本文主要是介绍闵帆老师《论文写作》课后感悟,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、学术论文
- 二、使用Latex工具撰写论文
- 三、论文题目
- 四、论文摘要
- 五、论文关键词
- 六、论文引言
- 七、文献综述
- 八、算法伪代码
- 九、实验部分
- 十、论文结论
- 十一、参考文献
- 十二、其他注意事项
- 总结
前言
本篇文章是学习了本学期《论文写作》课程之后,收获良多。对于论文撰写有了自己的心得体会,故将其会记录于此,以供将来参考学习。
一、学术论文
- 学术论文是对当前研究工作的阶段性总结。
- 学术论文的编写类似于八股文写作。与标新立异的思维不同,论文中的每个部分都有固定的要求,要将正确的内容以正确的形式放在正确的位置。(可以理解为套模板。)
- 写论文先借鉴使用别人的模板写。计算机方面, 可供查阅的顶刊如 :Science, Artificial Intelligence (AI), IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)。
二、使用Latex工具撰写论文
- 每种期刊都会提供一个或多个格式文件,而Latex 源文件只需要进行少量改变, 就可以获得完全不同的版面。并且千万不要使用word来写论文,我在撰写本科毕业论文时,就深刻体会到word的不便利,一会段落间距又不对了,插入的图片格式又出问题了!!总之是困难多多!!!
三、论文题目
- 论文题目必须有吸引力。不炫的论文题目审稿人看了没兴趣。
- 论文题目必须易于理解且长度控制在40-60个字母之间。论文题目必须易于理解才能具有吸引力。如果一个题目看着就让人扣脑壳,那也就不存在吸引力一说了。论文题目长度过长的话,别人读一个名字都读半天,就像我们读外国人名字一样,如果外国人名字太长了,我们读起来也觉得岔气。
- 尽量不使用 based on。“based on” 翻译过来就是"基于",这个名字听起来就是在别人已经做好的东西上做的简单拓展,显得就很low。并且有些中文期刊明确要求论文题目不要使用 “基于”, 因为这种题目泛滥。
- 如果主要贡献为算法, 题目的缩写就应该为算法的名称。
我在浏览词条的时候,也会被很多“标题党”戏耍。但是不得不承认,吸引我点击进去的正是这个标题。对于论文也是同样的道理,毕竟标题选的好,绅士少不了!!!
四、论文摘要
摘要是学术论文中的一部分,是一篇文章的简短概述,通常放在文章开头,但在正文之前。摘要的主要目的是为了让读者在不阅读整篇文章的情况下了解研究的主要内容和结论。摘要通常包括已有工作的评述、本文工作的描述、实验结果三个方面。具体内容可用十句话概况:
- 问题及其重要性。说明问题所属的领域, 解释最重要的概念, 或者强调问题的重要性。
- 已有工作。描述该问题的流行解决方案,即为描述前人所做工作。
- 已有工作的局限性。本句以 However 开头,说明前人工作的不足之处,但是要注意语气注意态度,要给别人足够的respect!
- 本文工作。本句以 In this paper 开头,是对题目的扩展。
- 本文方法的第 1 个技术/步骤/方面/优势/贡献。
- 本文方法的第 2 个技术/步骤/方面/优势/贡献。
- 本文方法的第 3 个技术/步骤/方面/优势/贡献。注意!一定要写够3个方面,不然显得论文工作量不够。
- 实验设置。给出实验数据的领域、来源、数量等信息。
- 实验结果。给出具体的总结性字句,如提高准确性、提升效率等。
- 提升。适当吹嘘一下自己,不要吝啬对自己的夸赞,这是为数不多正大光明夸自己的时候。如:为该领域打开一扇门之类的话。
五、论文关键词
论文关键词通常被看作摘要的一种补充,一般包含3-5个关键词即可。关键词一般由1-3个单词组成。
关键词是用于检索论文的一种重要的方式,虽然现在人们可以进行全文检索, 但关键词仍然很常用。就像在我们日常生活中,通常都会索要关键词进行搜索!
六、论文引言
在计算机英文论文中, Introduction 需要讲述完整的故事。
- 引言是对整个故事详细的描述。如果说摘要是电影5分钟的宣传片,那么引言便是整个电影的剧本。所以在引言部分要把自己重要的内容展现出来,不要藏着掖着。
- 采用八股文的方式。要老老实实的按照与摘要相同的节奏来写。每段应有 5–10 句。这样,该段就有 50-150 个单词。不要耍性格,搞特殊。
- “一幅图胜过千言万语”,该图可以帮助读者花最少的时间理解论文的主要内容。这张图如果画好了,可以加分。 但是如果画不好的话,那就不要。总的来说,就是“开局一张图”,但内容不是靠编。
- 引言的层次要注意没有没有拼写、语法错误(单词级),表达简洁、得体、有力量(句子级),丰富(段落级),条理清晰,节奏明快(章节级)。
在我阅读论文的时候,通常是阅读引言来了解这篇论文是做什么的,做出了什么效果。所以,我们也要把引言写好,当别人阅读到我们论文的时候也能快速找到自己想要的东西,互利互惠!!!
七、文献综述
- 每篇论文都应有文献综述,用于表示对前人工作的尊重, 我们是站在巨人的肩头上。这也是对前人的respect!
- 不要一次性引用太多文献,一次不要超过 3 篇, 否则又是堆砌的感觉。一次性引用太多文献,感觉是敷衍了事,把大家都揉成一团了,这让人觉得你并没有给到足够的respect。
- 不提倡全句引用,同时合理评述相关工作的优缺点。
八、算法伪代码
- 算法伪代码是论文的核心之一。在算法伪代码中需要说明输入、输出,写出主要步骤的注释,同时长度控制在15-30行,不重要的步骤可以省略。一般需要进行时间、空间复杂度分析, 并写出配套的 property 以及相应的表格,以使其更标准。
我在阅读论文的时候,很多时候感觉自己懂得了作者的思想,但是苦于没有办法和代码联系起来。可能是因为现在代码能力还不够,总觉得用代码实现作者思想是一件十分困难的事情。但是论文伪代码可以帮助我解决一些问题,通过看到代码能够使我更加直观的将作者思想和代码连接起来,这对我复现论文有莫大的帮助!
九、实验部分
- 实验部分首先介绍数据集信息。数据集越多,覆盖领域越广,结果就越可信。
- 进行实验就一定少不了对比,没有对比的实验毫无意义。实验的对比又分为:内部比较和外部比较。内部比较包括:展示参数变化所导致的性能变化、展示主要方案与其变种相比的优势。外部比较即为与已有算法进行对比,主要包括:需要比较经典方案, 基准方案, 最先进的方案。展示实验结果很多时候都要使用图表来进行展示,因为图表更加直观。下图展示了一种比较方案:
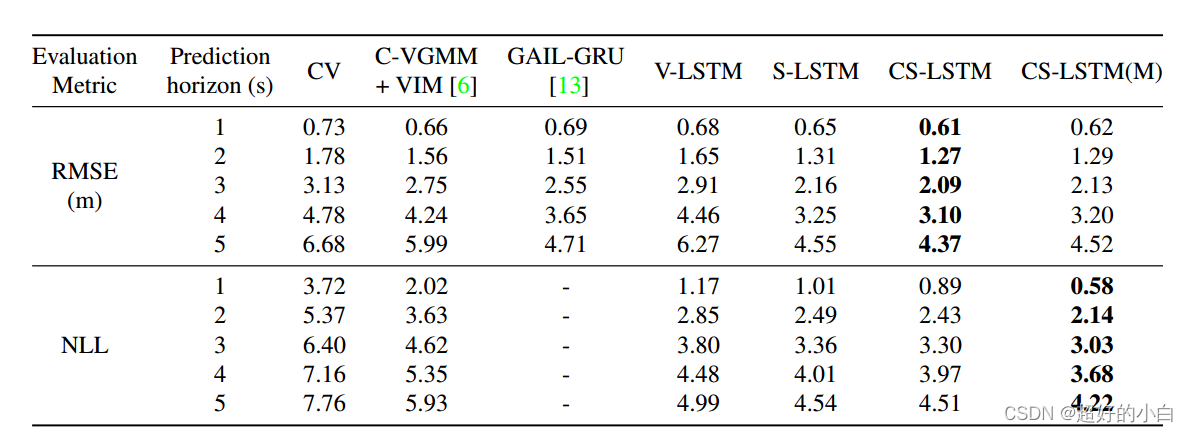
在我自己阅读论文的时候,我更加喜欢实验结果详细充分的论文。自己也有阅读到一些前面理论介绍的很丰富,但是实验部分就潦草结尾,匆匆结束的论文。对于这种论文,当我读到最后我感觉他是在浪费我的时间浪费我的生命。所以实验部分真的很重要,实验部分是一篇论文的重头戏,要认真对待。
十、论文结论
- 论文结论一般不要太长,5句即可。并且要注意与摘要区别开来,摘要里面说我们做了哪些事情, 而这里应该说我们获得哪些观察与结论。
- 如果要讨论说进一步工作,可以列出 3 至 5 条,不算在 Conclusion 的字数里面。如果这一部分写得好,就会有很多的引用,引用数量也比论文发表数量更重要。
当我想要快速浏览一篇论文的时候,首先是要看他的引用摘要部分,如果和我研究方向类似,我便先去浏览最后的结论,而不是去仔细地阅读他的实验方法。所以结论部分要短小精悍更好,让读者能够快速明白你的成果是什么。
十一、参考文献
本以为把前面论文写好,参考文献只是把引用文献的名称放上去那就完事了。但是实际上参考文献的隐藏错误超乎想象。
- 参考文献一定要注意格式要求。千万不要直接使用网上的 bibitem。推荐使用Latex 提供了 bib 文件进行参考文献的管理,极大地减轻了作者的负担。每篇参考文献只需写7-8行,如:
@ARTICLE{MinZhang2020Frequent,author = {Fan Min and Zhi-Heng Zhang and Wen-Jie Zhai and Rong-Ping Shen},title = {Frequent pattern discovery with tri-partition alphabets},journal = {Information Sciences},year = {2020},volume = {507},number = {1},pages = {715--732},doi = {10.1016/j.ins.2018.04.013}
}@INPROCEEDINGS{MinCai2007Dynamic,author = {Fan Min and Hong-Bin Cai and Qi-He Liu and Zhong-Jian Bai},title = {Dynamic discretization: a combination approach},booktitle = {ICMLC},year = {2007},pages = {3672--3677}
}- 最好不要引用不知名的、引用次数较少的、没有阅读过的文献。最好不要把文献全局引用,应挑选有重点且与本论文相关的部分进行引用。
参考文献也是论文的重要组成部分,也要认真对待,站好最后一班岗。
十二、其他注意事项
- 一般而言,未出现在任何学术论文中的单词,不可以使用。
- 注意论文中大小写形式、空格数量、标点符号的使用等。
- 注意英文句子的使用语法。最好是借鉴顶刊顶会论文中的用法。
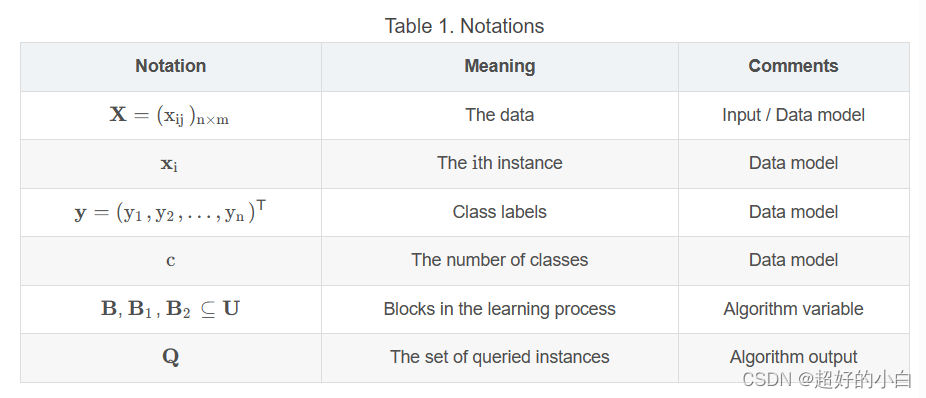
- 数学表达式的使用要正确规范。如果论文涉及不少数学符号, 应该给出一个符号表,便于读者查阅。如下图:
总结
综上,便是我学习《论文写作》课程的感悟。通过这么课程的学习,让我对撰写论文有了更深的认识,也明白了论文中格式的重要性。“写论文就是八股文写作”,闵帆老师课上这句话令我印象深刻。最后感谢老师的悉心教导与辛勤付出!
这篇关于闵帆老师《论文写作》课后感悟的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

