本文主要是介绍纽约Uber数据分析图形化和K-means计算热点,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
K-means是一种聚类算法,用于将一组样本分成预定数量的簇。它通过计算样本之间的距离,将它们分配到最近的簇中,然后根据分配的结果,更新簇的中心位置。这个过程迭代进行,直到簇的中心位置不再变化或达到预定的迭代次数。
K-means算法的主要步骤包括:
- 随机选择K个簇中心点(代表每个簇的点)
- 对每个样本,计算其与每个簇中心点之间的距离,并将其分配到最近的簇中
- 根据分配的结果,更新每个簇的中心位置(为该簇中所有样本的平均值)
- 重复步骤2和3,直到簇的中心位置不再变化或达到预定的迭代次数
K-means算法的目标是最小化簇内样本之间的方差,同时最大化簇与簇之间的距离,以达到有效的聚类效果。它是一种简单且高效的聚类算法,常用于数据挖掘、图像处理和模式识别等领域。
一、数据
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
import folium #visualize map
import time
from sklearn.cluster import KMeans #k-means clustering
from yellowbrick.cluster import KElbowVisualizer #Elbow visualize K-means计算肘部那个点可视化
import warnings
warnings.filterwarnings('ignore')##忽略警告df_ori = pd.read_csv('uber-raw-data-apr14.csv')
df_ori.info()
'''结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 564516 entries, 0 to 564515
Data columns (total 4 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 Date/Time 564516 non-null object 1 Lat 564516 non-null float642 Lon 564516 non-null float643 Base 564516 non-null object
dtypes: float64(2), object(2)
memory usage: 17.2+ MB
'''df_ori['Base'].unique()
#结果:array(['B02512', 'B02598', 'B02617', 'B02682', 'B02764'], dtype=object)clus_k_ori = df_ori[['Lat', 'Lon']]二、找最佳k
start = time.time()
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from yellowbrick.cluster import KElbowVisualizermodel_ori = KMeans()
visualizer = KElbowVisualizer(model_ori, k = (1, 18)) #k = 1 to 17
visualizer.fit(clus_k_ori)
visualizer.show()
time2=timeend = time.time()
end-start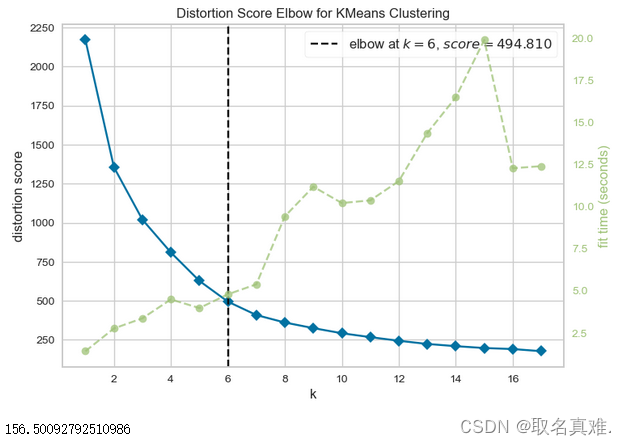
三、建模
kmeans_ori = KMeans(n_clusters = 6, random_state = 0) #k = 6centroids_k_ori = kmeans_ori.cluster_centers_clocation_k_ori = pd.DataFrame(centroids_k_ori, columns = ['Latitude', 'Longitude'])
'''结果:热点中心点经纬度Latitude Longitude
0 40.731107 -73.998625
1 40.659619 -73.774090
2 40.688595 -73.965538
3 40.765525 -73.972847
4 40.700541 -74.201673
5 40.798126 -73.869032
'''plt.scatter(clocation_k_ori['Latitude'], clocation_k_ori['Longitude'], marker = "x", color = 'r', s = 200) 
label_k_ori = kmeans_ori.labels_
df_new_k = df_ori.copy()
df_new_k['Clusters'] = label_k_ori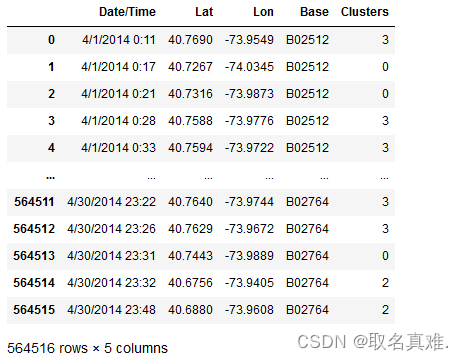
count_2 = 0
count_0 = 0
for value in df_new_k['Clusters']:if value == 2:count_2 += 1if value == 0:count_0 += 1
print(count_0, count_2)
#结果:249352 59942sns.catplot(data = df_new_k, x = "Clusters", kind = "count", height = 7, aspect = 2)##可以看出就算是热点,但是数量不一定一致,差异也可能很大
new_location_ori = [(40.76, -73.99)]#拿一个点预测
kmeans_ori.predict(new_location_ori)
#结果:array([3])
修改时间格式:
df_ori.columns = ['timestamp', 'lat', 'lon', 'base']#修改时间格式import time
ti = time.time()df_ori['timestamp'] = pd.to_datetime(df_ori['timestamp'])tf = time.time()
print(tf-ti,' seconds.')df_ori['weekday'] = df_ori.timestamp.dt.weekday
df_ori['month'] = df_ori.timestamp.dt.month
df_ori['day'] = df_ori.timestamp.dt.day
df_ori['hour'] = df_ori.timestamp.dt.hour
df_ori['minute'] = df_ori.timestamp.dt.minute
根据时间分布 :
## Hourly Ride Data每小时派单量
## groupby operation
hourly_ride_data = df_ori.groupby(['day','hour','weekday'])['timestamp'].count()## reset index
hourly_ride_data = hourly_ride_data.reset_index()## rename column
hourly_ride_data = hourly_ride_data.rename(columns = {'timestamp':'ride_count'})## ocular analysis
hourly_ride_data 
## Weekday Hourly Averages 每周每小时平均派单量
## groupby operation
weekday_hourly_avg = hourly_ride_data.groupby(['weekday','hour'])['ride_count'].mean()## reset index
weekday_hourly_avg = weekday_hourly_avg.reset_index()## rename column
weekday_hourly_avg = weekday_hourly_avg.rename(columns = {'ride_count':'average_rides'})## sort by categorical index
weekday_hourly_avg = weekday_hourly_avg.sort_index()## ocular analysis
weekday_hourly_avg 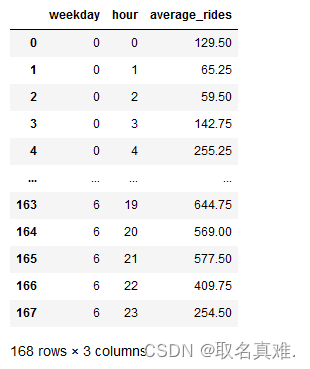
##Define Color Palette
tableau_color_blind = [(0, 107, 164), (255, 128, 14), (171, 171, 171), (89, 89, 89),(95, 158, 209), (200, 82, 0), (137, 137, 137), (163, 200, 236),(255, 188, 121), (207, 207, 207)]for i in range(len(tableau_color_blind)): r, g, b = tableau_color_blind[i] tableau_color_blind[i] = (r / 255., g / 255., b / 255.)## create figure
fig = plt.figure(figsize=(12,6))
ax = fig.add_subplot(111)## set palette
current_palette = sns.color_palette(tableau_color_blind)## plot data
sns.pointplot(ax=ax, x='hour',y='average_rides',hue='weekday', palette = current_palette, data = weekday_hourly_avg)## clean up the legend
l = ax.legend()
l.set_title('')## format plot labels
ax.set_title('Weekday Averages for April 2014', fontsize=30)
ax.set_ylabel('Rides per Hour', fontsize=20)
ax.set_xlabel('Hour', fontsize=20)
散点图分布:
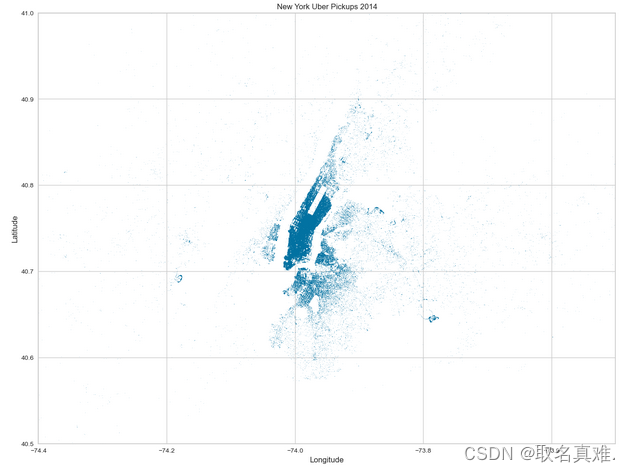
%matplotlib inlineplt.figure(figsize=(16, 12))plt.plot(df_ori.lon, df_ori.lat, '.', ms=.8, alpha=.5)plt.ylim(bottom=40.5,top=41)
plt.xlim(left=-74.4,right=-73.5)plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.title('New York Uber Pickups 2014')plt.show()
这篇关于纽约Uber数据分析图形化和K-means计算热点的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





