本文主要是介绍SPL性能提升-单键值查找,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一.介绍
集算器是一款程序化数据运算工具,它能够执行各类数据分析与结构化计算,也可以自由访问数据库,完成在线数据分析。

支持各种数据源混合查询,离散与集合的充分结合,超强有序计算,提倡分步计算
官网:http://www.scudata.com.cn/
二.准备
1.下载学习资源:http://www.raqsoft.com.cn/wx/course-performance-optimizing.html
2.安装完毕打开集算器,设置seek为主目录
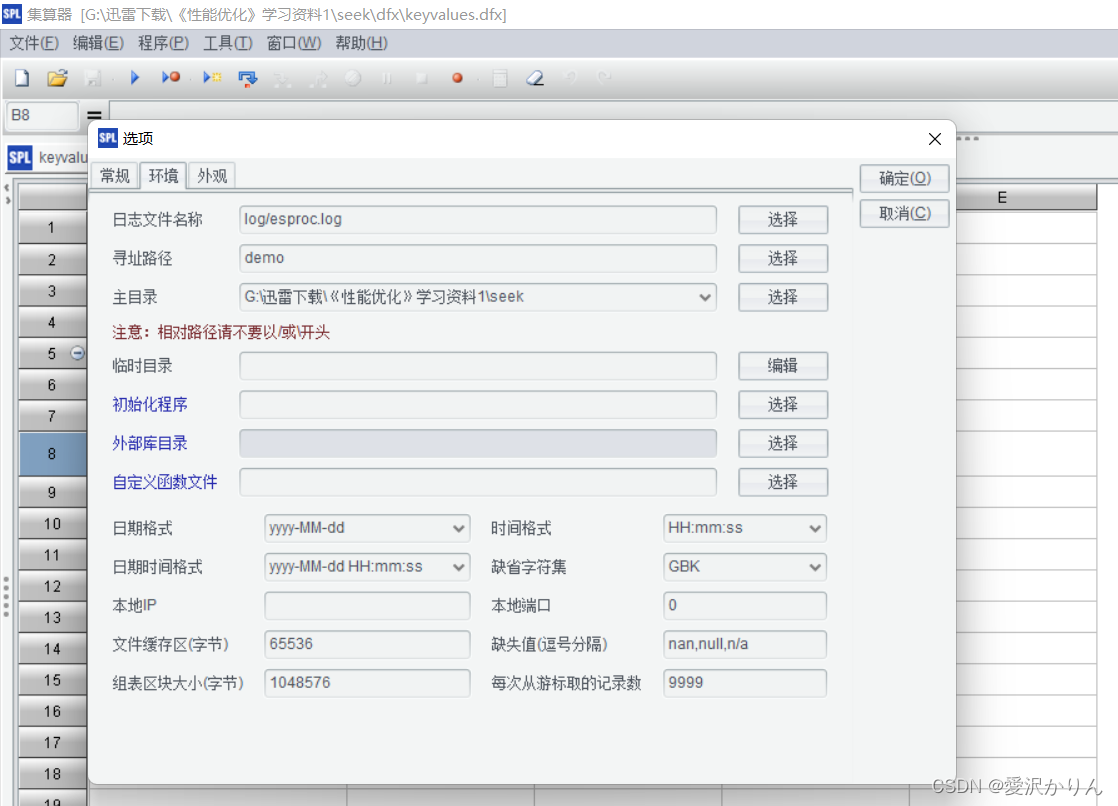
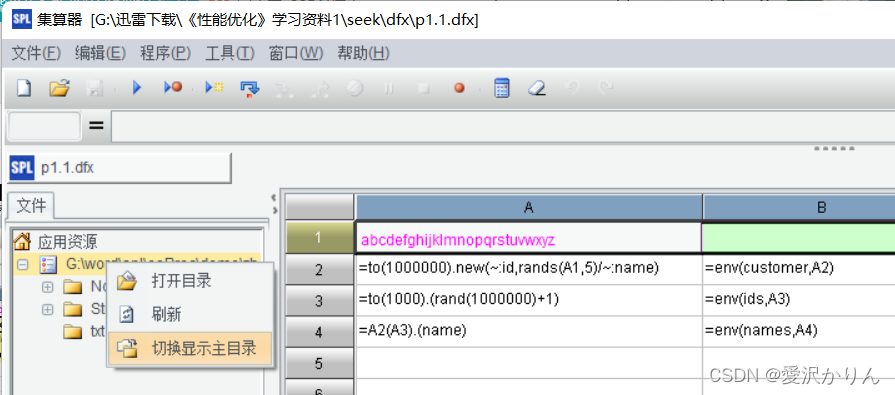
3.切换到主目录
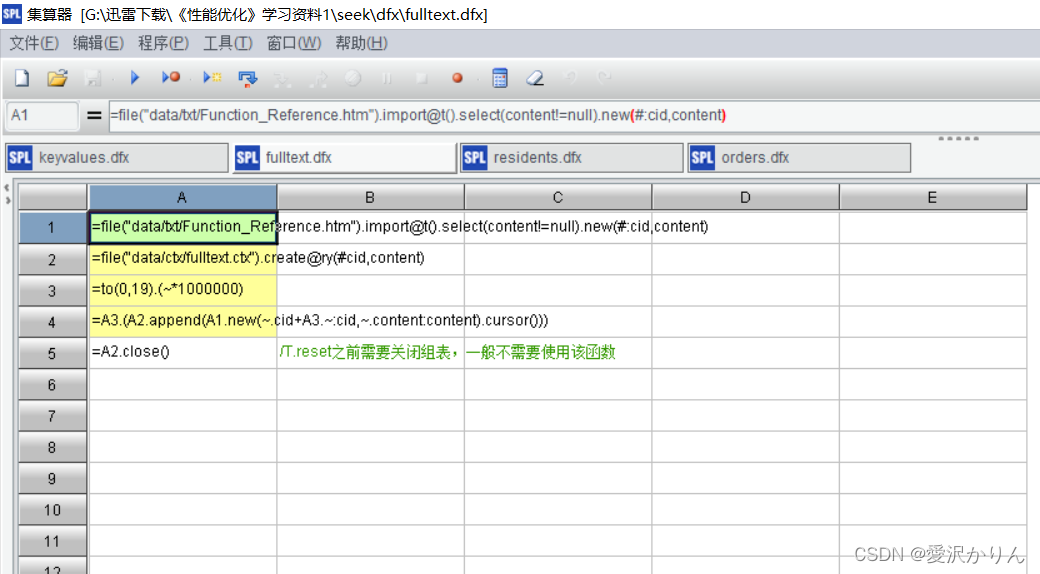
4.执行脚本
1、“主目录\dfx\orders.dfx”,生成订单集文件"主目录\data\btx\orders.btx"。
2、“主目录\dfx\residents.dfx”,生成居民集文件"主目录\data\btx\residents.btx"
3、“主目录\dfx\fulltext.dfx”,生成全文检索组文件"主目录\data\ctx\fulltext.ctx"“。
4、“主目录\dfx\keyvalues.dfx”,生成键值组文件"主目录\data\ctx\col.ctx”"。
三.内存-单键值查找
一.准备数据
执行p1.1.dfx,生成一百万数据量的客户序表customer,并随机取出1000个id、name

二.内存-二分法
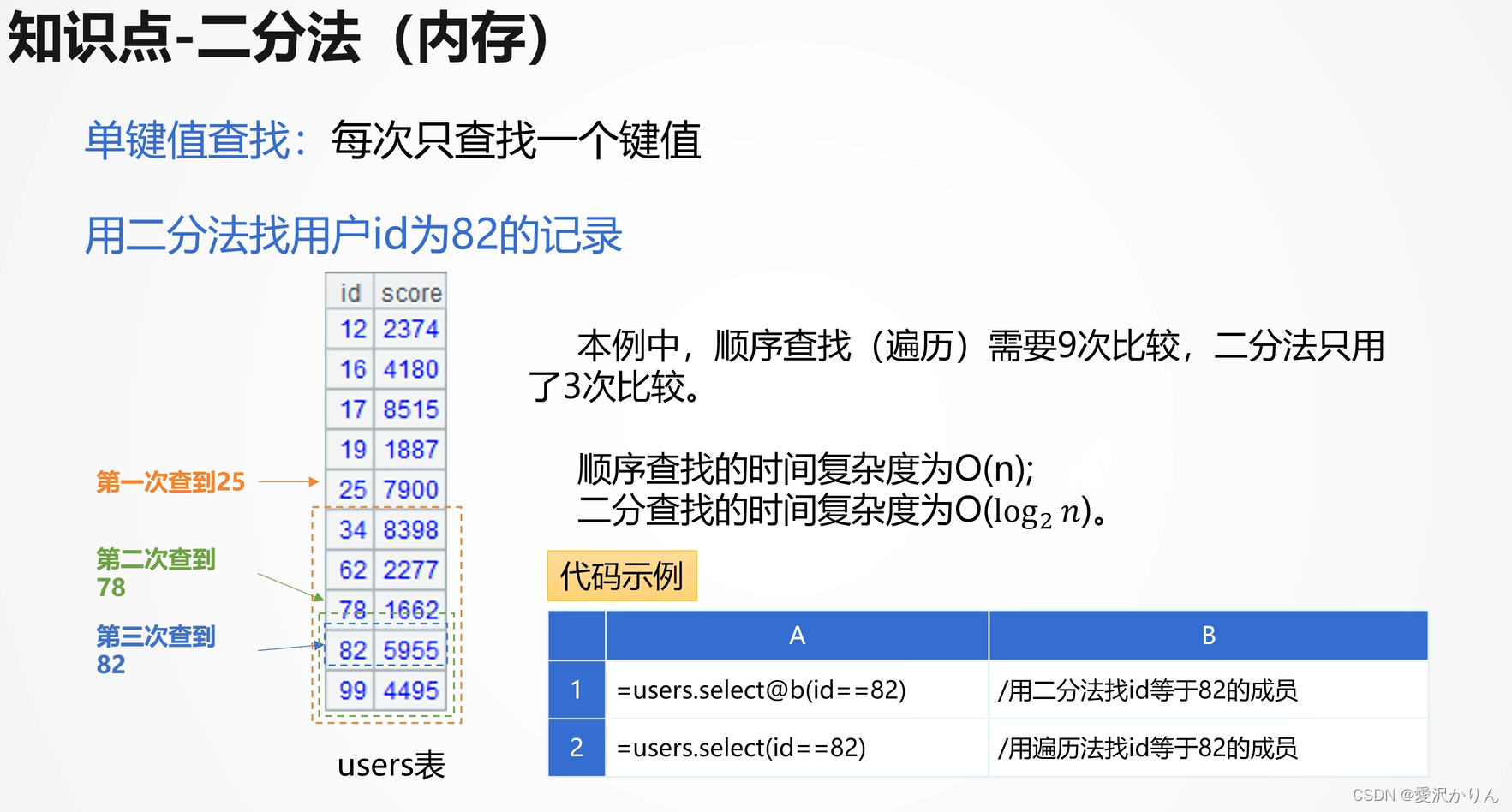
1.打开p1.2.dfx,用顺序查找,记录执行时间

2.打开p1.2.dfx,用二分法改写,记录执行时间

注意:二分法找name是不行的,二分法查找的必须是有序的集合
=customer.select@b(name= ="Luke")
三.序号定位

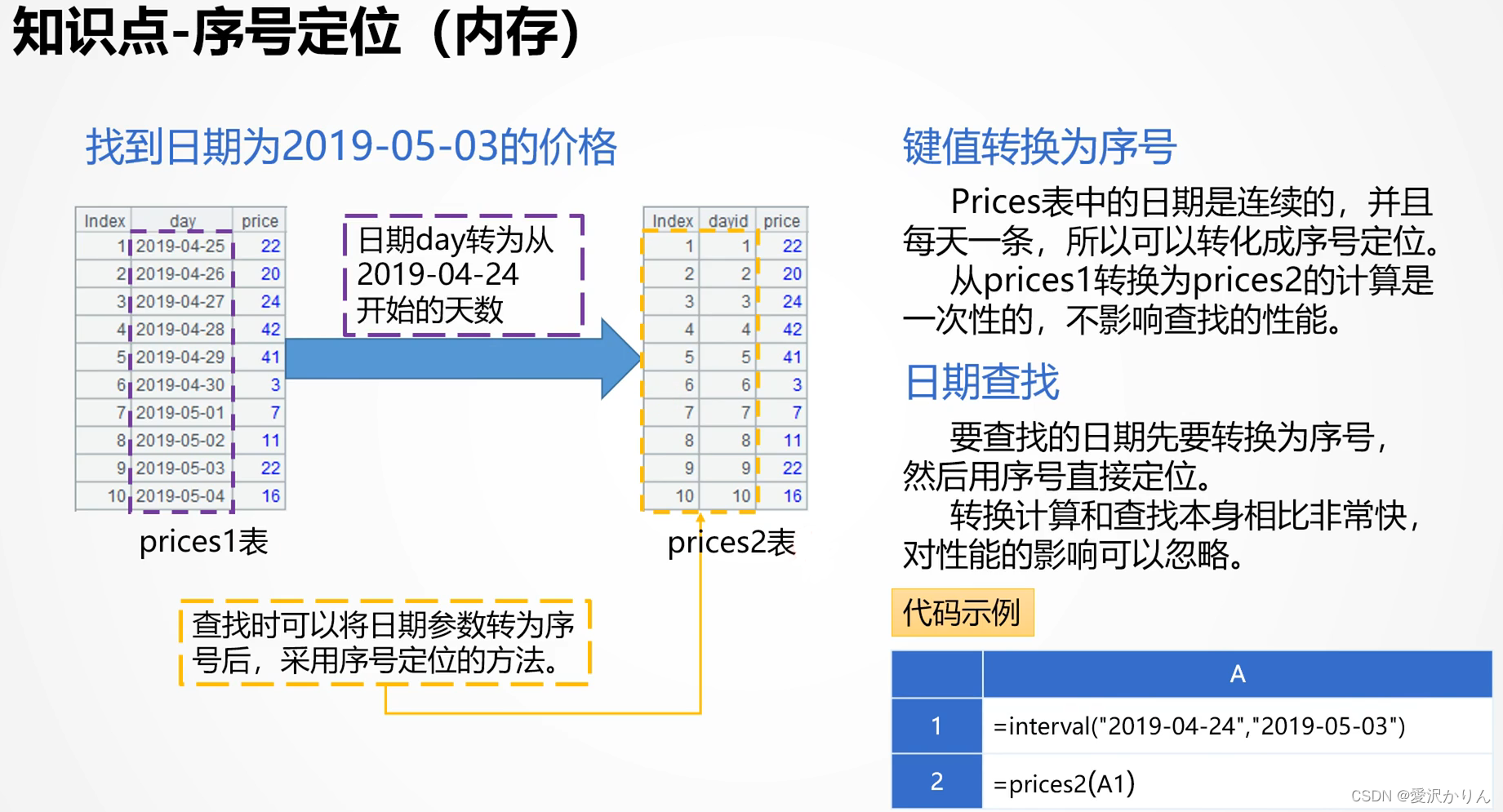
1.打开p1.3.dfx,用序号定位法改写,比较执行时间

注意:基于无序集合理论的关系数据库,没有提供序号定位的手段,即使可以用序号定位时也只能用主键查找
四.哈希索引
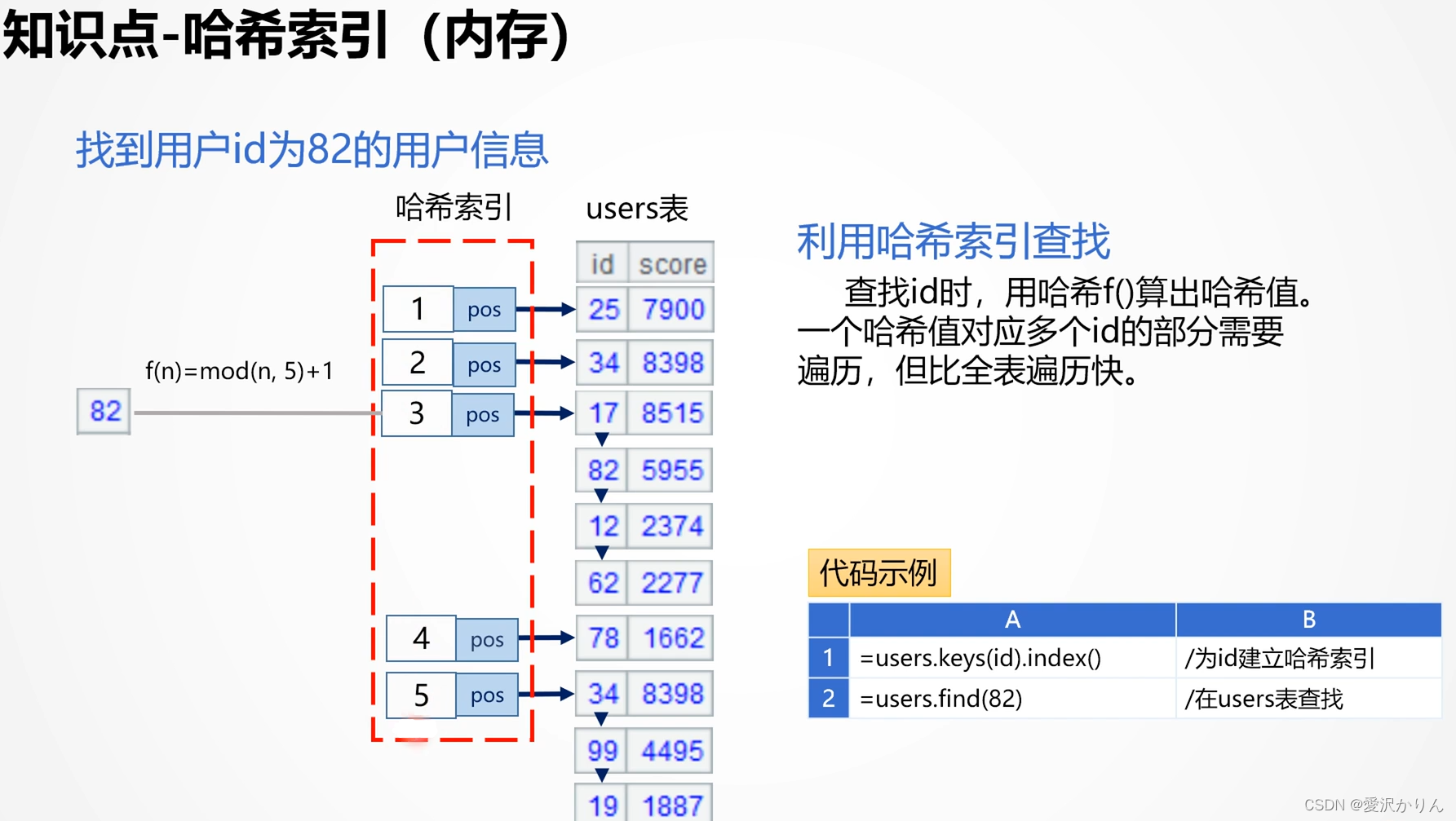
索引越长,产生哈希冲突的概率越小,查找速度越快,但占用内存越大
索引长度缺省:原序列长度和2000万的较小值。当users表长度为100万的时候,索引长度缺省就是100万,哈希值重复的情况就很少了。
1.打开p1.4.dfx,用哈希索引改写
我们的数据是100w,所以索引缺省值是100w,冲突率小,查询快
2.将A2的index()改为index(10000),强行修改索引缺省值

可以看到缺省值小了,哈希冲突概率增大,查询效率变低
四.位置索引
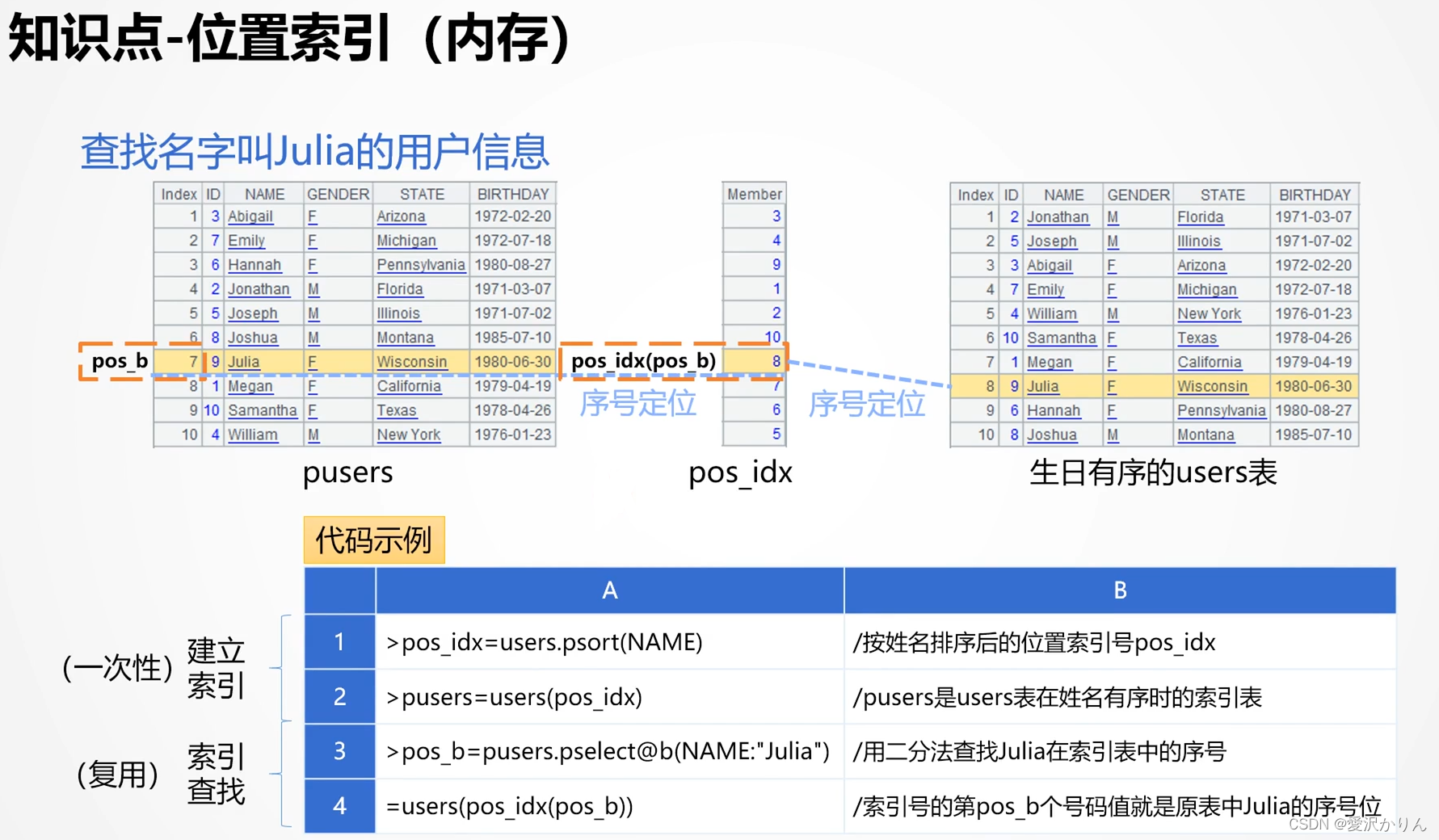
1.打开p1.5.dfx-文件,观察遍历查找的写法,记录执行时间

2.改写为位置索引法查找

五.多层序号查找
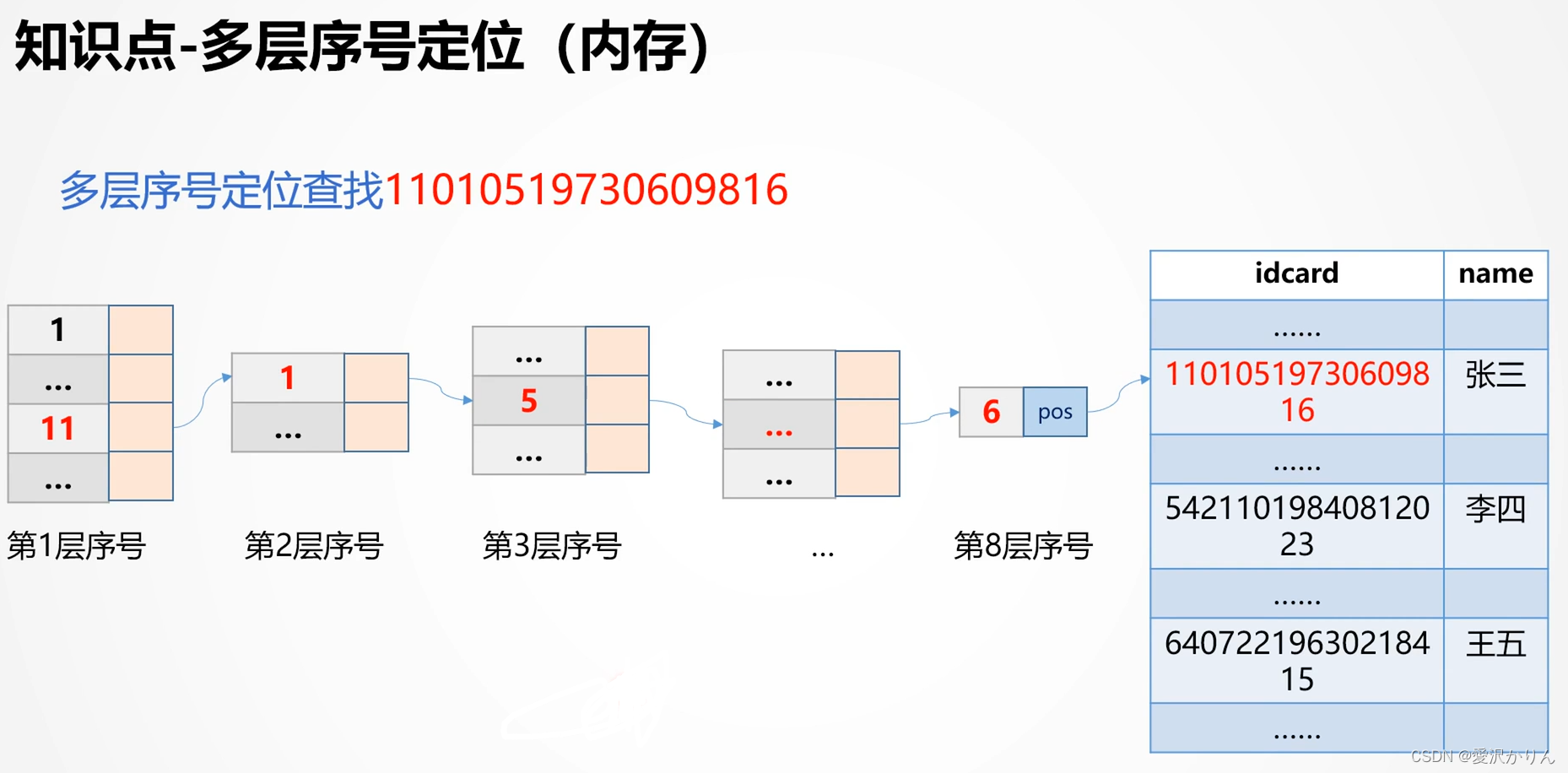
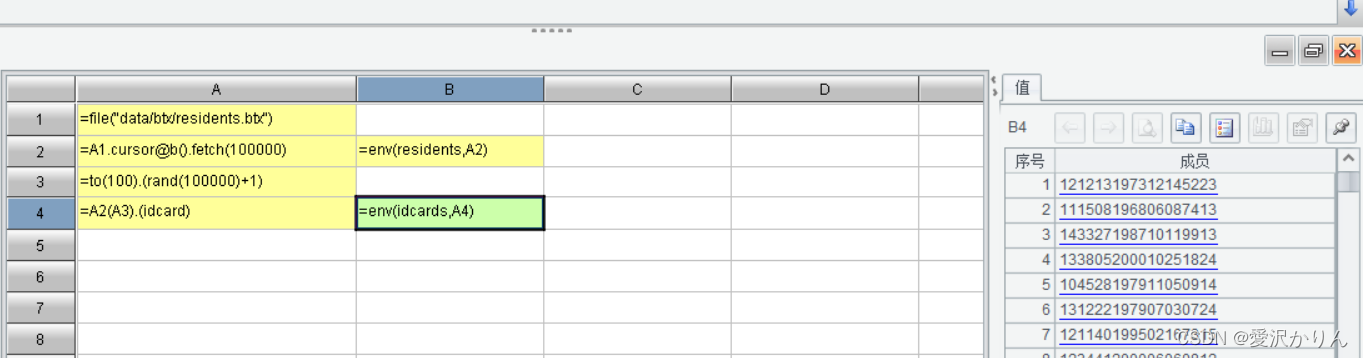
1.打开p1.6.dfx,居民表residents取出十万条数据,idcards随机取出100个idcard身份证号
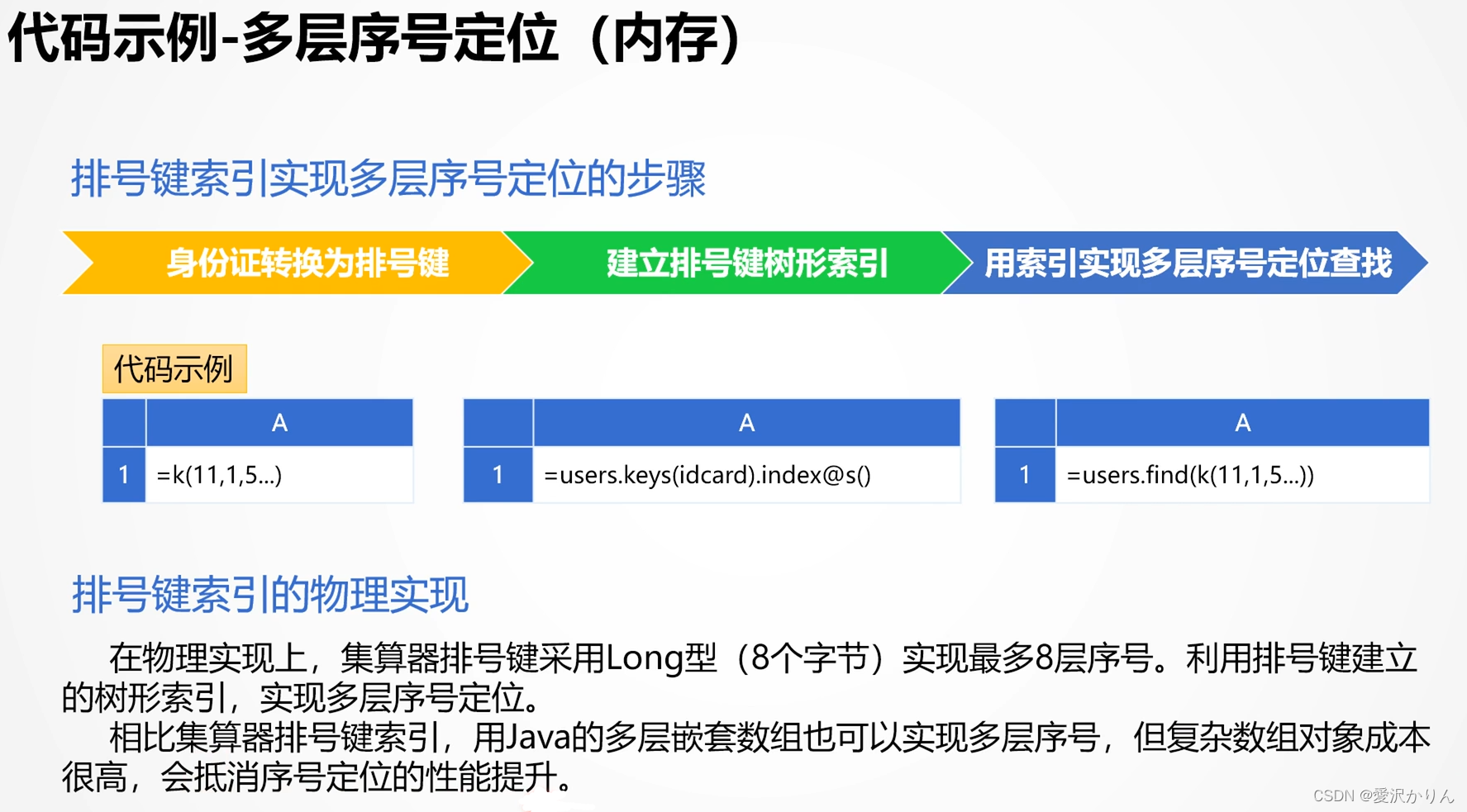
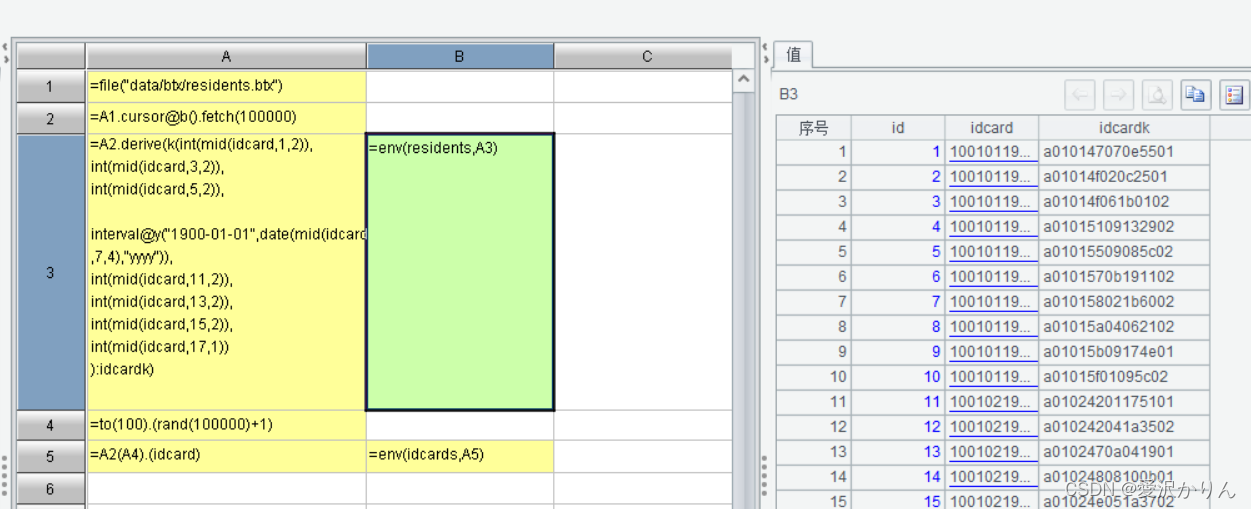
2.身份证号前十四位转换为排号键代码如下,补全剩下的三位转换代码
六.多层序号与限制长度哈希索引对比
1.打开p1.8.dfx,利用长度1000的哈希索引查找10000次
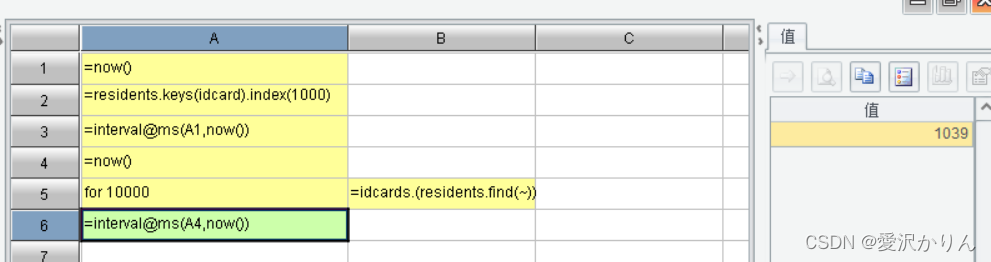
2.改写p1.8.dfx,将residents主键改为idcardk,哈希索引改为排号键索引
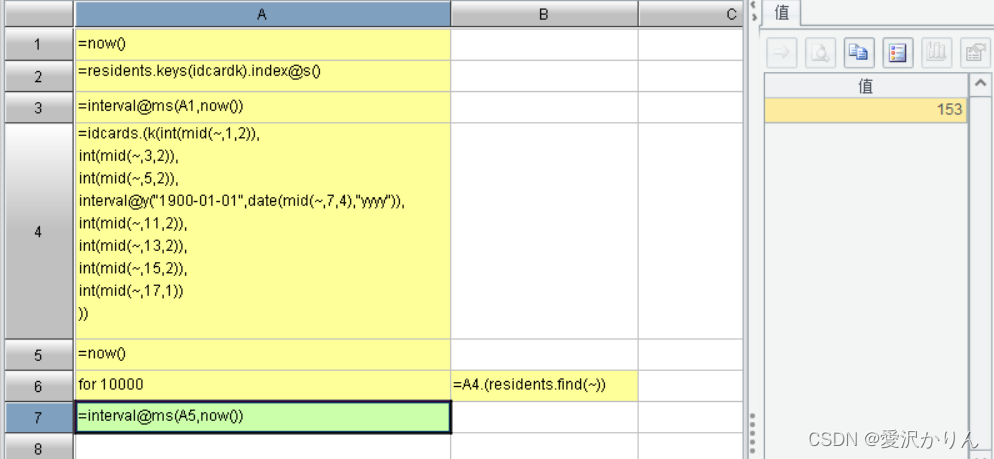
四.外存-单键值查找
一.外存-二分法
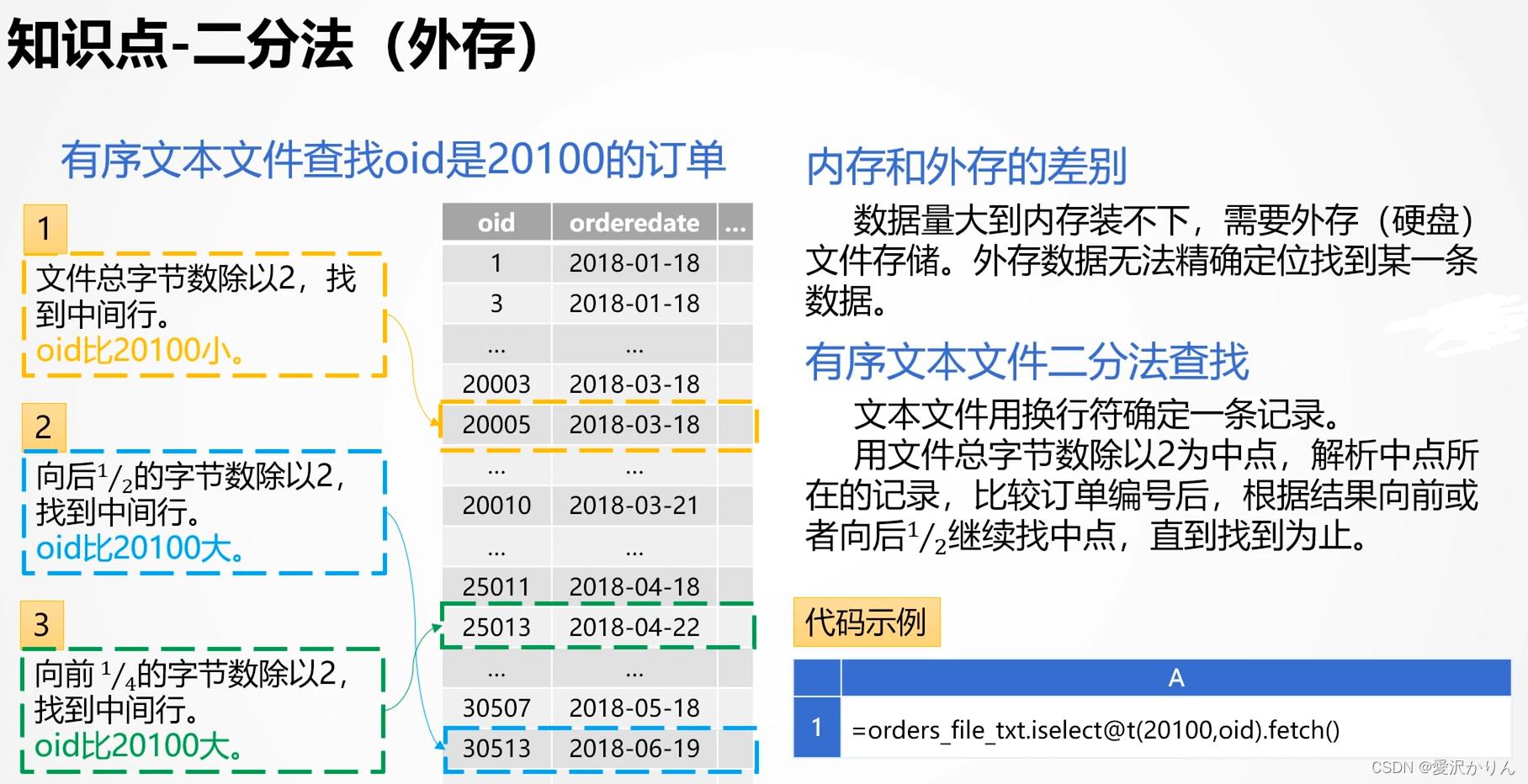
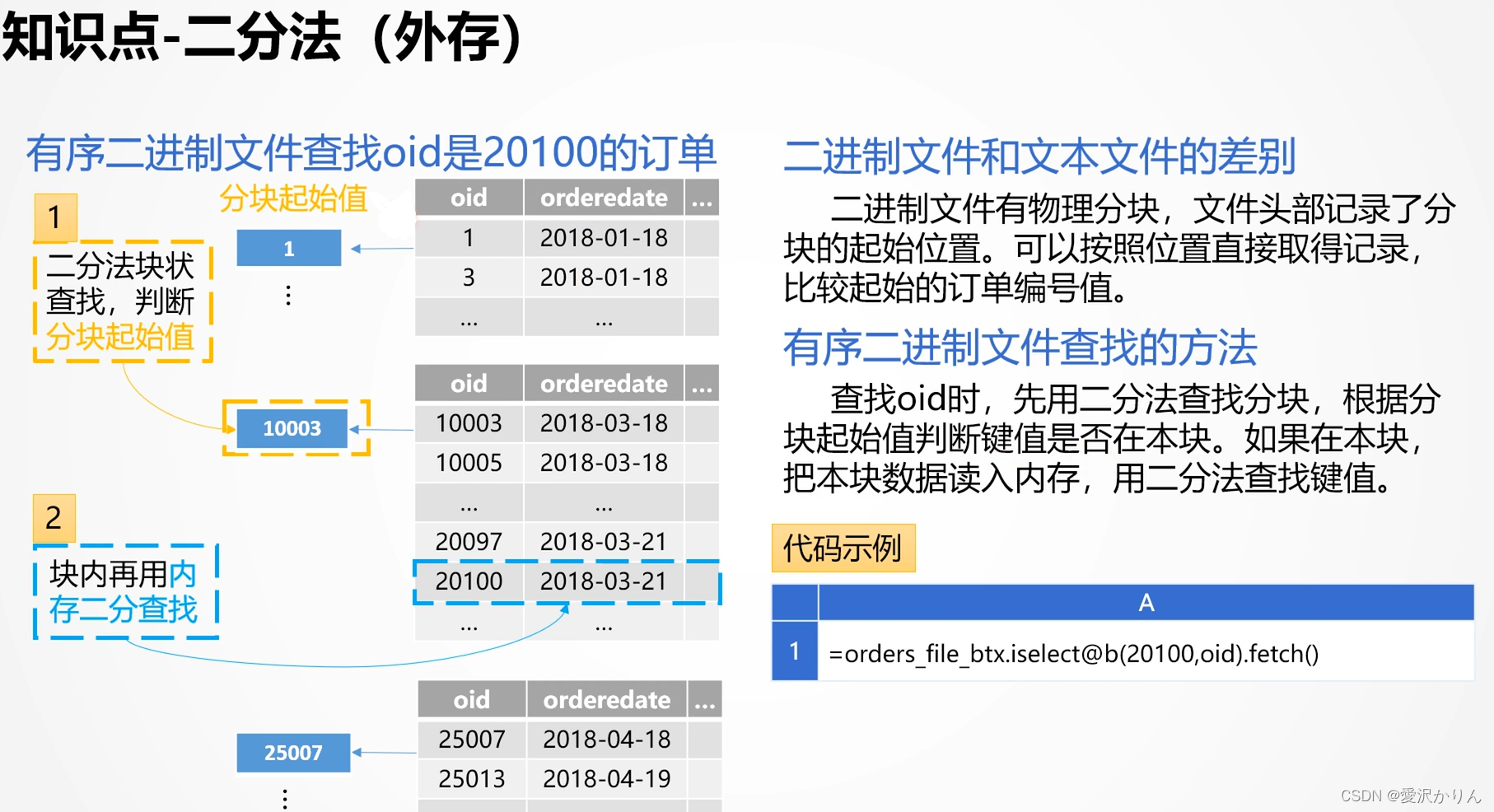
1.打开p1.9.dfx,用遍历法查找oid==8123456,记录执行时间

2.利用二分法(外存)改写p1.9.dfx,比较性能

二.外存-排序索引
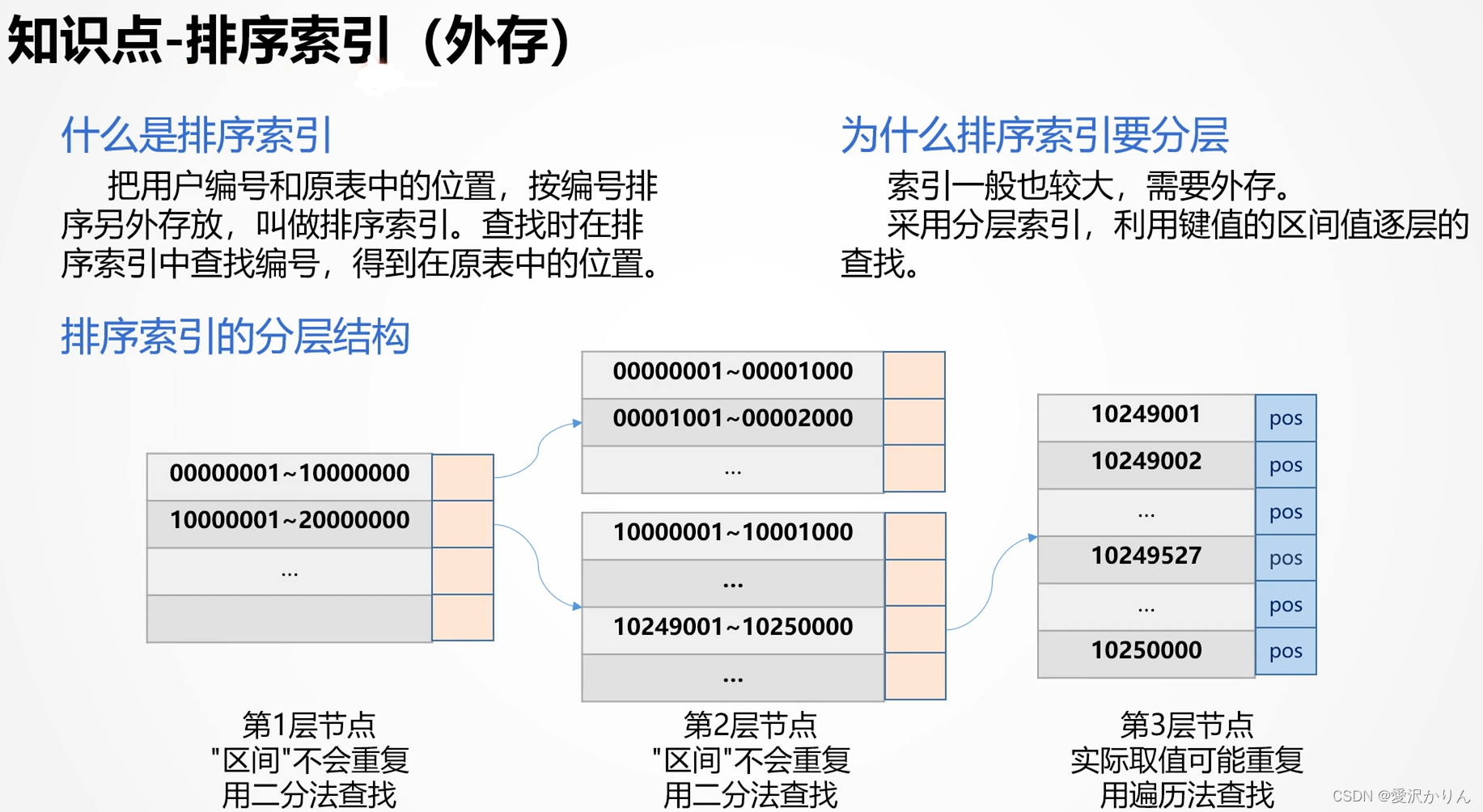
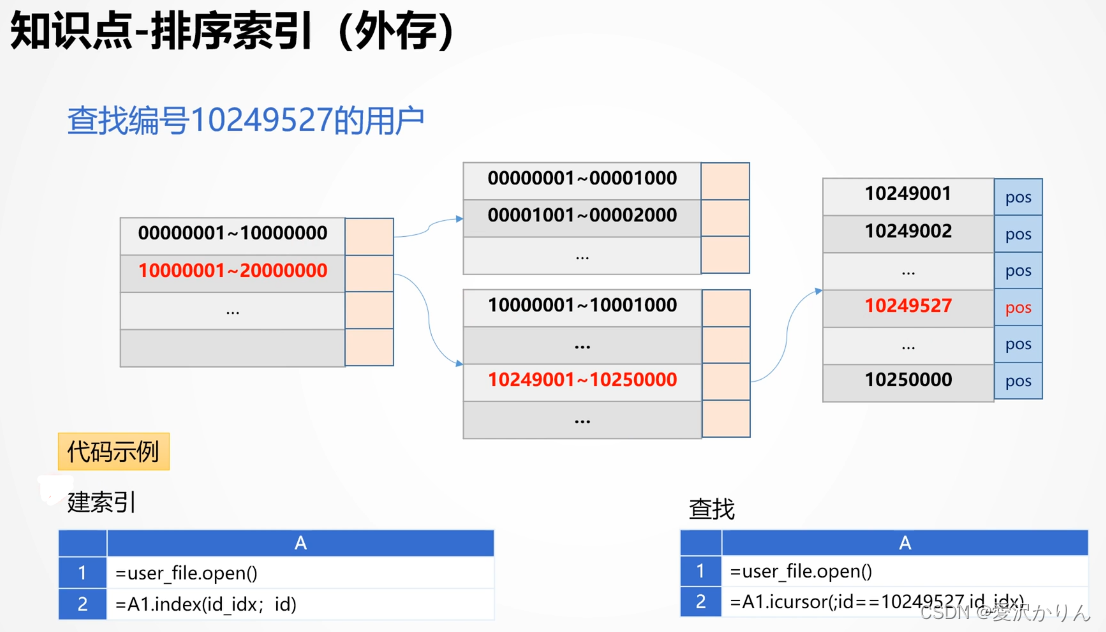
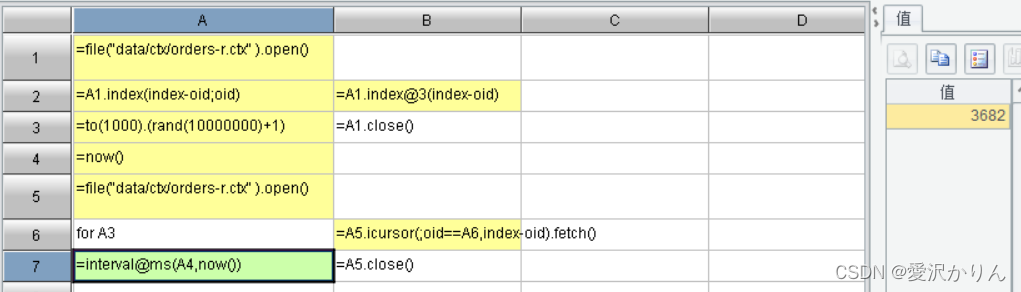
1.打开p1.10.dfx,无索引查找1000个随机的订单编号,记录执行时间

2.改写p1.10.dfx,使用排序索引查找,比较性能,查看产生的索引文件
在seek\data\ctx目录中发现订单索引文件

三.外存-哈希索引

1.打开p1.11.dfx,用遍历法查找1000个随机的订单编号,记录执行时间
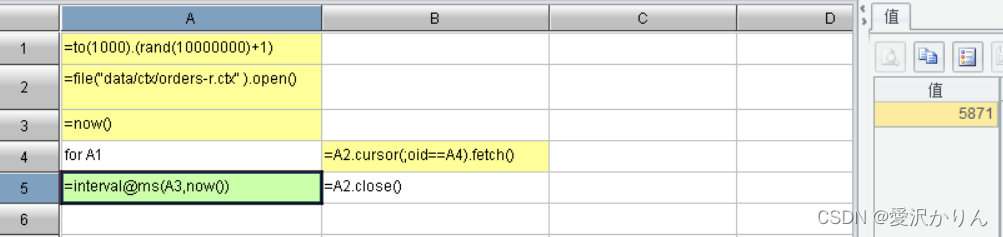
2.改写p1.11.dfx,使用哈希索引查找,比较性能
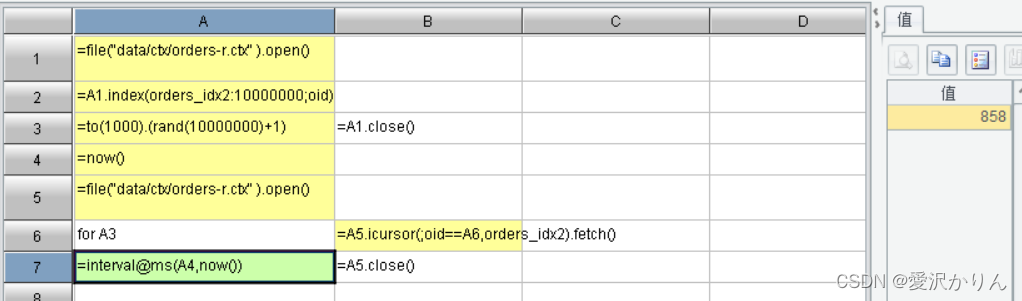

保证生成的索引文件名称不能重复,平均索引长度为1最合适,冲突最小
这篇关于SPL性能提升-单键值查找的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






