本文主要是介绍oracle 12c pdb expdp/impdp 数据导入导出,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
环境
(源)rac 环境 byoradbrac
系统版本:Red Hat Enterprise Linux Server release 6.5
软件版本:Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit
byoradb1:172.17.38.44
byoradb2:172.17.38.45
(目的)单机环境 byoradb
系统版本:CentOS Linux release 7.9.2009
软件版本:Oracle Database 12c Enterprise Edition Release 12.2.0.1.0 - 64bit
byoradbdg:172.17.38.55
源端操作数据导出(expdp)
12c 的环境如果引入了pdb模式
那每个pdb需要单独执行 数据库级别的导出 即 full=yes ;
且每个pdb 导出目录需单独配置 ;
导出使用的账号可以使用sys 或其他sysdba账号或者每个pdb的管理账号分别导出每个pdb;
源端配置每个pdb的tnsname
#登录数据库sqlplus / as sysdba#查看所有pdbSQL>show pdbs;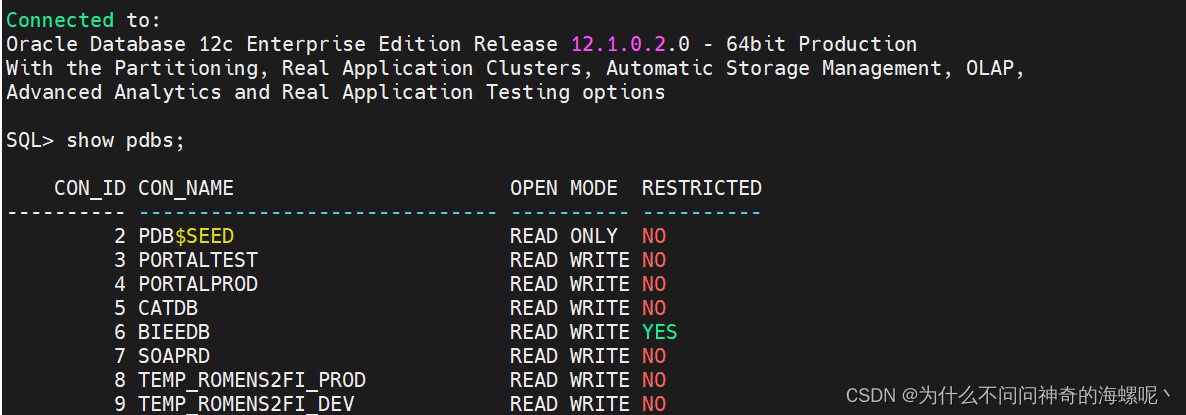
#配置 tnsnames.ora , 使账号能通过@方式在服务端直接连入pdbfind / -name tnsnames.ora

#分别为每个pdb配置好tnsname
vi /u01/app/oracle/product/12c/dbhome_1/network/admin/tnsnames.oraSOAPRD =(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 172.17.38.44)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = SOAPRD)))CATDB =(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 172.17.38.44)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = CATDB)))PORTALPROD =(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 172.17.38.44)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = PORTALPROD)))TEMP_ROMENS2FI_PROD =(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 172.17.38.44)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = temp_romens2fi_prod)))TEMP_ROMENS2FI_DEV =(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 172.17.38.44)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = TEMP_ROMENS2FI_DEV)))BIEEDB =(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 172.17.38.44)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = BIEEDB)))源端检查配置每个pdb的导出目录
#切换pdb
alter session set container=PORTALPROD ;#查看导出目录
SELECT * from dba_directories ; #重建导出目录
create or replace directory bakz as '/oracledata/';
源端执行导出
#未指定tnsname时直接连入cdb
#PDB$SEED 为pdb模板、 可选择性导出、新环境也会存在
#根据实际情况导出pdbnohup expdp \' sys/zyz123456 as sysdba \' directory=bakz dumpfile=expdpcdb.dmp logfile=expdpcdb.log full=yes > nohup_expcdb.out &nohup expdp \' sys/zyz123456@PORTALPROD as sysdba \' directory=bakz dumpfile=expdpPORTALPROD.dmp logfile=expdpPORTALPROD.log full=yes > nohup_expPORTALPROD.out &导出完成后传入到新环境
scp xxx 172.17.38.55:/xxx
目的端操作数据导入(impdp)
12c 的环境如果引入了pdb模式
那每个pdb需要单独执行导入操作;
且每个pdb 导出目录需单独配置 ;
导入使用的账号可以使用sys 或其他sysdba账号或者每个pdb的管理账号分别导入每个pdb;
由于源端为rac环境、 自动创建表空间指定数据文件时、单机不存在asm路径、
所以需要手动创建对应表空间
创建新环境
可参考
oracle12c 静默安装
或者
Oracle12c一键安装
创建pdb
可参考
Oracle12c创建pdb
# 修改系统参数
alter system set db_create_file_dest='/oracledata/app/oracle/oradata/';
#创建pdb
CREATE PLUGGABLE DATABASE BIEEDB ADMIN USER pdbadminz IDENTIFIED BY "zyz@123456" ;
#切换pdb
alter session set container=BIEEDB ;
#打开pdb
alter pluggable database BIEEDB open;
#查看自动创建的数据文件位置
select name from v$datafile;源端查询、生成创建表空间语句 (每个pdb需单独处理)
#普通表空间
select 'create tablespace '|| a.name || ' datafile ''/oracledata/app/oracle/oradata/BYORADB/0E07968F3BDD1243E0630100007FB9BA/datafile/'||b.name||'_'||a.name||'01.dbf'' size ' || -- 此处文件路径依照目的端datafile文件路径、每个pdb 需对应
case when ROUND(sum(c.bytes)/1024/1024/1024,0)=0
then TO_CHAR('500M')
ELSE to_char(ROUND(sum(c.bytes)/1024/1024/1024, 0))||'G'
end
||' AUTOEXTEND on next 1G ;',
a.con_id ,a.TS#,b.name as conname , a.name as tablespname, ROUND(sum(c.bytes)/1024/1024/1024, 4) as usegb ,ROUND(sum(c.bytes)/1024/1024/1024, 0) as usegbm from V$tablespace a INNER JOIN v$pdbs b on a.con_id=b.con_id inner join v$datafile c on a.TS#=c.TS# and a.con_id=c.con_id where a.name not in ('SYSAUX','SYSTEM','TEMP')
and a.con_id=4 -- 指定pdb
group by a.con_id, a.TS#,a.name , b.name
ORDER BY a.con_id
;
#临时表空间
SELECT tablespace_name AS "Tablespace Name",ROUND(SUM(bytes) / (1024 * 1024*1024), 2) AS "Size in MB"
FROM dba_temp_files
GROUP BY tablespace_name;#可使用dbms包查看如果生成创建语句中不带数据文件路径、 则导入时会自动创建、无需手动创建
SELECT DBMS_METADATA.GET_DDL('TABLESPACE', 'TABLESPACE_name')
FROM DUAL;以上为依照数据源端的表空间创建目的端表空间、需注意每个pdb的目录与表空间容量、单个数据文件如未特殊设置、最大不可超过32G、 如某个表空间大于32G 、那以上sql生成的自动创建语句失效、 需手动调整
目的端创建表空间
create tablespace USERS datafile '/oracledata/app/oracle/oradata/BYORADB/0E071A0FA3E00637E0630100007F17A4/datafile/bieedb_user01.dbf' size 10G AUTOEXTEND on next 1G MAXSIZE 30G;
目的端配置每个pdb的tnsname
#分别为每个pdb配置好tnsname
vi /oracledata/app/oracle/product/12c/dbhome_1/network/admin/tnsnames.oraSOAPRD =(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 172.17.38.55)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = SOAPRD)))CATDB =(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 172.17.38.55)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = CATDB)))PORTALPROD =(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 172.17.38.55)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = PORTALPROD)))TEMP_ROMENS2FI_PROD =(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 172.17.38.55)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = temp_romens2fi_prod)))TEMP_ROMENS2FI_DEV =(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 172.17.38.55)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = TEMP_ROMENS2FI_DEV)))BIEEDB =(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 172.17.38.55)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = BIEEDB)))目的端检查配置每个pdb的导出目录
#切换pdb
alter session set container=PORTALPROD ;#查看导出目录
SELECT * from dba_directories ; #重建导出目录
create or replace directory bakz as '/oracledata/';
目的端执行导入
#未指定tnsname时直接连入cdb
#根据实际情况导入pdbnohup impdp \'sys/zyz123456 as sysdba\' directory=bakz dumpfile=expdpcdb.dmp logfile=impcdb.log > nohup_impcdb.out &nohup impdp \'sys/zyz123456@BIEEDB as sysdba\' directory=bakz dumpfile=expdpBIEEDB.dmp logfile=impdpBIEEDB.log > nohup_impBIEEDB.out &impdp 导入可多次重复执行 默认会跳过已存在的对象
这篇关于oracle 12c pdb expdp/impdp 数据导入导出的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






