本文主要是介绍MindSpore Serving笔记分享,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转载地址:【MindSpore训练营第五期】MindSpore Serving笔记分享_MindSpore_昇腾论坛_华为云论坛
作者:Jack20
【MindSpore训练营第五期】MindSpore Serving笔记分享
一键部署在线推理服务
--MindSpore Serving
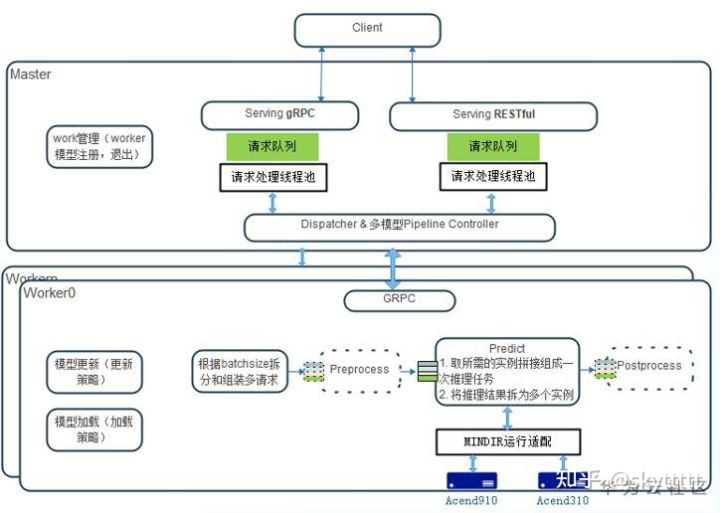
MindSpore Serving就是为实现将深度学习部署到生产环境而产生的
MindSpore Serving是一个简单易用、高性能的服务模块,旨在帮助MindSpore开发者在生产环境中高效部署在线推理服务
注:MindSpore Serving当前仅支持Ascend 310和Ascend 910环境。大家可以在MindSpore官网下载对应版本安装包实践:https://www.mindspore.cn/versions
特点
(1)简单易用
提供Python接口配置和启动Serving服务,对客户端提供gRPC和RESTful访问接口,提供Python客户端接口,通过它,大家可以轻松定制、发布、部署和访问模型服务。
安装:
pip install mindspore_serving-1.1.0-cp37-cp37m-linux_aarch64.whl
1.轻量级部署
服务端调用Python接口直接启动推理进程(master和worker共进程),客户端直接连接推理服务后下发推理任务。 执行master_with_worker.py,完成轻量级部署服务:
import os
from mindspore_serving import master
from mindspore_serving import worker
def start():
servable_dir = os.path.abspath(".")
worker.start_servable_in_master(servable_dir, "add", device_id=0)
master.start_grpc_server("127.0.0.1", 5500)
if __name__ == "__main__":
start()
当服务端打印日志Serving gRPC start success, listening on 0.0.0.0:5500时,表示Serving服务已加载推理模型完毕。
2.集群部署
服务端由master进程和worker进程组成,master用来管理集群内所有的worker节点,并进行推理任务的分发。
部署master:
import os from mindspore_serving import master def start(): servable_dir = os.path.abspath(".") master.start_grpc_server("127.0.0.1", 5500) master.start_master_server("127.0.0.1", 6500) if __name__ == "__main__": start()
部署worker:
import os from mindspore_serving import worker def start(): servable_dir = os.path.abspath(".") worker.start_servable(servable_dir, "add", device_id=0, master_ip="127.0.0.1", master_port=6500, worker_ip="127.0.0.1", worker_port=6600) if __name__ == "__main__": start()
轻量级部署和集群部署启动worker所使用的接口存在差异,其中,轻量级部署使用start_servable_in_master接口启动worker,集群部署使用start_servable接口启动worker。(2)提供定制化服务
支持模型供应商打包发布模型、预处理和后处理,围绕模型提供定制化服务,并一键部署,服务使用者不需要感知模型处理细节。
举个栗子:实现导出两个tensor相加操作的模型
import os from shutil import copyfile import numpy as np import mindspore.context as context import mindspore.nn as nn import mindspore.ops as ops import mindspore as ms context.set_context(mode=context.GRAPH_MODE, device_target="Ascend") class Net(nn.Cell): """Define Net of add""" def __init__(self): super(Net, self).__init__() self.add = ops.TensorAdd() def construct(self, x_, y_): """construct add net""" return self.add(x_, y_) def export_net(): """Export add net of 2x2 + 2x2, and copy output model `tensor_add.mindir` to directory ../add/1""" x = np.ones([2, 2]).astype(np.float32) y = np.ones([2, 2]).astype(np.float32) add = Net() output = add(ms.Tensor(x), ms.Tensor(y)) ms.export(add, ms.Tensor(x), ms.Tensor(y), file_name='tensor_add', file_format='MINDIR') dst_dir = '../add/1' try: os.mkdir(dst_dir) except OSError: pass dst_file = os.path.join(dst_dir, 'tensor_add.mindir') copyfile('tensor_add.mindir', dst_file) print("copy tensor_add.mindir to " + dst_dir + " success") print(x) print(y) print(output.asnumpy()) if __name__ == "__main__": export_net()
构造一个只有Add算子的网络,并导出MindSpore推理部署模型,该模型的输入为两个shape为[2,2]的二维Tensor,输出结果是两个输入Tensor之和。
(3)支持批处理
用户一次请求可发送数量不定样本,Serving分割和组合一个或多个请求的样本以匹配模型的实际batch,不仅仅加速了Serving请求处理能力,并且也简化了客户端的使用。
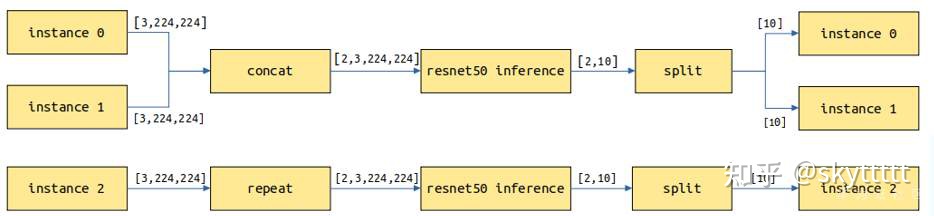
主要针对处理图片、文本等包含batch维度的模型。假设batch_size=2,当前请求有3个实例,共3张图片,会拆分为2次模型推理,第1次处理2张图片返回2个结果,第2次对剩余的1张图片进行拷贝做一次推理并返回1个结果,最终返回3个结果。
对于一个模型,假设其中一个输入是数据输入,包括batch维度信息,另一个输入为模型配置信息,没有包括batch维度信息,此时在设置with_batch_dim为True基础上,设置额**数without_batch_dim_inputs指定没有包括batch维度信息的输入信息。
from mindspore_serving.worker import register # Input1 indicates the input shape information of the model, without the batch dimension information. # input0: [N,3,416,416], input1: [2] register.declare_servable(servable_file="yolov3_darknet53.mindir", model_format="MindIR", with_batch_dim=True, without_batch_dim_inputs=1)
(4) 高性能高扩展
支持多模型多卡并发,通过client/master/worker的服务体系架构,实现MindSpore Serving的高性能和高扩展性。
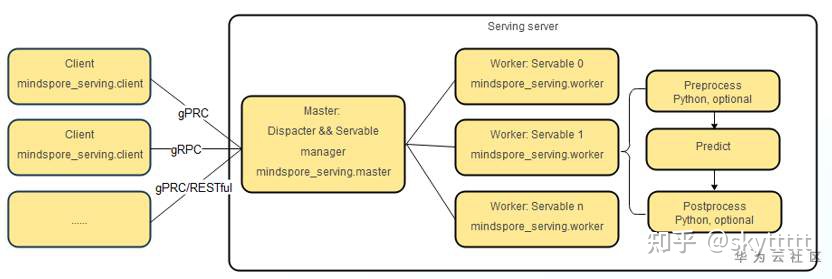
华为Ascend主打芯片低功耗、高算力等特性,MindSpore提供高效的内核算法、自动融合,自动并行等能力。支持多模型多卡并发,通过client/master/worker的服务体系架构,实现MindSpore Serving的高性能和高扩展性。
高可靠性设计(某个服务节点宕机,不影响客户端正常服务),负载均衡(如何更合理的使用所有资源信息),弹性扩容缩容(根据业务的高峰低谷,动态调整资源)
参考
[1]www.mindspore.cn
[2]gitee.com/mindspore
[3]github.com/mindspore-ai
这篇关于MindSpore Serving笔记分享的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




