本文主要是介绍Infobright高性能数据仓库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 概述
Infobright是一款基于独特的专利知识网格技术的列式数据库。Infobright简单易用,快速安装部署,使用中无需复杂操作,能大幅度减少管理工作;在应对50TB甚至更多数据量进行多并发复杂查询时,更能够显示出令人惊叹的速度。相比于MySQL,其查询速度提升了数倍甚至数十倍,在同类产品中单机性能处于领先地位。为企业剧增的数据规模、增长的客户需求以及较高的用户期望提供了全面的解决方案。
2. Infobright特征
优点:
1)大数据量查询性能强劲、稳定:查询性能高,如百万、千万、亿级记录数条件下,同等的SELECT查询语句,速度比MyISAM、InnoDB等普通的MySQL存储引擎快5~60倍。高效查询主要依赖特殊设计的存储结构对查询的优化,但这里优化的效果还取决于数据库结构和查询语句的设计。
2)存储数据量大:TB级数据大小,几十亿条记录。数据量存储主要依赖自己提供的高速数据加载工具(百G/小时)和高数据压缩比(>10:1)
3)高数据压缩比:号称平均能够达到 10:1 以上的数据压缩率。甚至可以达到40:1,极大地节省了数据存储空间。高数据压缩比主要依赖列式存储和 patent-pending 的灵活压缩算法。
4)基于列存储:无需建索引,无需分区。即使数据量十分巨大,查询速度也很快。用于数据仓库,处理海量数据没一套可不行。不需要建索引,就避免了维护索引及索引随着数据膨胀的问题。把每列数据分块压缩存放,每块有知识网格节点记录块内的统计信息,代替索引,加速搜 索。
5)快速响应复杂的聚合类查询:适合复杂的分析性SQL查询,如SUM, COUNT, AVG, GROUP BY
限制:
1)不支持数据更新:社区版Infobright只能使用“LOAD DATA INFILE”的方式导入数据,不支持INSERT、UPDATE、DELETE。
这使对数据的修改变得很困难,这样就限制了它作为实时数据服务的数据仓库来使用。用户要么忍受数据的非实时或非精确,这样对最(较)新数据的分析准确性就降低了许多;要么将它作为历史库来使用,带来的问题是实时库用什么?很多用户选择数据仓库系统,不是因为存储空间不够,而是数据加载性能和查询性能无法满足要求。
2)不支持高并发:只能支持10多个并发查询
虽然单库 10 多个并发对一般的应用来说也足够了,但较低的机器利用率对投资者来说总是一件不爽的事情,特别是在并发小请求较多的情况下。
3). 没有提供主从备份和横向扩展的功能。
如果没有主从备份,想做备份的话,也可以主从同时加载数据,但只能校验最终的数据一致性,这会使得从机在数据加载时停服务的时间较长;横向扩展方面,倒不是 Infobright 的错,它本身就不是分布式的存储系统,但如果把它搞成一个分布式的系统,应该是一件比较好玩的事情。
不支持数据更新。 这个限制对于我们即要求查询性能外还要对数据库进行写入的需求, 造成了很大的不变。 这个估计是很多人试用后放弃试用ICE的第一个原因。
4). 不支持对多核的使用。 不但不支持查询的多并发,而且连导入导出也没有这样的支持。这个也是放弃ICE的一个原因。 谁也不愿意自己的强劲的硬件只能被用到1%。
与MySQL对比:
1、infobright适用于数据仓库场合:即非事务、非实时、非多并发;分析为主;存放既定的事实(基本不会再变),例如日志,或汇总的大量的 数据。所以它并不适合于应对来自网站用户的请求。实际上它取一条记录比mysql要慢很多,但它取100W条记录会比mysql快。
2、mysql的总数据文件占用空间通常会比实际数据多,因为它还有索引。infobright的压缩能力很强大,按列按不同类型的数据来压缩。
3、服务形式与接口跟mysql一致,可以用类似mysql的方式启用infobright服务,然后原来连接mysql的应用程序都可以以类似的 方式连接与查询infobright。这对熟练mysql者来说是个福音,学习成本基本为0。
infobright有两个发布版:开源的ICE及闭源商用的IEE。ICE提供了足够用的功能,但不能 INSERT,DELETE,UPDATE,只能LOAD DATA INFILE。IEE除提供更充分的功能外,据说查询速度也要更快。
3. 架构
基于MySQL的内部架构 – Infobright采取与MySQL相似的内部架构
下面是Infobright的架构图:
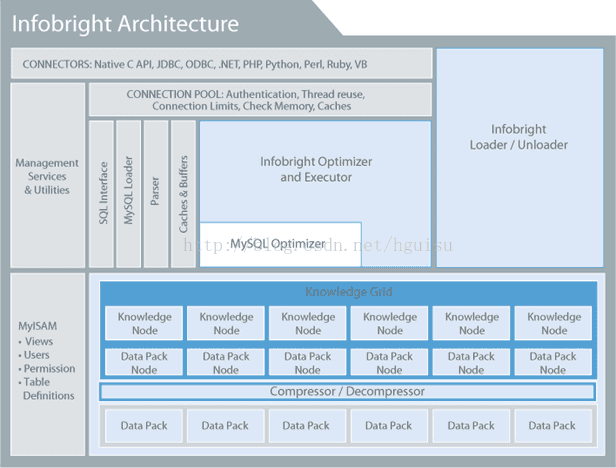
2)Knowledge Node里面存储着指向DP之间或者列之间关系的一些元数据集合,比如值发生的范围(MIin_Max)、列数据之间的关联。大部分的KN数据是装载数据的时候产生的,另外一些事是查询的时候产生。
Knowledge Grid构架是Infobright高性能的重要原因。
Knowledge Grid可分为四部分,DPN、Histogram、CMAP、P-2-P。
DPN如上所述。Histogram用来提高数字类型(比如date,time,decimal)的查询的性能。Histogram是装载数据的时候就产生的。DPN中有mix、max,Histogram中把Min-Max分成1024段,如果Mix_Max范围小于1024的话,每一段就是就是一个单独的值。这个时候KN就是一个数值是否在当前段的二进制表示。

Histogram的作用就是快速判断当前DP是否满足查询条件。如上图所示,比如select id from customerInfo where id>50 and id<70。那么很容易就可以得到当前DP不满足条件。所以Histogram对于那种数字限定的查询能够很有效地减少查询DP的数量。
CMAP是针对于文本类型的查询,也是装载数据的时候就产生的。CMAP是统计当前DP内,ASCII在1-64位置出现的情况。如下图所示
这篇关于Infobright高性能数据仓库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







