nova-compute
nova-compute 在计算节点上运行,负责管理节点上的 instance。
OpenStack 对 instance 的操作,最后都是交给 nova-compute 来完成的。
nova-compute 与 Hypervisor 一起实现 OpenStack 对 instance 生命周期的管理。
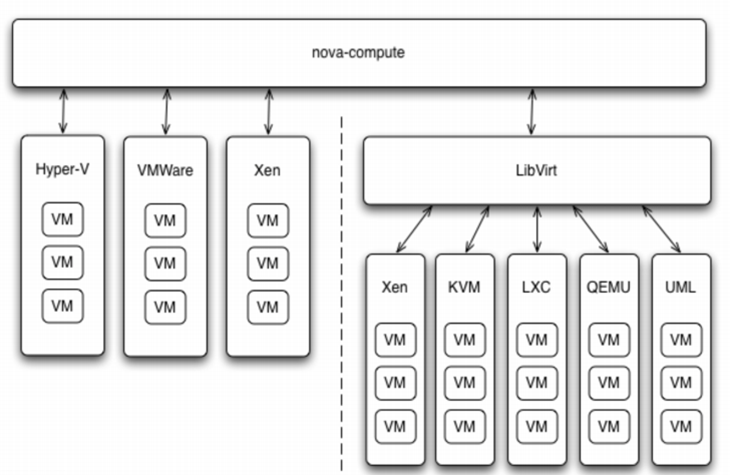
通过 Driver 架构支持多种 Hypervisor
nova-compute 为这些 Hypervisor 定义了统一的接口,Hypervisor 只需要实现这些接口,就可以 Driver 的形式即插即用到 OpenStack 系统中。
下面是Nova Driver的架构示意图:
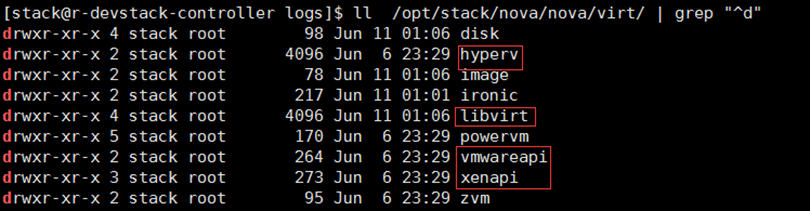
我们可以在 /opt/stack/nova/nova/virt/ 目录下查看到 OpenStack 源代码中已经自带了上面这几个 Hypervisor 的 Driver
某个特定的计算节点上只会运行一种 Hypervisor,只需在该节点 nova-compute 的配置文件 /etc/nova/nova.conf 中配置所对应的 compute_driver 就可以了。
在我们的环境中因为是 KVM,所以配置的是 Libvirt 的 driver。
compute_driver = libvirt.LibvirtDriver
nova-compute 的功能可以分为两类:
1、定时向 OpenStack 报告计算节点的状态
2、实现 instance 生命周期的管理
定期向 OpenStack 报告计算节点的状态
nova-scheduler 的很多 Filter 是根据算节点的资源使用情况进行过滤的。
比如 RamFilter 要检查计算节点当前可以的内存量;
CoreFilter 检查可用的 vCPU 数量;
DiskFilter 则会检查可用的磁盘空间。
nova-compute 会把计算节点的信息定期上报给 OpenStack 。
从 nova-compute 的日志 /opt/stack/logs/n-cpu.log 可以发现: 每隔一段时间,nova-compute 就会报告当前计算节点的资源使用情况和 nova-compute 服务状态。

nova-compute 可以通过 Hypervisor 的 driver 获取当前节点上所有 instance 的资源占用信息。
举例来说:
在实验环境下 Hypervisor 是 KVM,用的 Driver 是 LibvirtDriver。
LibvirtDriver 可以调用相关的 API 获得资源信息,这些 API 的作用相当于在 CLI 里执行 virsh nodeinfo、virsh dominfo 等命令。
实现 instance 生命周期的管理
OpenStack 对 instance 最主要的操作都是通过 nova-compute 实现的,包括 instance 的 launch、shutdown、reboot、suspend、resume、terminate、resize、migration、snapshot 等。
当 nova-scheduler 选定了部署 instance 的计算节点后,会通过消息中间件 rabbitMQ 向选定的计算节点发出 launch instance 的命令。
该计算节点上运行的 nova-compute 收到消息后会执行 instance 创建操作。
日志 /opt/stack/logs/n-cpu.log 记录了整个操作过程。
nova-compute 创建 instance 的过程可以分为 4 步:
1、为 instance 准备资源
2、创建 instance 的镜像文件
3、创建 instance 的 XML 定义文件
4、创建虚拟网络并启动虚拟机
1、为 instance 准备资源
nova-compute 首先会根据指定的 flavor 依次为 instance 分配内存、磁盘空间和 vCPU。
可以在日志中看到这些细节
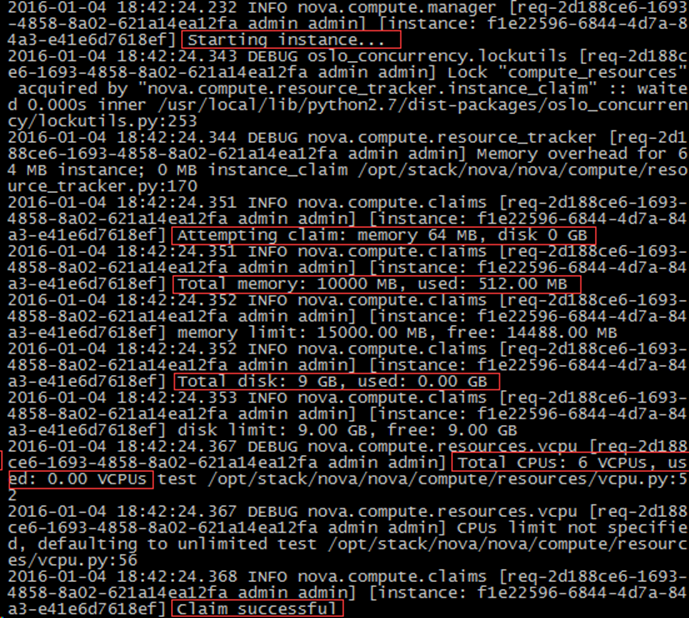
网络资源也会提前分配。

2、创建 instance 的镜像文件
资源准备好之后,nova-compute 会为 instance 创建镜像文件。
OpenStack 启动一个 instance 时,会选择一个 image,这个 image 由 Glance 管理。 nova-compute会:
1、首先将该 image 下载到计算节点
2、然后将其作为 backing file 创建 instance 的镜像文件
从 Glance 下载 image
nova-compute 首先会检查 image 是否已经下载(比如之前已经创建过基于相同 image 的 instance)。
如果没有,就从 Glance 下载 image 到本地。
由此可知,如果计算节点上要运行多个相同 image 的 instance,只会在启动第一个 instance 的时候从 Glance 下载 image,后面的 instance 启动速度就大大加快了。
日志如下:

可以看到:
1、image(ID为 917d60ef-f663-4e2d-b85b-e4511bb56bc2)是 qcow2 格式,nova-compute 将其下载。
Nova 默认会通过 qemu-img 转换成 raw 格式,以提高 IO 性能。
2、image 的存放目录是 /opt/stack/data/nova/instances/_base,这是由 /etc/nova/nova.conf 的下面两个配置选项决定的。
instances_path = /opt/stack/data/nova/instances
base_dir_name = _base
3、下载的 image 文件被命名为 60bba5916c6c90ed2ef7d3263de8f653111dd35f,这是 image id 的 SHA1 哈希值。
3、为 instance 创建镜像文件
有了 image 之后,instance 的镜像文件直接通过 qemu-img 命令创建,backing file 就是下载的 image。

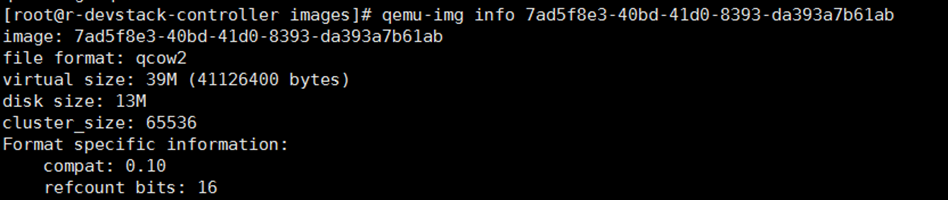
这里 instance 的镜像文件位于 /opt/stack/data/glance/images/7ad5f8e3-40bd-41d0-8393-da393a7b61ab,格式为 qcow2,其中 7ad5f8e3-40bd-41d0-8393-da393a7b61ab 就是 instance 的 id。
可以通过 qume-img info 查看 disk 文件的属性
这两个容易搞混淆:
1、image,指的是 Glance 上保存的镜像,作为 instance 运行的模板。
计算节点将下载的 image 存放在 /opt/stack/data/glance/images 目录下。
2、镜像文件,指的是 instance 启动盘所对应的文件
3、二者的关系是:image 是镜像文件 的 backing file。
image 不会变,而镜像文件会发生变化。
比如安装新的软件后,镜像文件会变大。
因为英文中两者都叫 “image”,为避免混淆,这里用 “image” 和 “镜像文件” 作区分。
3、创建 instance 的 XML 定义文件

创建的 XML 文件会保存到该 instance 目录 /opt/stack/data/nova/instances/f1e22596-6844-4d7a-84a3-e41e6d7618ef,命名为 libvirt.xml
4、创建虚拟网络并启动 instance
接下来便是为 instance 创建虚拟网络设备

linux-bridge 来实现的虚拟网络,一切就绪,接下来可以启动 instance 了。


至此,instance 已经成功启动。
OpenStack 图形界面和 KVM CLI 都可以查看到 instance 的运行状态。
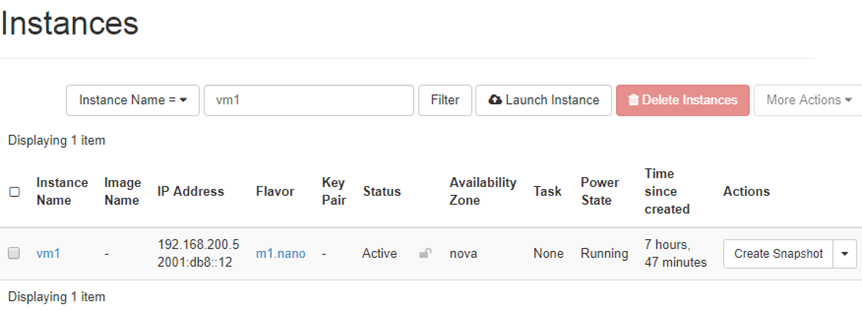

在计算节点上,instance 并不是以 OpenStack上的名字命名,而是采用 instance-xxxxx 的格式。
----------------------------------------------引用来自--------------------------------------------------
https://www.cnblogs.com/CloudMan6/p/5451276.html
https://mp.weixin.qq.com/s?__biz=MzIwMTM5MjUwMg==&mid=2653587838&idx=1&sn=d9086010c7c1b6d2cf7bb5668dae6e00&chksm=8d308167ba47087114eeeac94add3dc9f642501fd22975b57fb193c92bd0b303375a046fff37&scene=21#wechat_redirect






