本文主要是介绍火山引擎 ByteHouse:如何提升 18000 节点的 ClickHouse 可用性?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
ClickHouse 是业内被广泛使用的 OLAP 引擎。当集群规模过大时,ClickHouse 则面临使用局限性的问题。如何提升 ClickHouse 的可用性,成为困扰广大开发者的难题之一。
目前,字节跳动内部的 ClickHouse 节点总数超过 18000 个,管理总数据量超过 700PB,最大的集群规模在 2400 余个节点。字节跳动内部很多业务都建立在 ClickHouse 为基础的查询引擎上,因此在可用性提升上具备广泛经验。
在内部丰富经验的基础之上,火山引擎也将字节跳动可用性方面经验通过云原生数据仓库 ByteHouse 对外输出。ByteHouse 以开源 ClickHouse 为基础,经过字节跳动多年的优化和完善,提供了更丰富的功能和更强的性能,主要为用户带来极速的分析体验,解决了 ClickHouse 集群节点数增长过快,带来的多方面问题:Zookeeper 性能出现瓶颈,故障发生频率增加;故障恢复时间过长;运维复杂度提升。
为了进一步提升 ClickHouse 的可用性,ByteHouse 从降低 Zookeeper 压力和提升故障恢复能力两个方面进行升级。
首先,ByteHouse 采用先进的集群管理策略,降低 Zookeeper 在集群管理中的角色和压力。Zookeeper 在分布式系统中常常被用作协调和管理节点,但在大规模集群中可能会成为性能瓶颈。通过减少对 Zookeeper 的依赖,ByteHouse 将部分协调和管理功能下放到各个节点上,使得集群中的每个节点能够自主地进行协调和管理,从而降低了 Zookeeper 的压力。
其次,ByteHouse 提升了 ClickHouse 故障恢复能力。在分布式系统中,故障恢复是保障系统可用性的重要环节。通过完善的数据备份和恢复策略,ByteHouse 可以在节点发生故障时,快速恢复数据和系统状态。此外,ByteHouse 还通过节点状态实时检测和自动隔离策略,防止故障扩散到整个集群。
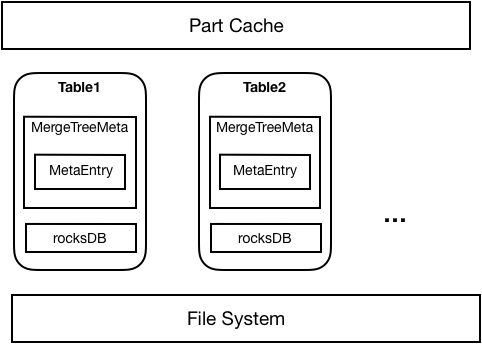
ByteHouse 故障恢复改造思路
以上优化策略不仅提高了集群的性能和稳定性,也使得 ByteHouse 成为了企业级用户在大数据处理和分析领域的重要选择。未来,火山引擎 ByteHouse 将继续致力于提供更优质的大数据处理和分析服务,帮助企业更好实现数字化转型。
这篇关于火山引擎 ByteHouse:如何提升 18000 节点的 ClickHouse 可用性?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









