本文主要是介绍阿亮的算法之路——3. 无重复字符的最长子串,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
非科班,没学过数据结构与算法,但想在这方面有所提升。在不耽误正式课程的学习下,先从简单的做起,尽可能的每天做一道算法题(鉴于做算法题太花费时间,改为一周三道)。原则上先完成后完美,以先满足需要,实现功能为目的,然后再进行优化,查看解析、查看大佬的思路。
题目详情

题目链接:https://leetcode-cn.com/problems/longest-substring-without-repeating-characters/
第一次完成
想了大半天,写出了大概雏形。然后各种修修改改,提交了十来次之后,终于通过了
public int lengthOfLongestSubstring(String s){if ("".equals(s)){ return 0; }int max = 1;int len = s.length();int ind = 0;boolean eq = true;boolean eq1 = true;a:for (int i = 1; i < len; i++){for (int j = i-1; j >=ind ; j--){eq1 = true;if (s.charAt(i) == s.charAt(j) ){eq = false;eq1 = false;max = max > (i -j)?max:(i -j );ind = j+1;continue a;}}if (eq1){max = max > (i -ind+1)?max:(i -ind+1 );}if (eq){max = i+1;}}return max;}
虽然通过了执行提交都通过了,但是,有点磕碜的是:

我的大概思路是:用两层for循环,外层从字符串的第二个字符开始遍历,遍历到字符串的结尾。内层循环从外层循环开始的前一个字符往前遍历,直到与字符串的首字符或者到达了内层循环的结束条件或者与当前外层循环的字符重复,根据得到的大小对最大长度进行更新,并且跳过外层的当前循环,直接进行外层的下次循环。
另外,有三个标志,int类型的ind代表的是内层循环的结束条件,为什么会有这个标志呢?例如:acacbdk,当外层循环到了第六个字符“d”,内层循环就会从第五个字符“b”往回遍历,但是需要一直遍历到首字符吗?显然不是的,而只需要遍历到上一次出现重复字符的前面那个位置,也就是第二个字符即可。
boolean类型的eq作用是,在整个遍历过程中,重现第一个重复字符之前的,用来更新最长长度的。只要出现过一次重复的字符,那么出现重复字符之后的过程,这个标记都用不着了,只是在出现重复字符之前有用。
boolean类型的eq1是用来代表每次内存循环中,是否出现过重复字符,如果没出现,那么更新长度。
大佬思路:力扣官方给的题解:
思路和算法
我们先用一个例子来想一想如何在较优的时间复杂度内通过本题。
我们不妨以示例一中的字符串 \texttt{abcabcbb}abcabcbb 为例,找出 从每一个字符开始的,不包含重复字符的最长子串,那么其中最长的那个字符串即为答案。对于示例一中的字符串,我们列举出这些结果,其中括号中表示选中的字符以及最长的字符串:
以 (a)bcabcbb 开始的最长字符串为 (abc)abcbb;
以 a(b)cabcbb 开始的最长字符串为 a(bca)bcbb;
以 ab(c )abcbb 开始的最长字符串为 ab(cab)cbb;
以 abc(a)bcbb 开始的最长字符串为 abc(abc)bb;
以 abca(b)cbb 开始的最长字符串为 abca(bc)bb;
以 abcab( c)bb 开始的最长字符串为 abcab(cb)b;
以 abcabc(b)b 开始的最长字符串为 abcabc(b)b;
以 abcabcb(b) 开始的最长字符串为 abcabcb(b)。
发现了什么?如果我们依次递增地枚举子串的起始位置,那么子串的结束位置也是递增的!这里的原因在于,假设我们选择字符串中的第 k 个字符作为起始位置,并且得到了不包含重复字符的最长子串的结束位置为 rk 。那么当我们选择第k+1 个字符作为起始位置时,首先从 k+1 到 rk的字符显然是不重复的,并且由于少了原本的第 k 个字符,我们可以尝试继续增大rk,直到右侧出现了重复字符为止。
这样以来,我们就可以使用「滑动窗口」来解决这个问题了:
-
我们使用两个指针表示字符串中的某个子串(的左右边界)。其中左指针代表着上文中「枚举子串的起始位置」,而右指针即为上文中的rk;
-
在每一步的操作中,我们会将左指针向右移动一格,表示 我们开始枚举下一个字符作为起始位置,然后我们可以不断地向右移动右指针,但需要保证这两个指针对应的子串中没有重复的字符。在移动结束后,这个子串就对应着 以左指针开始的,不包含重复字符的最长子串。我们记录下这个子串的长度;
-
在枚举结束后,我们找到的最长的子串的长度即为答案。
判断重复字符
在上面的流程中,我们还需要使用一种数据结构来判断 是否有重复的字符,常用的数据结构为哈希集合(即 C++ 中的 std::unordered_set,Java 中的 HashSet,Python 中的 set, JavaScript 中的 Set)。在左指针向右移动的时候,我们从哈希集合中移除一个字符,在右指针向右移动的时候,我们往哈希集合中添加一个字符。
至此,我们就完美解决了本题。
--------------------------------------------------------------------
我按照这个思路,写出了代码:
public int lengthOfLongestSubstring(String s){if ("".equals(s)){ return 0; }if(" ".equals(s) || s.length() == 1){ return 1; }HashSet<Character> set = new HashSet<>();int max = set.size();int length = s.length();a:for (int i = 0; i < length; i++){for (int j = i; j < length; j++ ){if (!set.add(s.charAt(j))){max = max > set.size()?max:set.size();set.clear();continue a;}}}return max;}
提交也能通过,看起来也比我自己一开始写的那个容易理解了,但是
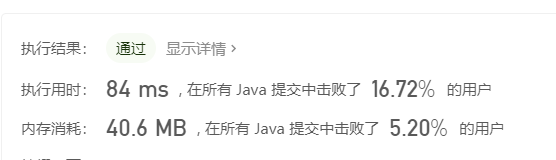
内存消耗差不多,但是执行时间就比我自己写的那个多了好几倍,应该是我理解错了。
我直接把官方给的题解代码提交

内存方面也太差了,速度也没有很优秀,看来刷题的都是些大佬啊。
这篇关于阿亮的算法之路——3. 无重复字符的最长子串的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









