本文主要是介绍不服不行!java管理系统项目连接数据库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、
前些年,互联网行业里对架构师这个岗位的标准还不是很清晰。所以,很多架构师的工作往往就是一些技术被公司认可的资深工程师负责。
彼时,正巧我也是这类人员之一,故也得到了一个从零开始架设一套广告投放平台的机会。
我很喜欢钻研技术,对这种机会自然很看重。
那时候,架构并无如今这么复杂,一开始就是前面搞几个 Web 应用,后面共享个数据库。大致像这样:
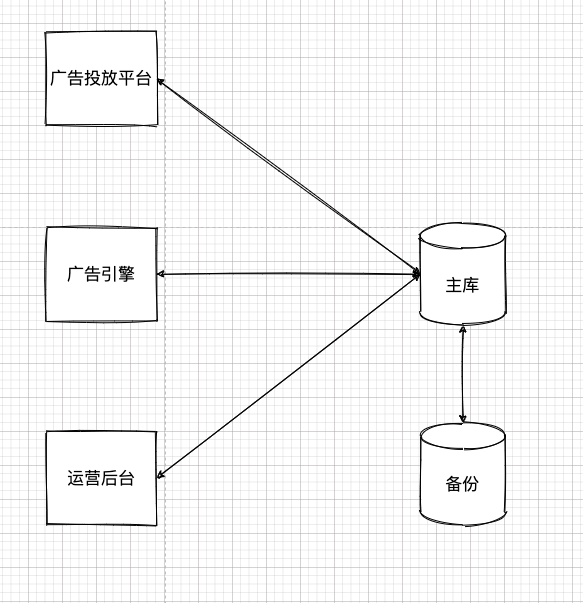
当然,上面的架构其实做了很多简化,省略了很多细节。比如,为了提高性能做的缓存,为了提高吞吐做的负载均衡统统没有在上图给出。因为这些和本章话题无关,暂时咱们就忽略这些东西,只看核心部分。
这套架构初期运行还是没什么问题的,再加上一些缓存机制,初期一些性能问题都通过调整缓存提升缓存的碰撞率应付了过去。
可是,随着广告投放量的增大,广告的访问量也在暴涨。这些暴涨的访问量引发了性能问题。当时,由于前端有负载均衡,应用层倒是没出现什么问题……
问题出在后面的数据库上
二、
这套架构数据库用的是 MySQL,本身也只有一台主库在对外服务,另外一台备库采用了 MySQL 自己的全同步机制做实时备份。
当广告访问量暴涨的时候,因为业务需要,很多数据需要在数据库中做实时插入,这就导致了大量的磁盘 IO 产生。这些大量的磁盘 IO 造成了数据库本身性能的急剧下降。
悲催的是,整套广告平台的所有功能又都是共享一个数据库的,所以随着数据库本身的性能下降,平台的所有功能都受到了影响。
由于问题主要在于大量广告流量的写入,所以,靠读写分离的方案去缓解问题这条路就走不通了。
只好先升级硬件了。在经过了几轮硬件升级和数据库调优之后,单数据库再也无法支撑不断上涨的流量了。没办法,要考虑搞数据库切分了。
那时候,我个人是很恐惧数据库切分的。
原因不仅仅在于需要在应用层多写很多复杂的逻辑,其根本原因是当时流行的 2PC(两阶段提交)方案,这个方案本身能保证在数据库切分的情况下,原来的事务依然保留着自身的 ACID 性质。即:
- Atomicity(原子性),不管事务里执行多少命令,对外它们都是一体的,要么都执行,要么都不执行。
- Consistency(一致性),正因为事务里要么做要么都不做,所以数据库的状态变化只能由事务变更后,才会叫一致性状态。
- Isolation(隔离性),事务里做的事儿事务外面谁也看不到,就跟个盒子把数据罩起来一样,到底中间怎么变化的,事务外面的观察不到。
- Durability(持久性),事务确认成功了,那这状态就永久不变了。
但也正因为这 4 个特性,2PC 才让我顾虑重重。
顾虑1:首先,数据库拆分了,那么根据事务的原子性,事务自身必须是一体的,那么事务涉及到的不同的数据库就必须都访问一遍,而这本身就意味着很高的通信成本。
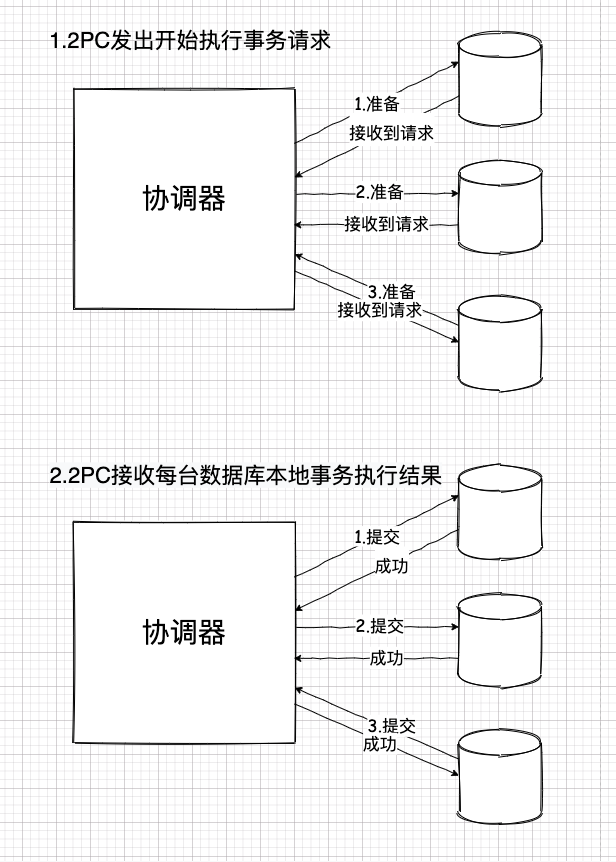
再加上,为了保持一致性,事务失败后,还必须恢复各个数据库原来的状态,这就必须让已经成功执行过本地事务的数据库全部回滚。
而稍微懂点数据库的人都知道,这个成本有多大。
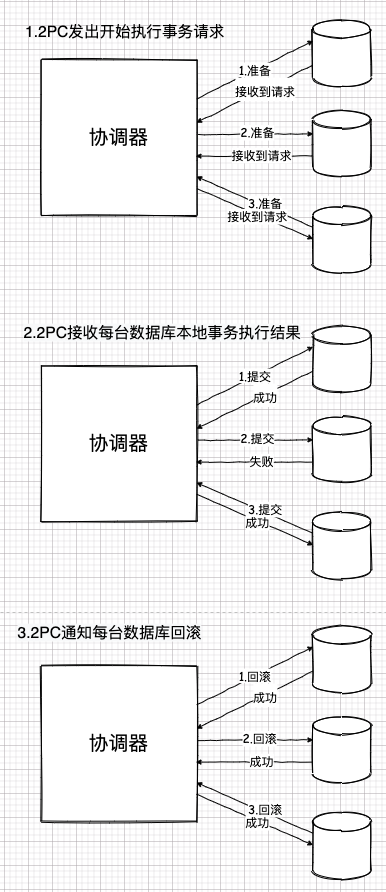
更可怕的是,本身事务的隔离性还可能加上锁。一旦一个热点数据区域被大量访问,最差情况就可能出现串行访问。而这对此套平台,包括我自己都将是个悲剧。
顾虑2:数据库的拆分会造成整个平台的可用性下降。
假设我现在有一台数据库,它的可用性是 99.9%。如果因为分库,数据库从一台变成两台,那么平台的可用性就会变成:
平台的可用性 = 99.9% * 99.9% = 99.8%
从 99.9% 变成了 99.8%,这意味着可用性下降了 0.1%,每个月的不可用时间会增加 43 分钟之多。
一边是硬件升级已经到顶,单机数据库也优化到了极限,再不做数据库拆分,平台可能随时瘫痪。一边是没有好的策略,可能拆分数据库后,每个月都有宕机的风险,同时性能也可能会出现剧烈的下降。
我被逼入了死角。
三、
这种痛苦的纠结折磨了我大概一周,直到我看到了 CAP 定理。当 CAP 定理说分布式系统在分区容错的时候,只能一致性和可用性二选一时,我高兴的蹦了起来。
原来,可用性和一致性是不能兼得的。
为何我会那么高兴?因为逼我入死角的可不仅是技术上的问题了,我还承受着来自于业务方和领导的压力。每天一上班,我就需要面对业务各方的抱怨,以及领导一轮又一轮的催促。
有了 CAP 定理的支持,我知道我最终是要面临选择的。既然在这个世界上做分布式架构的所有人都要面临选择,那我又怎么可能独善其身呢?
在对单机数据库引发的各种问题做了一次彻底的各种归因以后,我下了决心:
一定要搞定拆分数据库并给出良好方案。
只是,2PC 这个拦路虎,它成为了我的大敌。通过 CAP 定理,我非常肯定,只要我选了 2PC 方案,可用性就一定会出现严重的问题,这个方案也肯定不可能拿出来丢人现眼的。
我唯一的方向就是去牺牲一些一致性,往可用性方向走。可是,怎么走呢?
也许是老天眷顾,也许是大家都承受着和我一样夜不能寐的压力,很快,BASE 理论在国内传开了。
BASE 理论让我知道了,这个世上能排到前几名的技术大公司也一样会出问题,也一样会对这些问题进行妥协。而且 BASE 理论的思想让我的思路一下子就打开了,苦思而不得的问题开始有了头绪。
我要开始着手制定技术方案了。
四、
BASE 思想中的 BA(Basically Available)基本可用,是鼓励通过预先的架构设计或者前期规划,尽量在分布式的系统中,把以前可能影响全平台的严重问题,变成只会影响平台中的一部分数据或者功能的非严重问题。
有了这个思想之后,我就对广告平台中的很多重要的数据表进行了拆分,并将这些表的数据分散到了不同的数据库中。
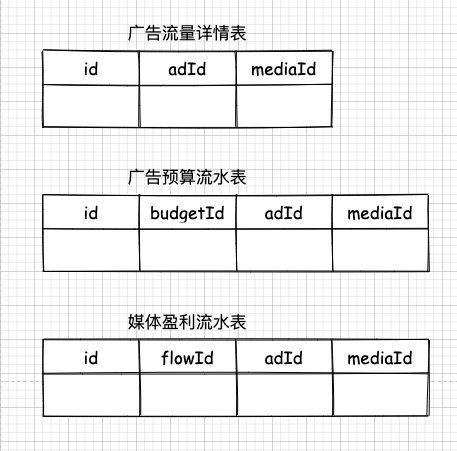
比如,有个广告流量详情表,每当用户点击广告或者广告展示出来的时候,为了保证不丢失,这些数据都是实时插入到这个表里的。
我对这张表是怎么切分的呢?
当有人点击广告了,他的点击记录会被传到我的应用层,然后我会在应用层根据广告 ID 做哈希,再根据哈希结果的不同,分别存到不同的数据库中去。
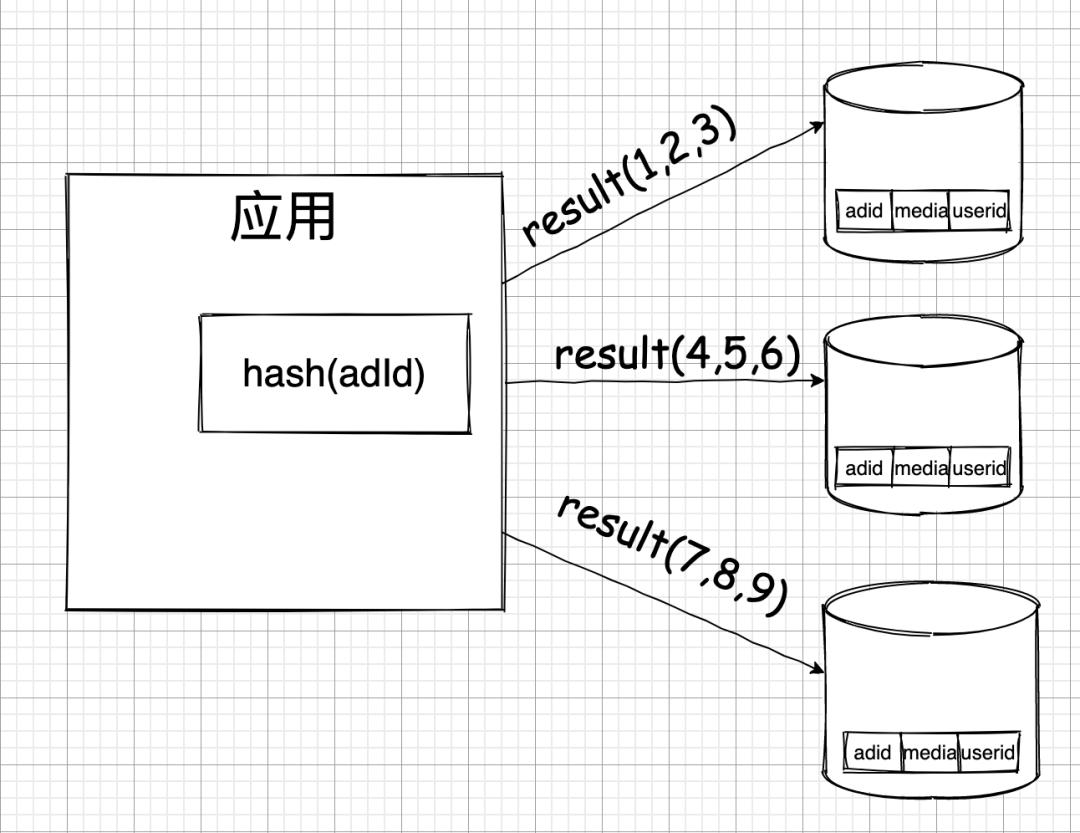
假如这三个数据库中的一个出现了问题,则只会有三分之一的数据受到影响。这就实现了 BASE 理论中的 BA——基本可用了。基本可用其实也真的就是表达的这么一回事:
通过一些架构设计,即使平台中某部分组件出现了问题,也不会导致整个平台不可用。
好了,既然采取了数据库拆分的策略,又根据 BASE 理论中的 BA 思想拆分了一些重要的表,那么,到了现在,可能也无从后悔,只能继续沿着 BASE 这条路,一条路走到黑了。
五、
接下来,需要着手解决性能问题了。2PC 方案……算了……它疯狂的一致性性格会要了我的狗命的。
那么极端点,我们不搞事务可不可以呢?
还用前面说的那套广告平台举例。
当时,从业务上,要求广告的访问数据都要保证及时入库不能丢,因为丢了就可能造成计费的损失,而这些损失全是钱。所以,每当用户点击广告或者广告展示出来的时候,为了保证不丢失,这些数据都是实时入库的。
又根据业务需求,当广告流量入库时,还需要往广告预算表和媒体流水表里同时根据这笔流量进行记账,以供后续财务计算。
如果完全不考虑事务,则拆分库后,操作可能会是这个样子。
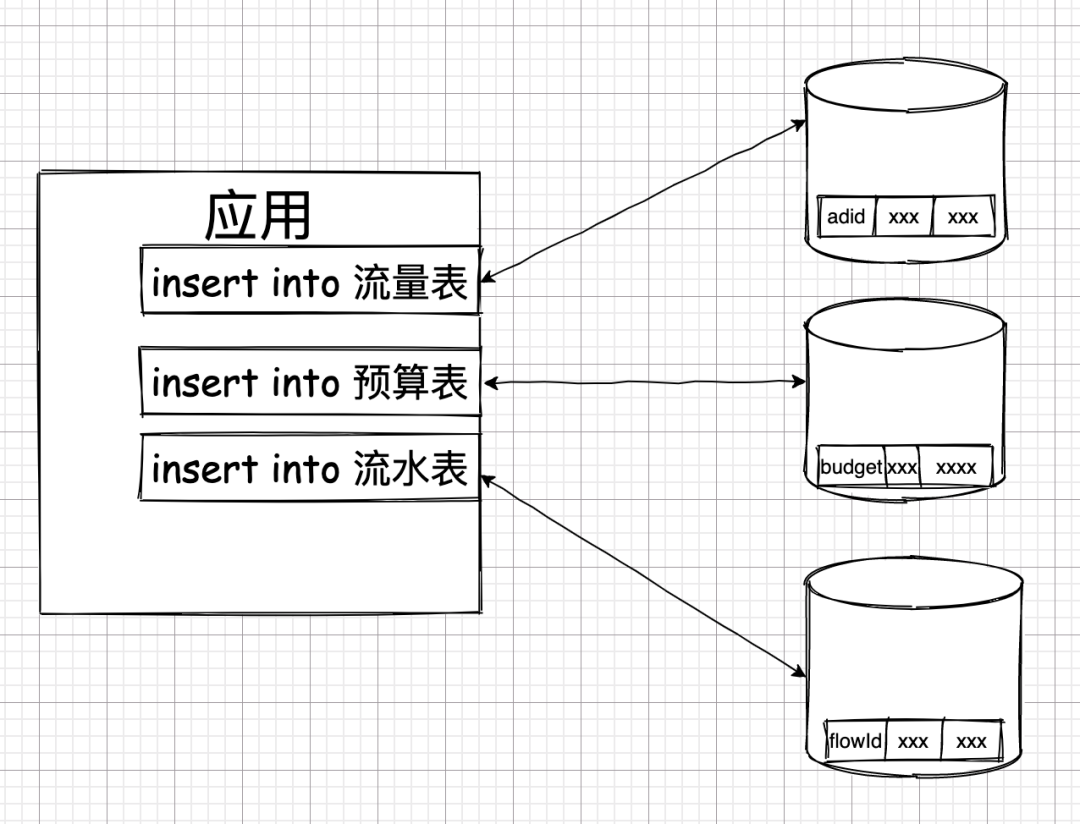
这三个操作可能会并行发往不同的数据库执行。由于三个操作之间没有事务的约束,所以,一个操作出问题了,另外的操作并不会受到影响。
而这却也引发了另外一个问题,数据状态不一致。
如果在上面的业务中,插入广告流量表的操作失败了,但其余两张表插入成功了,业务就会面临一个很尴尬的情况:他们算出的财务报表没有依据。财务流水中找不到产生了这笔流水的依据。
而这种不一致的状态由于已经被持久化到了数据库中,就会导致这种不一致的状态永久存在了数据库中。这业务能接受吗?但凡有点职业精神的程序员能接受吗?
总结
大型分布式系统犹如一个生命,系统中各个服务犹如骨骼,其中的数据犹如血液,而Kafka犹如经络,串联整个系统。这份Kafka源码笔记通过大量的设计图展示、代码分析、示例分享,把Kafka的实现脉络展示在读者面前,帮助读者更好地研读Kafka代码。
需要免费领取这份Kafka源码笔记的铁汁们,麻烦帮忙转发一下这篇文章+关注我,然后戳这里免费获取!
示、代码分析、示例分享,把Kafka的实现脉络展示在读者面前,帮助读者更好地研读Kafka代码。
需要免费领取这份Kafka源码笔记的铁汁们,麻烦帮忙转发一下这篇文章+关注我,然后戳这里免费获取!

这篇关于不服不行!java管理系统项目连接数据库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






