本文主要是介绍Linux环境搭建Nacos集群+Ngnix负载均衡,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Linux环境搭建Nacos集群
1.环境准备
需要1个nginx+3个nacos注册中心+1个mysql
Linux 64bit OS Linux/Unix/Mac //推荐使用Linux系统
需要三个或三个以上的Nacos才能构成集群。
本次搭建使用的是nacos-server-1.4.2.tar.gz , 下载地址
https://github.com/alibaba/nacos/releases/download/1.4.2/nacos-server-1.4.2.tar.gz
2.开始搭建
-
mysql新建nacos的数据库,并执行脚本https://github.com/alibaba/nacos/blob/master/config/src/main/resources/META-INF/nacos-db.sql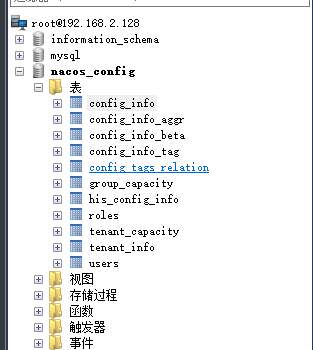
-
先把
nacos-server-1.4.2.tar.gz放到linux,可以使用xftp工具方便。这里我选择放到/opt/nacoscluster下。解压三份并重命名
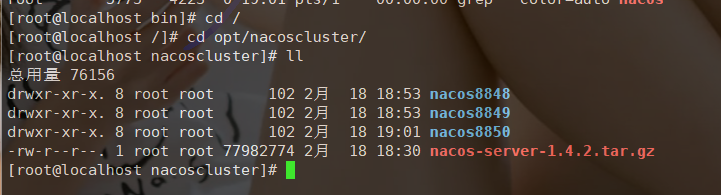
-
进入三个节点conf/application.properties配置,更改数据库。
vim application.properties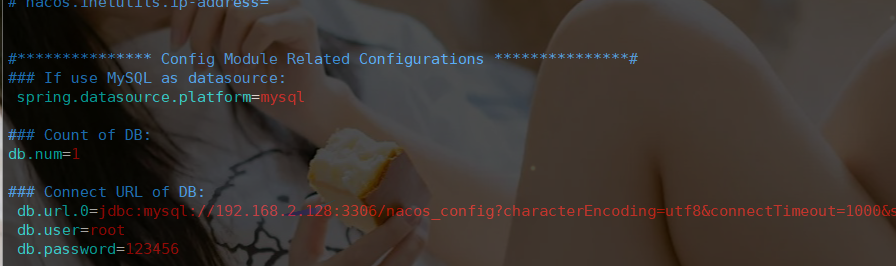
spring.datasource.platform=mysql db.num=1 db.url.0=jdbc:mysql://你的IP:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true db.user=用户名 db.password=密码 -
三个节点/conf下配置cluster.conf,注意有个文件叫cluster.conf.example 那个文件只是做示例的
vim cluster.conf 配置集群IP和端口
192.168.2.128:8848 192.168.2.128:8849 192.168.2.128:8850 -
启动三个结点前,建议修改一下内存大小,不然虚拟机内存可能不够用
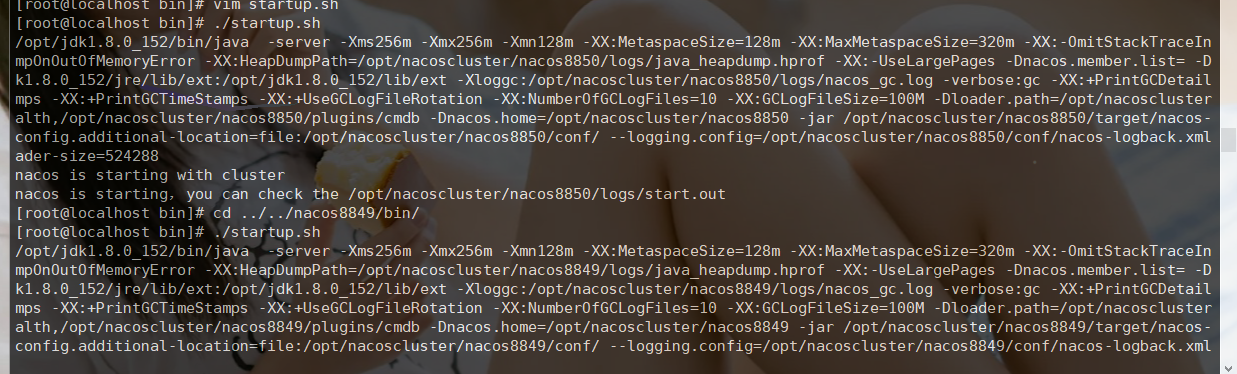
切换到bin目录下,vim startup.sh


-
然后就可以启动了 ./startup.sh ,分别启动三个结点
-
查看nacos状态
ps -ef | grep nacos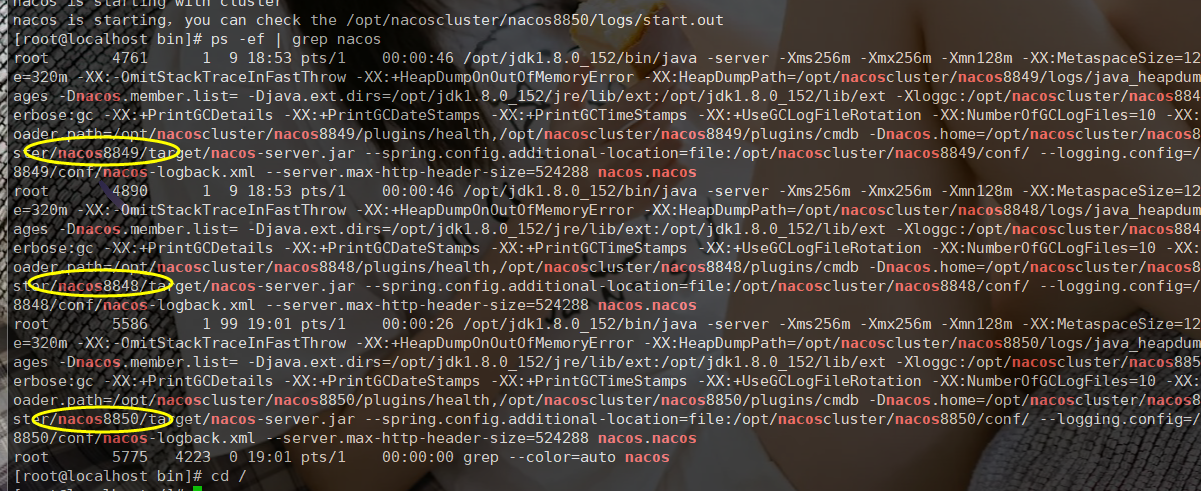
可以发现都启动成功了,接下来我们去浏览器随便访问一个nacos
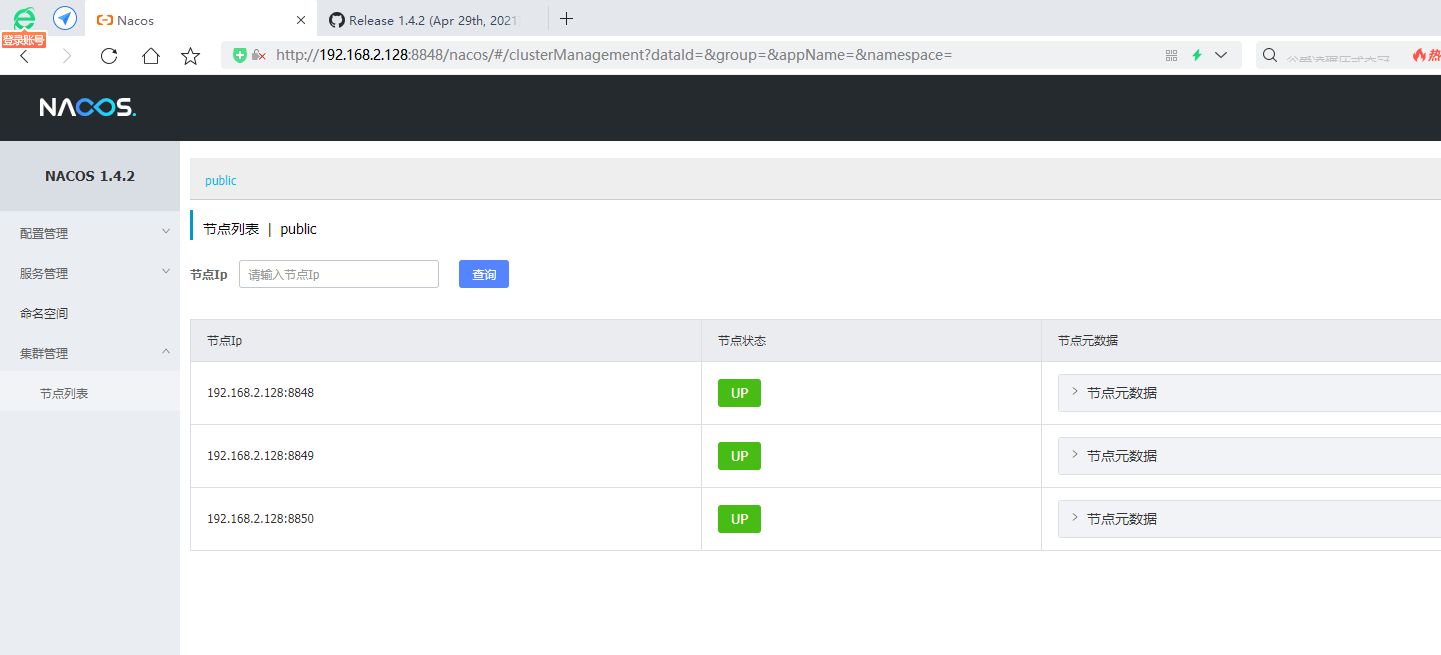
3.Ngnix配置
由ngnix作为负载均衡器,修改ngnix.conf
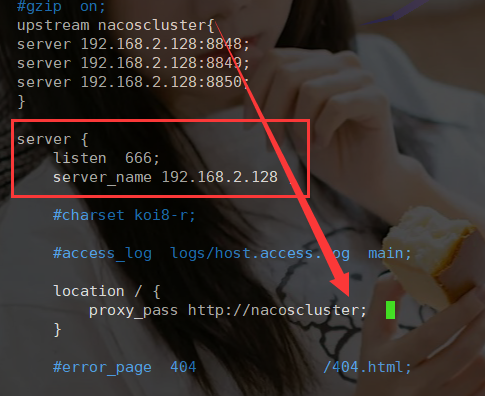
切换到sbin目录下
./nginx -c /usr/local/nginx/conf/nginx.confps -ef|grep nginx
访问 https://192.168.2.128:666/nacos
至此集群搭建成功,有条件可以用三台机器玩。
这篇关于Linux环境搭建Nacos集群+Ngnix负载均衡的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








