本文主要是介绍Python爬取4K墙纸,想换就换,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
近期换了一个电脑显示屏,需要选择高清照片作为壁纸,于是结合自己平常所学的爬虫爬了一些高清图片来作为壁纸,下图所示:

说明
首先选择一个网址,爬取其中的4K图片,主要工作内容是爬取图片和图片名称,然后保存到本地。

分析
首先我么打开浏览器开发者工具,找到图片的url连接,经过分析可知,图片的url连接在li标签下面的href属性中,我们点开该链接就可以跳转到图片详情中去,但是这里需要注意的是,href属性内容只是url链接的一部分,我们需要对其进行拼装使其组成一个完整的url。
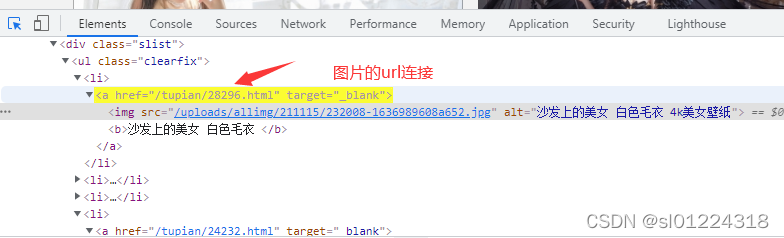
 进入图片详情后,我们再次打开开发者工具,分析并获取图片的url和图片名称,该图片名称在“src”属性中,分析完之后我们用代码来实现图片的爬取。
进入图片详情后,我们再次打开开发者工具,分析并获取图片的url和图片名称,该图片名称在“src”属性中,分析完之后我们用代码来实现图片的爬取。
 实现代码
实现代码
获取图片的详情连接
'''
获取图片的详情连接
'''
def get_url(start_url):#首先获取图片的详情连接和名称response = requests.get(start_url,headers = headers)response.encoding ='gbk'#print(response.text)html = etree.HTML(response.text)#image_name_list = html.xpath('//div//li/a/b/text()') #获取图片名称,返回的是一个lsit# for iamge_name in image_name_list:# #image_name = name.split(' ')# print(iamge_name)url_list = []href_list = html.xpath('//div[@class="slist"]//li/a/@href')for href in href_list:url = 'https://pic.netbian.com' + hrefurl_list.append(url)return url_list获取图片下载链接名称
def parse_detail(url_detail):#获取详情url链接和图片名称#url_detail = 'https://pic.netbian.com/tupian/28396.html'response = requests.get(url_detail,headers = headers)response.encoding ='gbk'html = etree.HTML(response.text)src = 'https://pic.netbian.com' + html.xpath('//div[@class="view"]/div/a/img/@src')[0]alt = html.xpath('//div[@class="view"]/div/a/img/@alt')[0]#print(src,alt)return src,alt图片保存与下载
def make_dir(dirname):#新建文件夹dirname = 'F:\\xunlei5'if not os.path.exists(dirname):os.mkdir(dirname)else:print('该文件已存在')def DownloadImage(src,alt,dirname):#图片下载download_iamge = requests.get(src,headers = headers).contentfilename = dirname + '\\'+ alt + ".jpg"#print(filename)with open(filename.format(alt),'wb') as f:f.write(download_iamge)最后运行代码后,我们就把图片下载到本地了,接下来要做的就是壁纸的慢慢选择了。

总结
以上就是爬取4K壁纸图片的方法,本文章仅供学习交流,不得用于其他用途,有需要完整代码的可私下交流学习。
这篇关于Python爬取4K墙纸,想换就换的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




