 2 ) 平均分
FROM t_mysql_score sc
RIGHT JOIN t_mysql_student s ON sc.sid = s.sid
GROUP BYs.sid,s.sname
ORDER BY 平均分 DESC
- 15)查询各科成绩最高分、最低分和平均分:
--- 以如下形式显示:课程 ID,课程 name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率,及格为:>=60,中等为:70-80,优良为:80-90,优秀为:>=90
--- 要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
- 无论有没有考试都要算成绩:left join --- 外联
最高分:max(),最低分:min(),平均分:avg()
统计及格率:及格人数÷总人数*100%
SELECTc.cid,c.cname,count(sc.sid) 人数,max(sc.score) 最高分,min(sc.score) 最低分,ROUND(avg(sc.score),2) 平均分,CONCAT(ROUND(sum(if(sc.score>=60,1,0))/(SELECT COUNT(1) from t_mysql_student)*100 ,2),'%') 及格率,CONCAT(ROUND(sum(if(sc.score>=70 and sc.score<80,1,0))/(SELECT COUNT(1) from t_mysql_student)*100 ,2),'%') 中等率,CONCAT(ROUND(sum(if(sc.score>=80 and sc.score<90,1,0))/(SELECT COUNT(1) from t_mysql_student)*100 ,2),'%') 优良率,CONCAT(ROUND(sum(if(sc.score>=90,1,0))/(SELECT COUNT(1) from t_mysql_student)*100 ,2),'%') 优秀率
FROMt_mysql_score scLEFT JOIN t_mysql_course c ON sc.cid = c.cid
GROUP BYc.cid,c.cname

三. 思维导图

这篇关于关于外连接、内连接和子查询的使用(2)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




