本文主要是介绍在win10上cuda12+tensorrt8.6+vs2019环境下编译paddle2.6生成python包与c++推理库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
paddle infer官方目前没有发布基于cuda12的c++库,为此参考https://www.paddlepaddle.org.cn/inference/user_guides/source_compile.html实现cuda12的编译安装,不料博主才边缘好自己的paddle2.6,paddle官方已经发布了cuda12.0的paddle2.6框架。但按照官网教程进行编译是有很多bug需要解决的,故此分享一下经验,避免踩坑。例如在使用paddle infer库时发现某些类的接口设置不合理,可以通过修改源码后自行编译,修改接口权限。
1、编译前准备
1.1 下载源码
下载源码
git clone https://github.com/PaddlePaddle/Paddle.git
cd Paddle
git checkout release/2.6
1.2 安装依赖项
pip install numpy protobuf wheel ninja
1.3 执行cmake命令
执行以下编译命令 ,Visual Studio 16 2019这个根据自己电脑环境进行修改,TENSORRT_ROOT按照自己配置设置,也可以删除该配置项
cmake .. -G "Visual Studio 16 2019" -A x64 -DWITH_GPU=ON -DWITH_TESTING=OFF -DON_INFER=ON -DCMAKE_BUILD_TYPE=Release -DPY_VERSION=3.8
如果本机安装了多个 CUDA,将使用最新安装的 CUDA 版本。若需要指定 CUDA 版本,则需要设置环境变量。先执行以下代码
set CUDA_TOOLKIT_ROOT_DIR=C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.2 set PATH=%CUDA_TOOLKIT_ROOT_DIR:/=\%\bin;%CUDA_TOOLKIT_ROOT_DIR:/=\%\libnvvp;%PATH%
如果本机安装了多个 Python,将自动使用最新安装的 Python 版本。若需要指定 Python 版本,则需要指定 Python 路径。则需要在cmake命令中添加以下命令
-DPYTHON_EXECUTABLE=C:\Python38\python.exe -DPYTHON_INCLUDE_DIR=C:\Python38\include -DPYTHON_LIBRARY=C:\Python38\libs\python38.lib -DWITH_UNITY_BUILD=ON
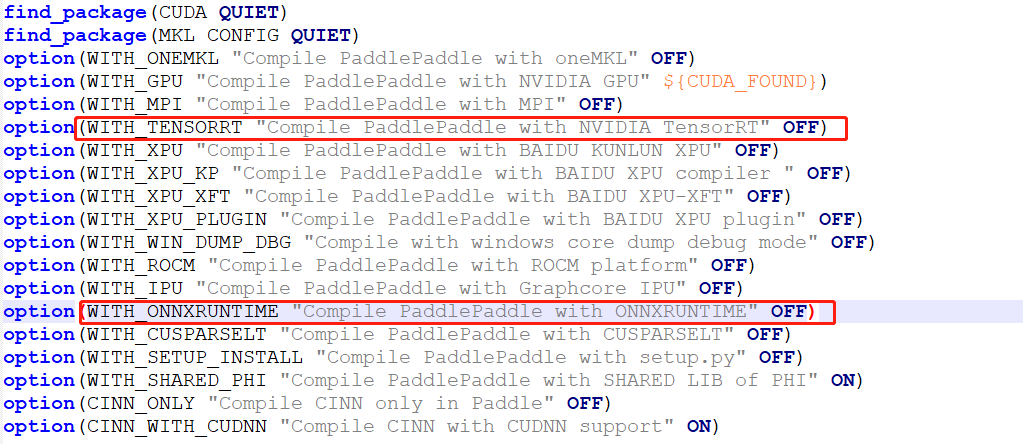
除了以上的cuda支持外,编译paddle还有一下支持项,tensorrt、onnxruntime等,具体见下图
2、编译中问题
2.1 python版本报错
若无以下报错,则忽略该章节
Paddle only support Python version>=3.8 now
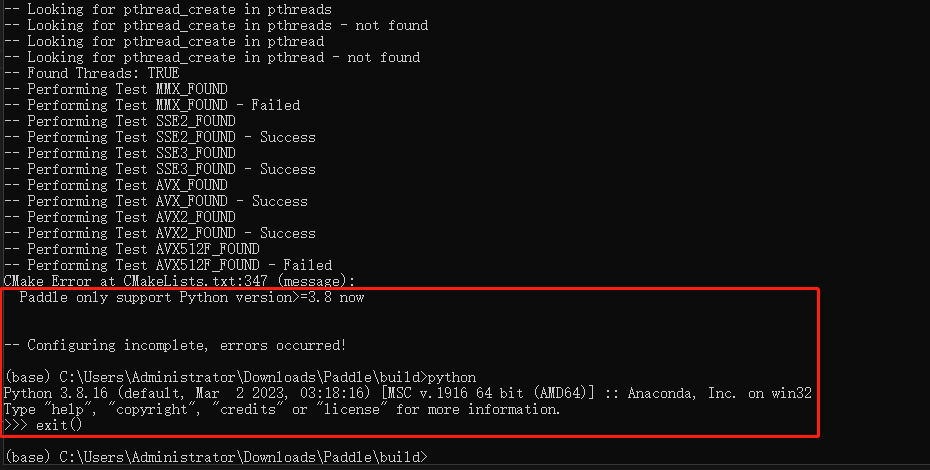
如果确认自己python版本没有任何问题,参考博主的操作,将原来判断版本的代码改成以下形式
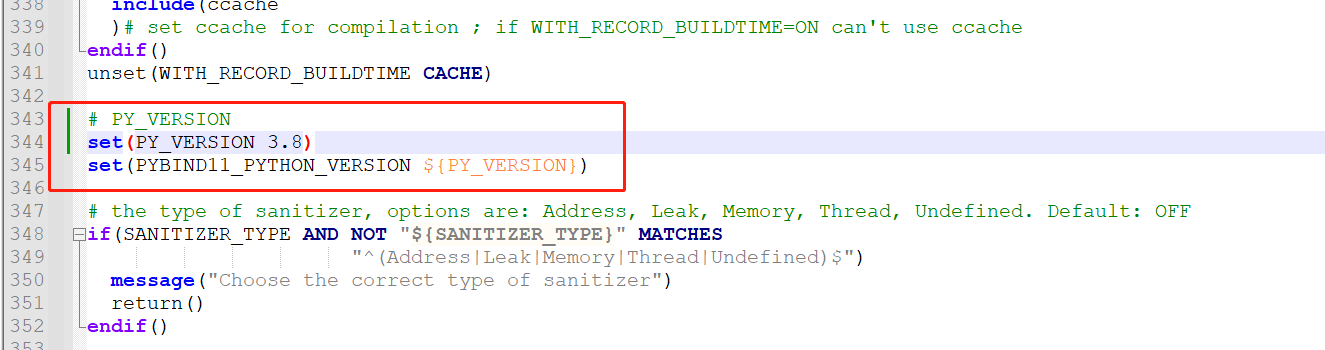
此时,应该会cmake成功,输出信息如下所示
2.2 vs2019编译
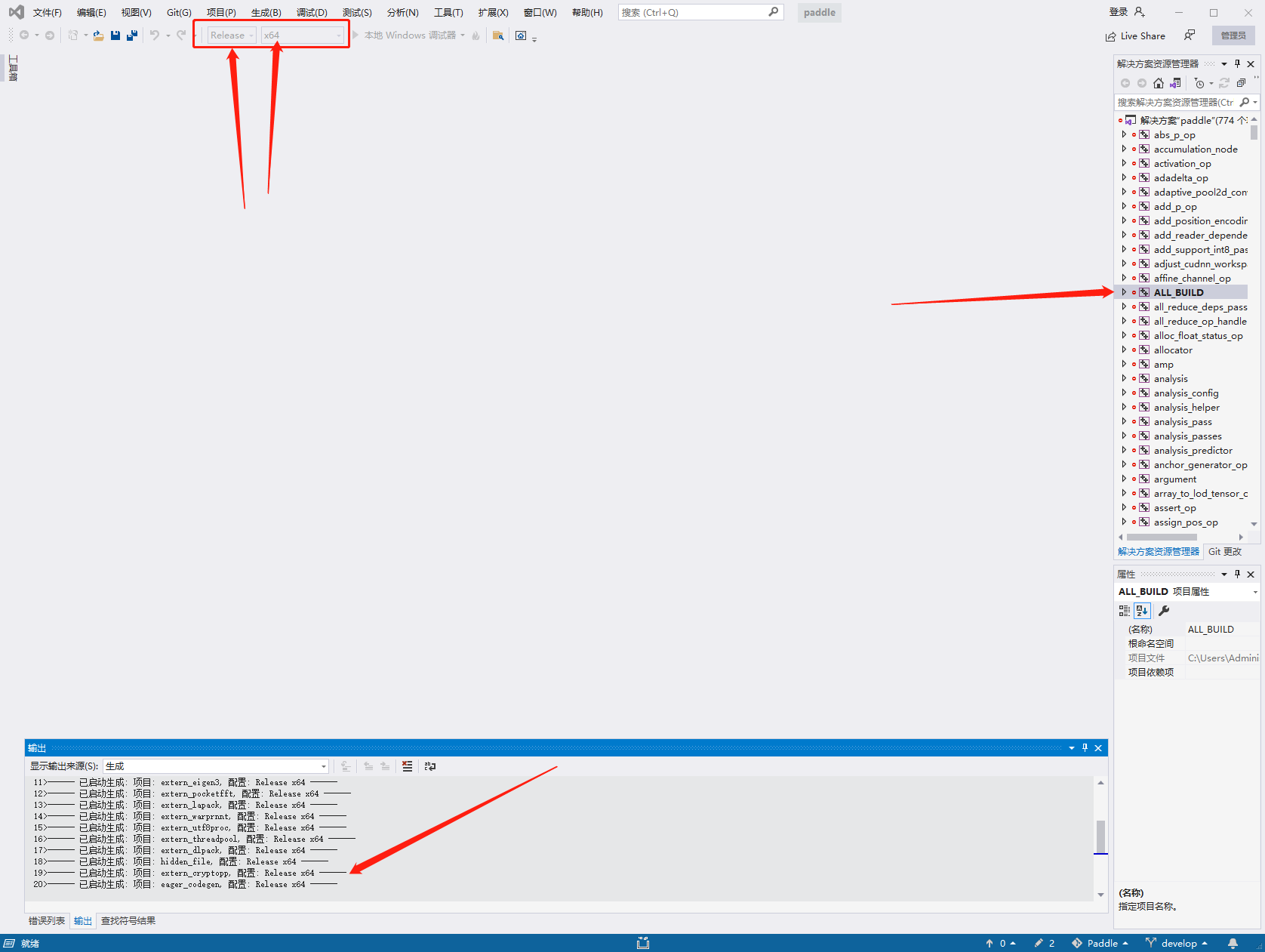
找到以下文件,双击打开

在vs中将配置项改成以下内容,并在ALL_BUILD处点击右键选生成,此时界面信息如下图所示
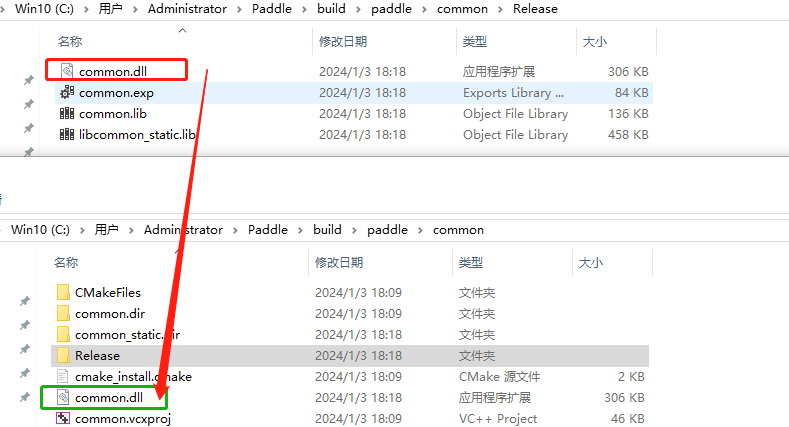
2.3 过程报错一

解决方案,将生成的common.dll拷贝出来,重新执行一遍编译
2.4 过程报错二
以下报错是同样是拷贝文件失误,但不清楚具体是怎么导致的

博主将Paddle/cmake/copyfile.py里的代码改为以下方式:
import glob
import os
import shutil
import sysdef main():src = sys.argv[1]dst = sys.argv[2]try:if os.path.isdir(src): # copy directorypathList = os.path.split(src)dst = os.path.join(dst, pathList[-1])if not os.path.exists(dst):shutil.copytree(src, dst)print(f"first copy directory: {src} --->>> {dst}")else:shutil.rmtree(dst)shutil.copytree(src, dst)print(f"overwritten copy directory: {src} --->>> {dst}")else: # copy file, wildcardif not os.path.exists(dst):os.makedirs(dst)srcFiles = glob.glob(src)for srcFile in srcFiles:print(f"copy file: {srcFile} --->>> {dst}")shutil.copy(srcFile, dst)except:print("拷贝失误:=====》",src,dst)raise EOFErrorif __name__ == "__main__":main()
察觉出是 拷贝失误:=====》 C:\Users\Administrator\Paddle\build\paddle\common\common.* C:\Users\Administrator\Paddle\build\paddle_inference_install_dir\paddle\lib
于是手动完成数据拷贝
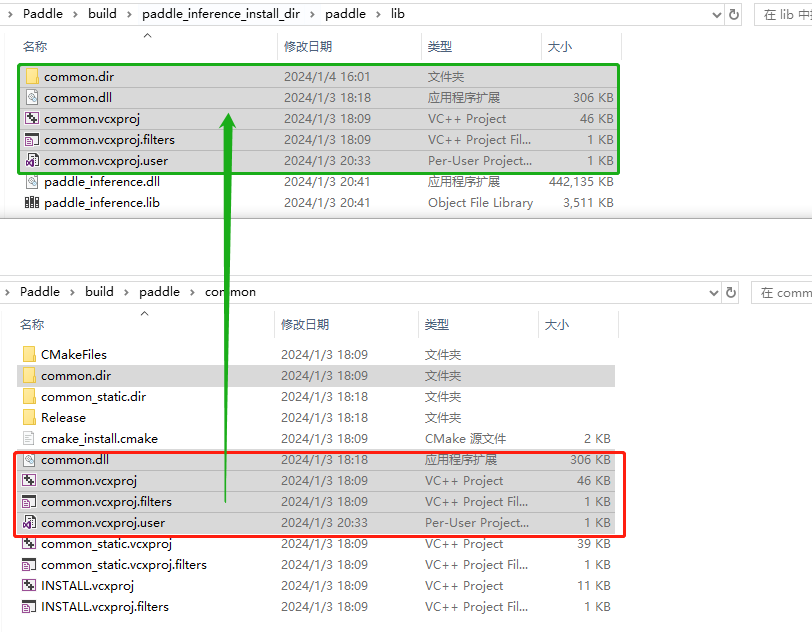
并将Paddle/cmake/copyfile.py里的代码改为以下方式,跳过对common.*数据的拷贝。然后重新执行编译
import glob
import os
import shutil
import sysdef main():src = sys.argv[1]dst = sys.argv[2]try:if os.path.isdir(src): # copy directorypathList = os.path.split(src)dst = os.path.join(dst, pathList[-1])if not os.path.exists(dst):shutil.copytree(src, dst)print(f"first copy directory: {src} --->>> {dst}")else:#shutil.rmtree(dst)#shutil.copytree(src, dst)print(f"overwritten copy directory: {src} --->>> {dst}")else: # copy file, wildcardif not os.path.exists(dst):os.makedirs(dst)if "common.*" in src:returnsrcFiles = glob.glob(src)for srcFile in srcFiles:shutil.copy(srcFile, dst)print(f"copy file: {srcFile} --->>> {dst}")except:print("拷贝失误:=====》",src,dst)raise EOFErrorif __name__ == "__main__":main()
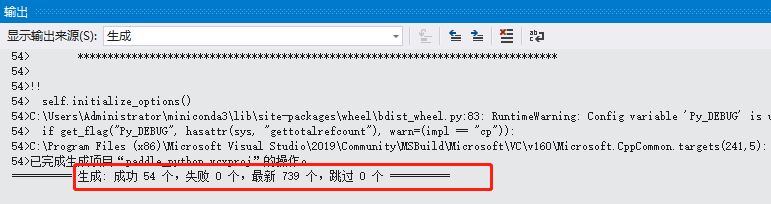
最终输出如下所示,可见编译成功
3、编译结果
3.1 python安装包
可以在python终端进入dist目录,然后执行pip install ./paddlepaddle_gpu-0.0.0-cp38-cp38-win_amd64.whl 安装自己编译的paddle

3.2 c++推理库
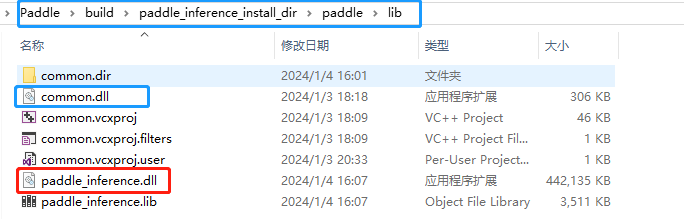
paddle/Include目录下包括了使用飞桨预测库需要的头文件,paddle/lib目录下包括了生成的静态库和动态库,third_party目录下包括了预测库依赖的其它库文件。
具体形式如官网一致
build/paddle_inference_install_dir
├── CMakeCache.txt
├── paddle
│ ├── include
│ │ ├── paddle_anakin_config.h
│ │ ├── paddle_analysis_config.h
│ │ ├── paddle_api.h
│ │ ├── paddle_inference_api.h
│ │ ├── paddle_mkldnn_quantizer_config.h
│ │ └── paddle_pass_builder.h
│ └── lib
│ ├── libpaddle_inference.a (Linux)
│ ├── libpaddle_inference.so (Linux)
│ └── libpaddle_inference.lib (Windows)
├── third_party
│ ├── boost
│ │ └── boost
│ ├── eigen3
│ │ ├── Eigen
│ │ └── unsupported
│ └── install
│ ├── gflags
│ ├── glog
│ ├── mkldnn
│ ├── mklml
│ ├── protobuf
│ ├── xxhash
│ └── zlib
└── version.txt
在使用过程中需要将dll文件的路径添加到系统环境变量中
这篇关于在win10上cuda12+tensorrt8.6+vs2019环境下编译paddle2.6生成python包与c++推理库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





