本文主要是介绍达梦数据:数字化时代,国产数据库第一股终于到来?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
又是新的一年开始。回首一年前的此时,在大家千呼万唤地期待中,数据基础制度体系的纲领性文件正式发布。
时隔一年之后,数据资源入表如约而至。2024年1月1日《企业数据资源相关会计处理暂行规定》正式施行,各行各业海量数据巨大的商业价值开始被量化兑现,数据产业正式开启巨大变革。
恰逢此时,作为数据资产实现的必要底层支柱,国产基础数据库即将迎来上市第一股。资料显示,2022年12月20日国产数据库四朵金花之一达梦数据通过审议,计划科创板上市;近日其上市进度更新,2023年12月7日,达梦数据更新2023年半年度财务数据;12月20日,上交所同意其首次公开发行股票申请。
那么数据资产化浪潮之下,万众瞩目的国产数据库第一股到底如何?

40年的孤独坚守,终将绽放
2000年达梦数据成立于中部地区唯一的“中国软件名城”——武汉。事实上,达梦数据的故事再往前追溯二十年。
1978年,在华中工学院做讲师的冯裕才见证了日本销毁武钢热轧车间斥巨资引入的无人职守轧钢系统技术资料。令国人刺痛的技术封锁下,冯裕才暗下决心:中国人一定要做出自己的核心技术。
对于大部分的企业而言,创始人毫无疑问是其中的灵魂,正如冯裕才之于达梦数据。正是在冯裕才坚持“做中国人自己的数据管理系统”初衷下,达梦数据得以成立,也是其这些年来最终坚持下来的核心动力。
1988年,历经没基础知识、没技术、没资金、没人才,以及海外诱惑的冯裕才团队成功研发出我国第一个自主版权的数据库管理系统原型CRDS。次年,国内最早一批从事专业数据库研究的“华中理工大学达梦数据库与多媒体技术研究所”,继续深耕研发的同时,冯裕才以该研究所所长的身份下海经,将产品推向市场。
近二十年的研发积累下,2000年,冯裕才以及其研究所团队骨干最终成立了武汉华工达梦数据库有限公司,其中“‘达梦’就是达到梦想的意思。因为我立志研发数据库,就是起源于一个自主研发的梦想。”冯裕才解释。
截至2023年,达梦数据已然成为国内领先的数据库产品开发服务商,是国内数据库基础软件产业发展的关键推动者。公开资料显示,自成立以来,达梦数据先后完成并获得数十项国家级或省部级科研开发项目与奖项,多次牵头承担了“十一五”、“十三五”期间的国家科技重大专项。
四十几载的坚守,达梦数据成功屹立于完全自主的国产数据库之首。
首先技术上,相较于其他研发团队,达梦数据拒绝踩在巨人的肩膀上行坦途,始终坚持走原始创新源代码技术路线,这是达梦数据多年来最核心的坚持,也是最终得以脱颖而出的底层关键。
据招股说明书显示,达梦已掌握数据管理与数据分析领域的核心前沿技术,其拥有全部源代码,自主原创率达99.9%。其自主研发的共享存储集群技术更是实现了国产高端领域的“零”突破,增强了我国数据库厂商“断供”风险的抵抗能力。
正是得益于其完全自主的技术底气,达梦数据成功抓住2020年开启的信创风口,在传统电力、通信、政企等多个领域大幅取代境外数据库,实现营收、盈利规模快速扩张,多次被网友称之为“中国甲骨文”。
招股说明显示,达梦数据2019年至2022年营收年度复合增长率达到31.58%,净利润年度复合增长率47.26%,尤其是2021年党政信创高峰期下,其净利润高达4.4亿元,同比2020年增长203.75%.
其次,多年市场积累下,达梦数据两年蝉联第一。资料显示,2020年至2022年,在中国国产数据库管理软件市场中,达梦数据领先,达梦数据领先于人大金仓、优炫软件、通用数据、神舟通用等其他传统数据库厂商,排名第一。
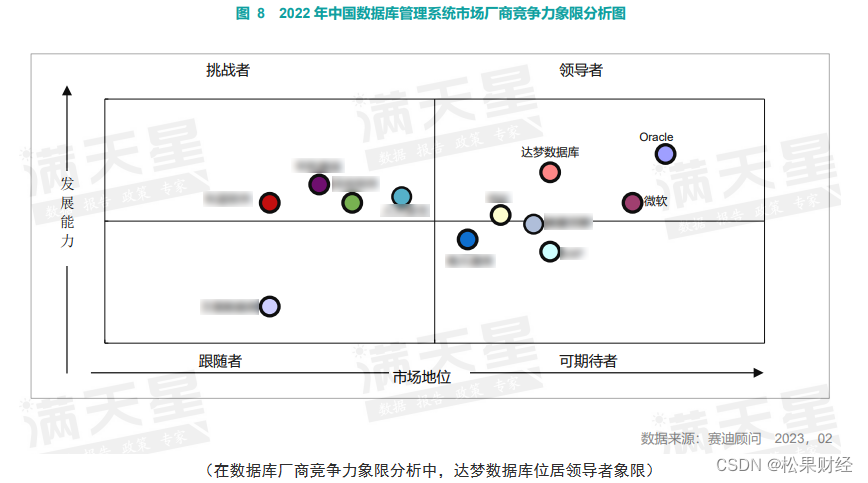
正是基于达梦数据在核心技术以及同行中首支上市上的稀缺性,预计其上市后估值将达到300-500亿。机构预测,参考其他基础软件赛道首支上市的稀缺标的大致100倍的市盈率,简单用PE估值预测,按2021年达梦净利润4.86亿,其上市估值或达到500亿;若按2022年回落后的2.84亿元净利润估算,估值预计300亿。
然而,发展是永不停歇的。尤其是随着互联网科技的加速发展,全球数字化进程持续推进,即便已位列国产数据库之首,达梦数据也迎来新的挑战。
成于国产替代,囿于国产替代,破题成为达梦数据能否盛开的关键
事实上,类似于光伏、新能源汽车等新能源行业,国产数据库同样属于国家政策强力支持的重点产业。而复盘新能源的发展历程发现,对于政策大力支持的行业而言,政策驱动只是行业发展初期的推动力,随着行业跨越0-1的起步阶段,逐渐规模成型,最终仍将回归到市场。
目前国产数据库行业正处于政策导向向市场导向转变的过渡期,激烈的行业竞争才刚刚开始。
一方面,相比于过去比较单一的存量替代需求,人工智能与大数据等新技术的爆发进一步驱动数据库市场的快速发展,据信通院报告预测,到2025年,中国数据库市场总规模将达到688亿元,年复合增长率为23.4%。爆发式的新增市场需求下,国产数据库市场推广正逐步进入深水区,众多重大行业的核心生产系统对国产数据库提出了更为严格的要求,包括功能、性能和兼容性等方面,需要厂商苦练内功,提升产品品质。
另一方面,全球数字化浪潮催生了大量数据库厂商和产品,内卷严重,特别是不少产品“千人一面”。信通院报告显示,截至2022 年6月中国数据库厂商数量已经达到116家,仅次于美国位列全球第二,然而再深入发现,技术人员破千的仅有三家,达梦数据正是其中之一。其余超过60%的国产数据库厂商不足100。
因此在整个行业竞争进一步升级下,达梦数据具备一定技术以及规模化优势。
然而,过去凭借高国产化特色,得以成功抓住国产替代机会,并实现营收快速增长的达梦数据,似乎面临客户转型困难。
招股说明书显示,达梦数据超一半以上的营收都源于安全性要求更高的党政领域,而产品需求更多元化、企业主体更多的行业领域客户相对偏少,其产品市场推动力不足的弊端似乎显现。资料显示,2019至2021年,党政占达梦数据收入比重的48%、63%、59%。
正是客户所属领域的过渡集中,使得刚成为风口上“那只猪”的达梦数据在2022年开始的信创低谷期中,营收与净利率逐渐下滑,尤其是2023年党政信创落地不及预期,使其盈利波动再度加大。
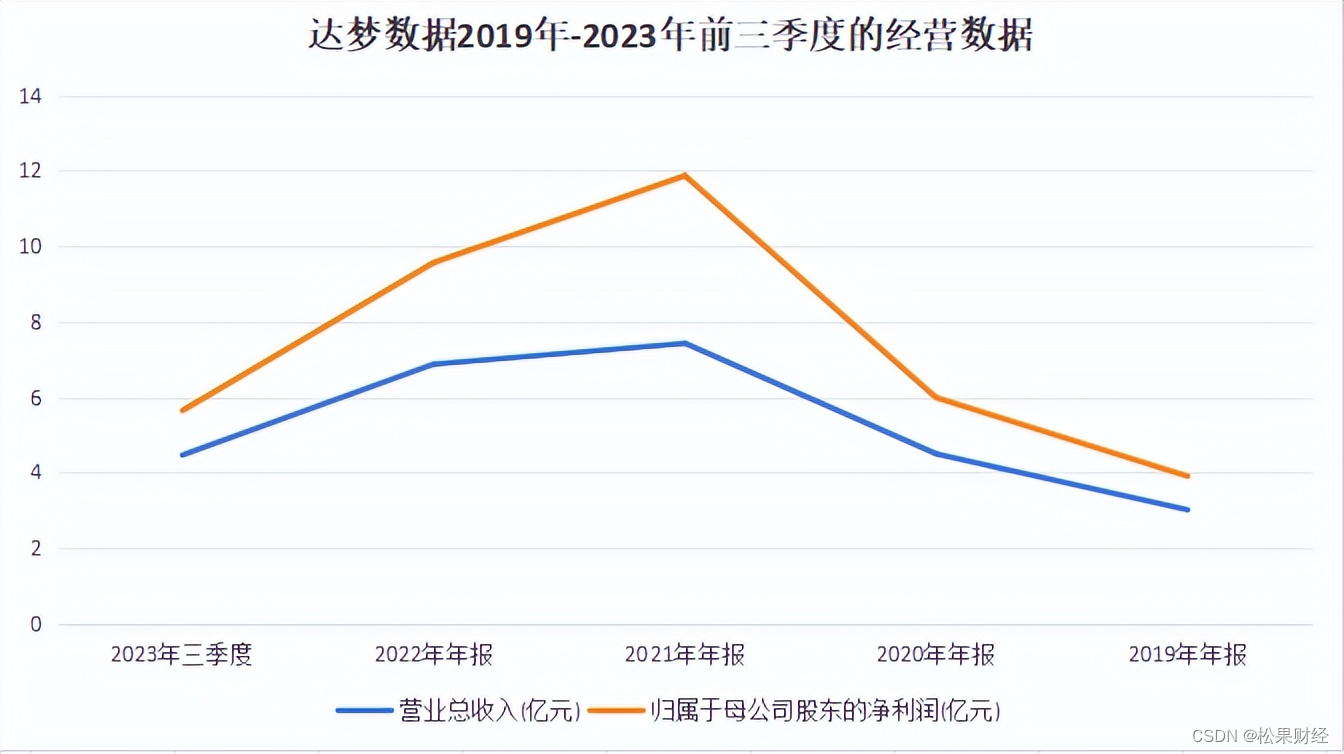
总之,过去风口之下,十多年来处于规模化前期的国产数据库企业迅速扩张,达梦数据领先优势明显。然而,随着数字化经济到来,数字化产品需求愈发多元,行业进入者与日俱增,达梦数据单一依靠国产化定位已不再适应行业发展态势,而先于市场多元化新需求、并迅速响应之,方能最大化发挥其在行业中的价值优势。
那么过去以国产化为己任的达梦数据,又该如何既依托国产替代,又超脱于纯粹的国产替代?
首先多线并进,改变过去单一依靠政务系统信创需求,向涉及系统更多、存量替换以及成长空间更大、产品形态更多元的行业端延伸,而构造更丰富发生态系统是助力达梦数据在云部署和分布式构架需求领域中加速渗透的公开秘诀。
一方面,参考阿里云、华为等后进入者们,正是凭借自身相对成熟的生态系统,整合其产业链上下游资源,得以快速渗入数据库市场中。以华为为例,目前华为依靠其完整的软硬件全产业链闭环,吸引众多企业加入其生态系统中,在此之下华为得以迅速领军本地部署以及云数据领域。资料显示,在本地部署模式市场中,华为云数据库GaussDB自2020H1以来,已经连续五次蝉联第一;在国内关系型数据库市场同样持续领跑。
另一方面,达梦数据拥有的稀缺技术给予其打造生态系统实力。达梦数据是全球第二个在软件层面全面突破共享存储集群核心技术的数据库厂商,也是目前国产厂商中率先实现共享存储集群产品商业化的企业。此外,达梦数据与全球绝对性数据库寡头甲骨文兼容达到近95%以上,超丝滑的平滑迁移,显著增强了应用端客户与之合作的意愿。
截至目前,公司产品已全面支持各类国产整机平台、操作系统、芯片、应用软件及其他上下游软硬件,完成与4000余个软硬件产品或信息系统的适配和兼容性互认工作。但相比把握云平台入口,控制数据库服务流量的互联网兼云计算巨头,达梦数据仍需在信息化大生态圈打造中多下功夫。
总之,达梦数据可以借助基础软件上的强大实力这个核心突破口,进一步加强与产业链上下游企业合作,打造自己的软硬件生态圈来增强产业协同发展,提升自身在产业链中的话语权的同时,将其产品更好的渗透众多领域与企业当中。
继续加大多形态产品研发。数据成为新的生产要素后,行业格局迎来重点变革,其中数据库部署方式逐渐呈现多元化,由单一关系型数据库向多元化数据库转变,其中云部署和分布式构架渗透率提升最快。
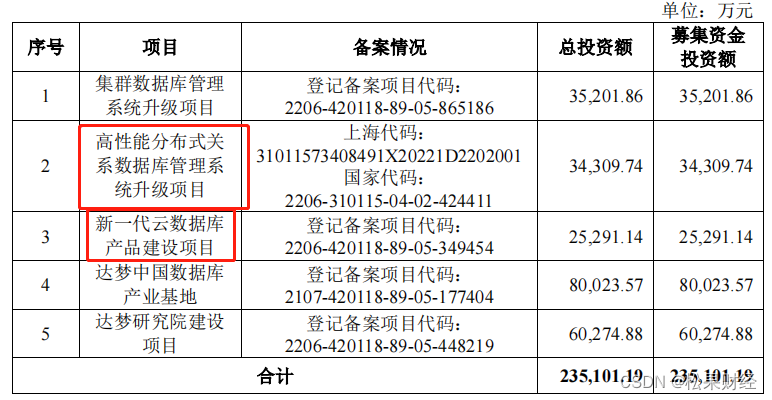
达梦数据过去主要深耕当前主流的集中式数据库,其他形态产品先发优势相对不明显。此前达梦数据已发布适用于金融科技、工业互联网、物联网场景的新一代分云数据数据库DMDPC,但是相比华为云、阿里云来说,市占率相差较大。因此后续需要继续借助其突破的共享存储集群核心技术来打造更丰富形态的产品类别,以更好响应市场多元化需求。达梦数据此次上市募资项目也体现了这一点。
总结
目前国内数据库产业正处于百花齐放阶段,而达梦数据凭借其100%源代码以及国产化资质铸就了较高核心壁垒,但在多元化市场需求中,如何凭借其核心技术快速覆盖更多应用领域以及企业,成为市场毫无争议的最佳答案,是达梦数据下一个值得深究的重点课题,也是达梦数据最终盛开,成为真正比肩群雄的国产数据库的关键。
作者:南鹞
来源:松果财经
这篇关于达梦数据:数字化时代,国产数据库第一股终于到来?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







