本文主要是介绍会这个4个方法,风控中的地址再也不愁了,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,我是小伍哥,发现用文档的形式,大家还是不方便阅读,还容易被别人盗版,所以这里重新发下。
风控中,经常会遇到各种各样的地址,并且地址是个非常重要的特征,今天我们就聊聊风控里面的地址怎么挖掘,这里做了个大汇总。示例数据关注【小伍哥聊风控】,后台回复【地址数据】获取
常见的地址有:用户通信地址、消费者收货地址、消费者家庭地址、用户上班地址、商家营业执照地址、商家发货地址、商家售后地址、IP解析地址、身份证解析地址、手机号归属地、户口本/身份证上的地址、定位地址等等。
有这么多的地址,我们怎么去提取特征或者直接使用地址特征呢?方法也是非常多的,我这里写4种,供大家参考。
为了给大家写文章更真实和实用,我去几个电商公司商家店铺里面扒了几个地址当成示例,感觉我现在闭着眼睛都能找到他们的风险用户了!!
下面是店铺示例

下面是数据示例
一、地址数据的正则处理
很多时候,想简单的验证下地址是否可靠,或者数据规模庞大,复杂算法比较消耗资源,那这种处理方式就非常的友好,且准确率也非常高。
1、英文数字正则
去年一直在思考怎么把地址用这个图里面的节点,各种方法成本都挺高的,后来发现,有个正则替换的方法非常有意思,简单粗暴,并且效果极好。
处理的后的效果如下,原本有微小差异的相似地址,处理后就变成一样的了。

我们开始代码处理部分
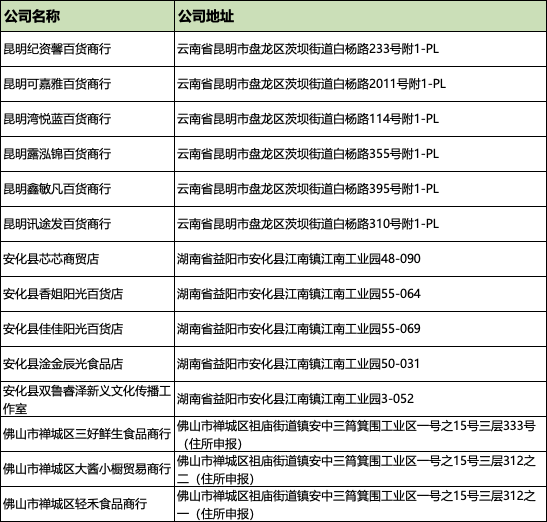
'''Create Oct 15 09:37:54 2023@公众号:小伍哥聊风控'''#加载所需要的包import pandas as pdimport numpy as npimport os#设置工作空间os.chdir('/Users/wuzhengxiang/Documents/DataSets/地址处理')data = pd.read_csv('公司地址数据.csv')data.head()公司名称 公司地址0 昆明纪资馨百货商行 云南省昆明市盘龙区茨坝街道白杨路233号附1-PL1 昆明可嘉雅百货商行 云南省昆明市盘龙区茨坝街道白杨路2011号附1-PL2 昆明湾悦蓝百货商行 云南省昆明市盘龙区茨坝街道白杨路114号附1-PL3 昆明露泓锦百货商行 云南省昆明市盘龙区茨坝街道白杨路355号附1-PL4 昆明鑫敏凡百货商行 云南省昆明市盘龙区茨坝街道白杨路395号附1-PL#构建正则函数'''构建正则处理函数我们要剔除数字字母以及- 很多地址中间带着-'''import redef replace_address(text):return re.sub('[A-Za-z0-9-]','',text)#简单构建个数据,测试下效果,可以看到 结果非常完美,符合预期text = '湖南省益阳市安化-县江南镇江南工业园48-090'replace_address(text)'湖南省益阳市安化县江南镇江南工业园'#下面对地址进行进行批量化的处理data['公司地址'] = data['公司地址'].apply(lambda x:replace_address(x))data.head()公司名称 公司地址0 昆明纪资馨百货商行 云南省昆明市盘龙区茨坝街道白杨路号附1 昆明可嘉雅百货商行 云南省昆明市盘龙区茨坝街道白杨路号附2 昆明湾悦蓝百货商行 云南省昆明市盘龙区茨坝街道白杨路号附3 昆明露泓锦百货商行 云南省昆明市盘龙区茨坝街道白杨路号附4 昆明鑫敏凡百货商行 云南省昆明市盘龙区茨坝街道白杨路号附
可以看下处理完整后的数据,如果你是在hive里面,直接SQL里面的正则替换函数,就可以处理,非常简单,有了处理后的数据,那就非常简单了。

2、高危地址画像
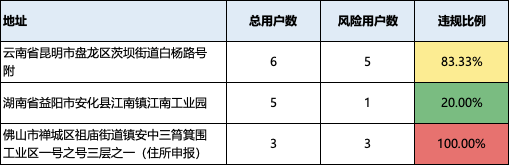
对于处理好的地址,计算就非常简单了,一个常用的方法,就是做地址画像,可以统计地址关联账号总数、风险账号数、违规比例等,得出高风险的地址,当成地址黑名单使用。
就可以直接当成特征去使用了,大概像下面👇🏻这个样子的,是不是非常简单。
3、地址公司社群划分
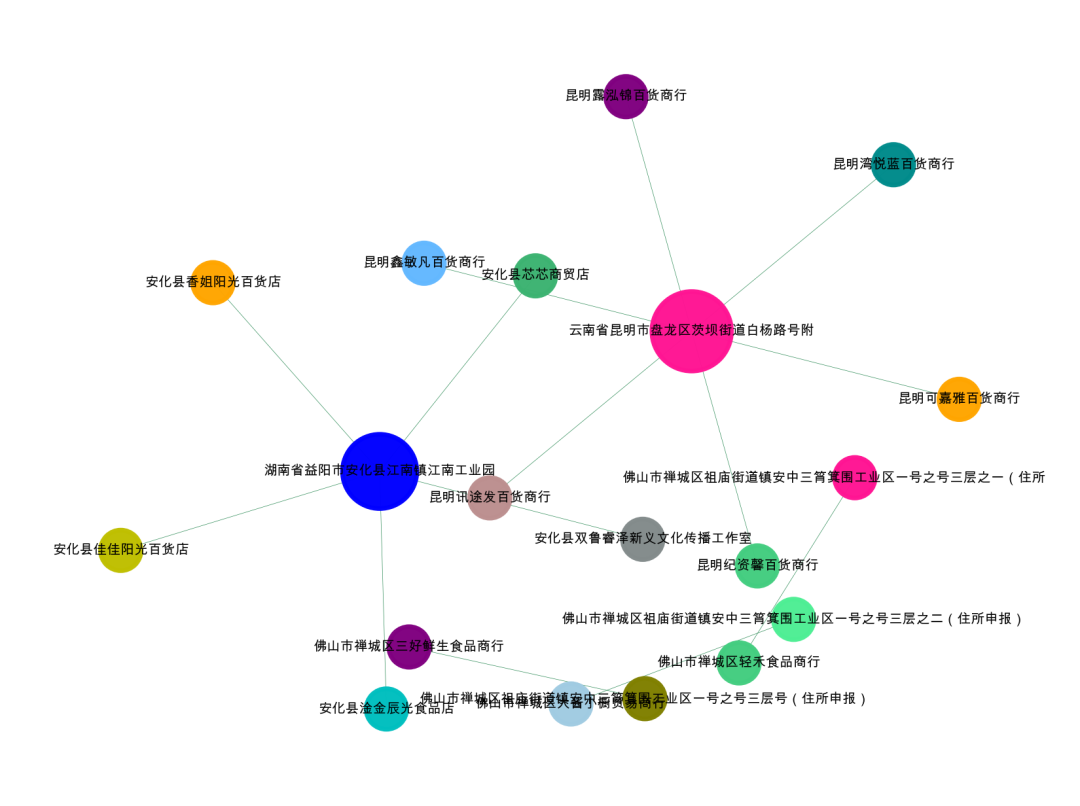
当然,我们也可以做图,公司名称-处理后的地址,构成了一个二部图。我们可以通过社群检测算法,然后进行社群划分,也就是得到了我们所谓的团伙了。
下面是代码部分
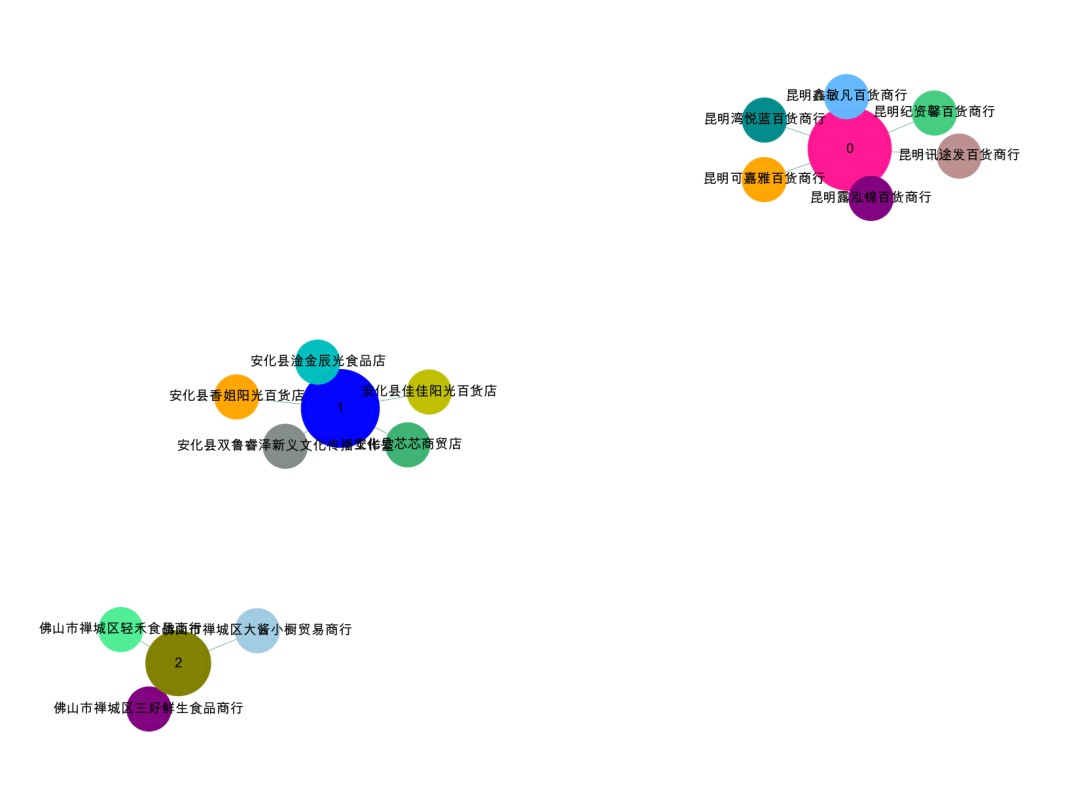
'''Create Oct 15 09:37:54 2023@公众号:小伍哥聊风控'''#先简单的,整体的可视化我们的数据集,如果样本比较多,这一步是无法完成的,需要社群划分后再进行可视化。import networkx as nximport matplotlib.pyplot as plt# 构建成图数据格式da = data[['公司名称','公司地址']].valuesG = nx.Graph()for num in range(len(da)):G.add_edge(str(da[num,0]),str(da[num,1]))#节点大小设置,与度关联node_size = [G.degree(i)**0.75*80 for i in G.nodes()]#设置颜色 随机来点colors = ['#43CD80','DeepPink','orange','#008B8B','purple','#63B8FF','#BC8F8F','#3CB371','b','orange','y','c','#838B8B','purple','olive','#A0CBE2','#4EEE94']*500colors = colors[0:len(G.nodes())]#设置显示图片大小plt.figure(figsize=(4,3),dpi=500)## 图像显示中文的问题plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = False#可以替换两种不同的布局看看效果,kamada_kawai_layout spring_layoutnx.draw_networkx(G,pos = nx.spring_layout(G),node_color = colors,edge_color = '#2E8B57',#with_labels=False,font_size =3,node_size = node_size,alpha = 0.98,width = 0.1)plt.axis('off')plt.show()
nx.spring_layout(G)
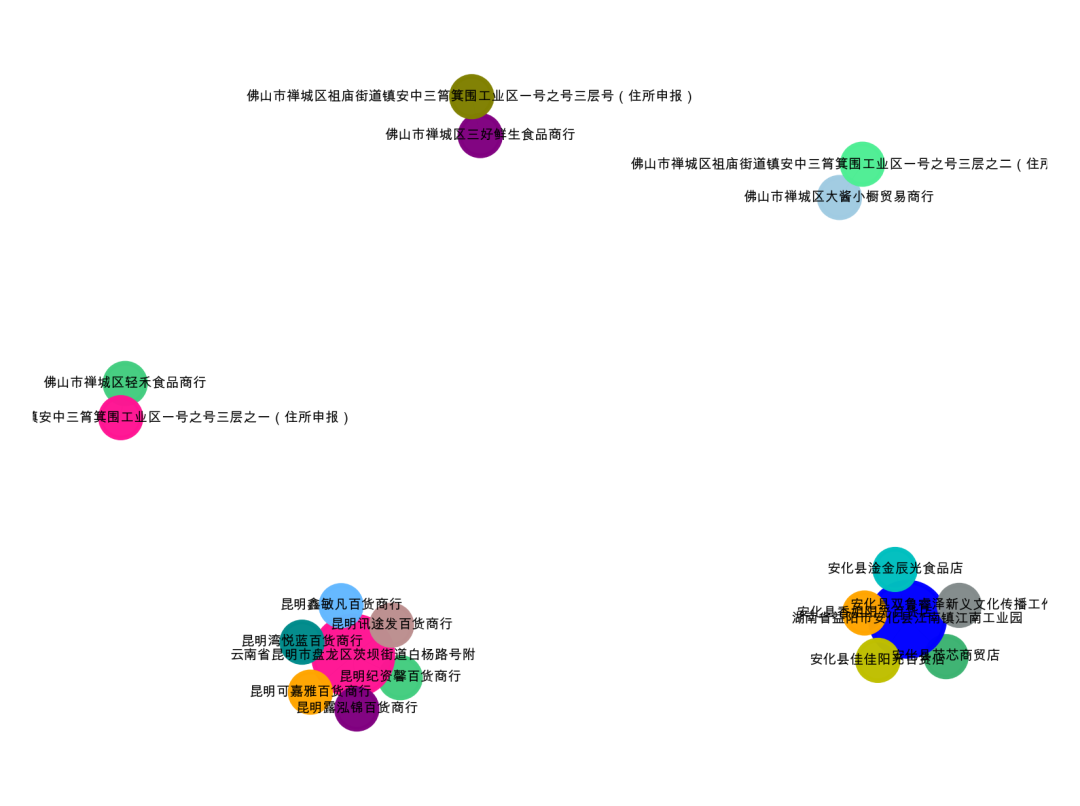
nx.kamada_kawai_layout(G)
可以看到,初看的时候只有3个团伙,分成了5个关系团伙,我们仔细看看数据。发现有三个地址其实是有微小的差异的。
佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之号三层号(住所申报)
佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之号三层之二(住所申报)
佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之号三层之一(住所申报)
所以这种粗暴的处理,只能解决非常直接的问题,稍微有点变动,就无法把握了。那遇到这种怎么搞办呢,看下一集的内容。
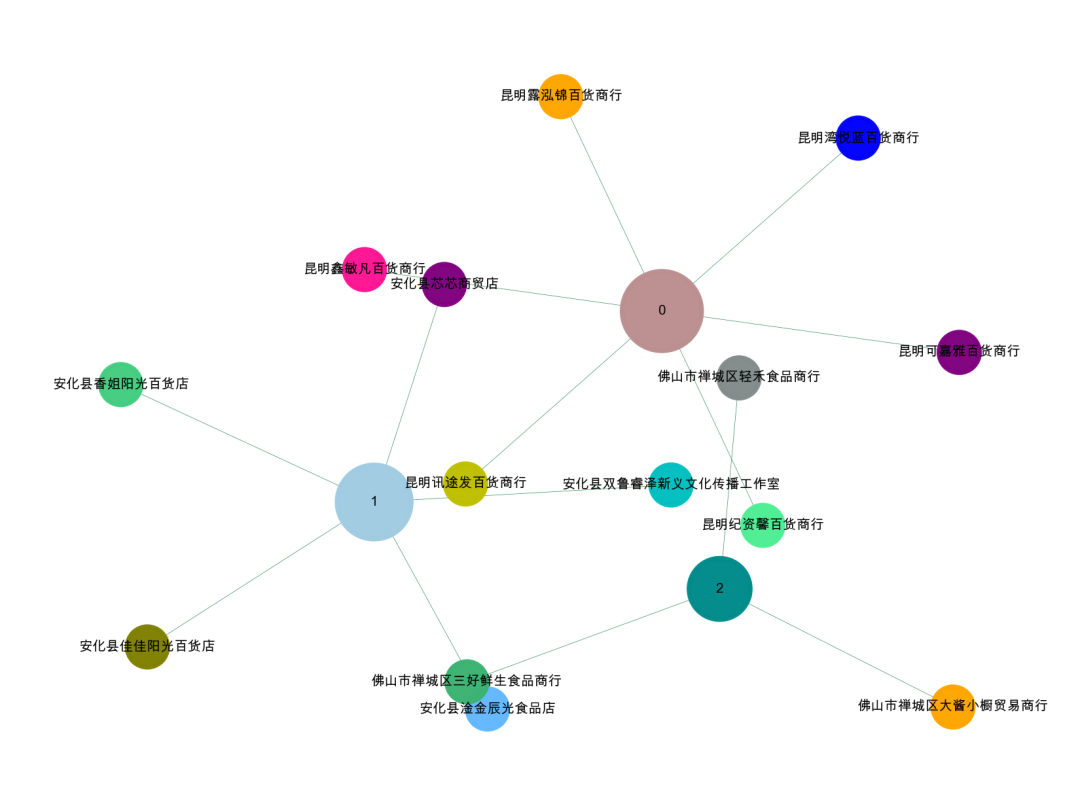
import networkx as nximport matplotlib.pyplot as plt# 找到所有连通子图da = data[['公司名称','公司地址']].valuesG = nx.Graph()for num in range(len(da)):G.add_edge(str(da[num,0]),str(da[num,1]))# 用极大连通子图算法com = list(nx.connected_components(G))# 打印看看什么格式的,可以看到得到的结果为列表-集合格式print(com)[{'昆明露泓锦百货商行', '昆明湾悦蓝百货商行', '昆明鑫敏凡百货商行', '昆明纪资馨百货商行', '云南省昆明市盘龙区茨坝街道白杨路号附', '昆明可嘉雅百货商行', '昆明讯途发百货商行'}, {'安化县香姐阳光百货店', '安化县淦金辰光食品店', '安化县双鲁睿泽新义文化传播工作室', '湖南省益阳市安化县江南镇江南工业园', '安化县佳佳阳光百货店', '安化县芯芯商贸店'}, {'佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之号三层号(住所申报)', '佛山市禅城区三好鲜生食品商行'}, {'佛山市禅城区大酱小橱贸易商行', '佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之号三层之二(住所申报)'}, {'佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之号三层之一(住所申报)', '佛山市禅城区轻禾食品商行'}]# 将 列表-字典 整理成数据表格形式df_com = pd.DataFrame()for i in range(0, len(com)):d = pd.DataFrame({'group_id': [i] * len(com[i]), 'object_id': list(com[i])})df_com = pd.concat([df_com,d])# 统计每个群组人数df_com.groupby('group_id').count().sort_values(by='object_id', ascending=False)object_idgroup_id0 71 62 23 24 2
可以看到,和上面数据一样,分成了5个社群,我们可以对每个社群单独进行可视化,分析地址和公司的连接关系。
4、单社群可视化
下面是单独进行可视化的代码
#提取某一个群组进行可视化,根据每个社群的节点,去找边。i= 0edges = []for k,v in zip(data['公司名称'].tolist(),data['公司地址'].tolist()):if k in com[i] or v in com[i]:edges.append((k,v))#转换成图结构,可以从元组列表直接构建图G = nx.Graph(edges)#节点大小设置,与度关联node_size = [G.degree(i)**1.5*200 for i in G.nodes()]#设置颜色 随机来点colors = ['#43CD80','DeepPink','orange','#008B8B','purple','#63B8FF','#BC8F8F','#3CB371','b','orange','y','c','#838B8B','purple','olive','#A0CBE2','#4EEE94']*500colors = colors[0:len(G.nodes())]#设置显示图片大小plt.figure(figsize=(4,4),dpi=400)## 图像显示中文的问题plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = False#可以替换两种不同的布局看看效果 kamada_kawai_layout spring_layoutnx.draw_networkx(G,pos = nx.kamada_kawai_layout(G),node_color = colors,edge_color = '#2E8B57',#with_labels=False,font_size = 8,node_size = node_size,alpha = 0.98,width = 0.1)plt.axis('off')plt.show()
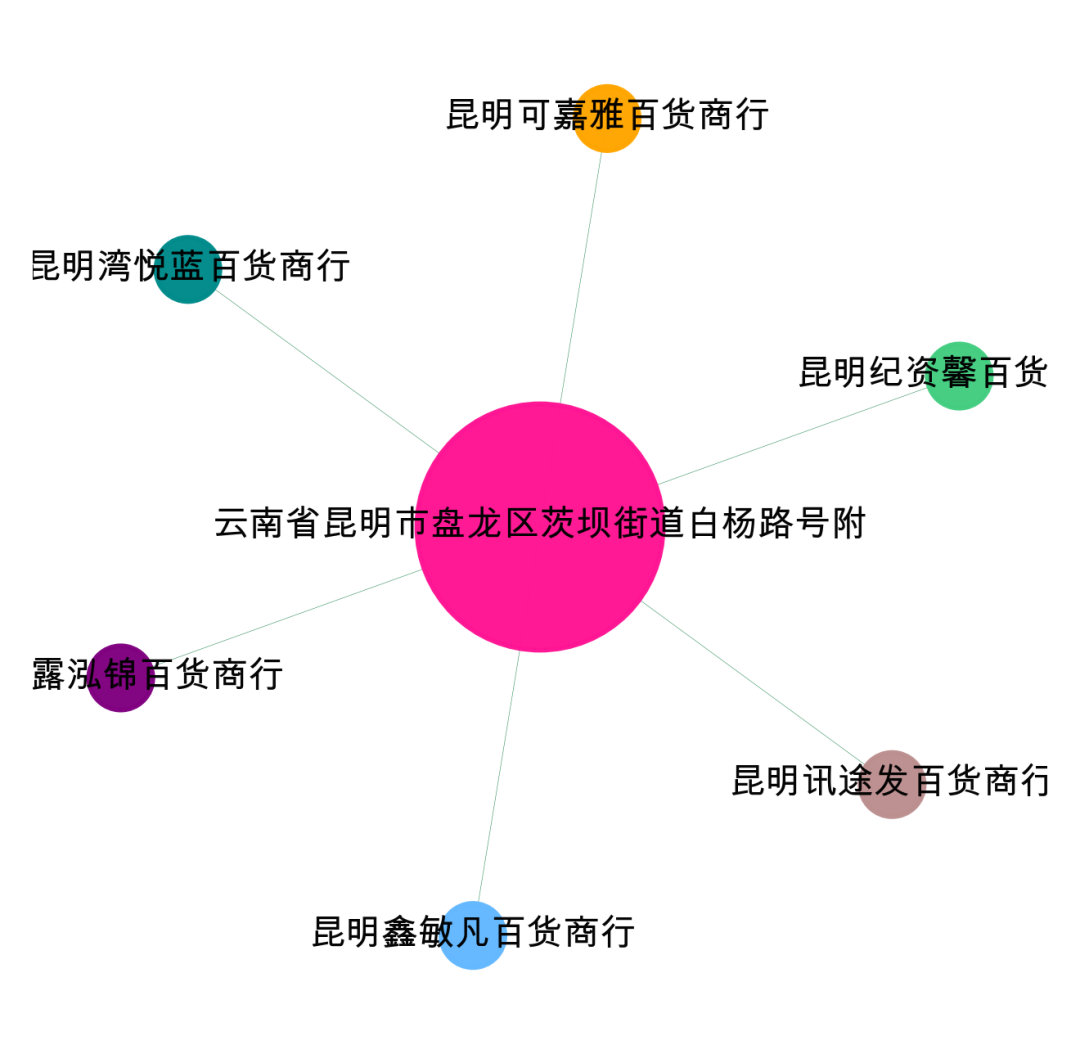
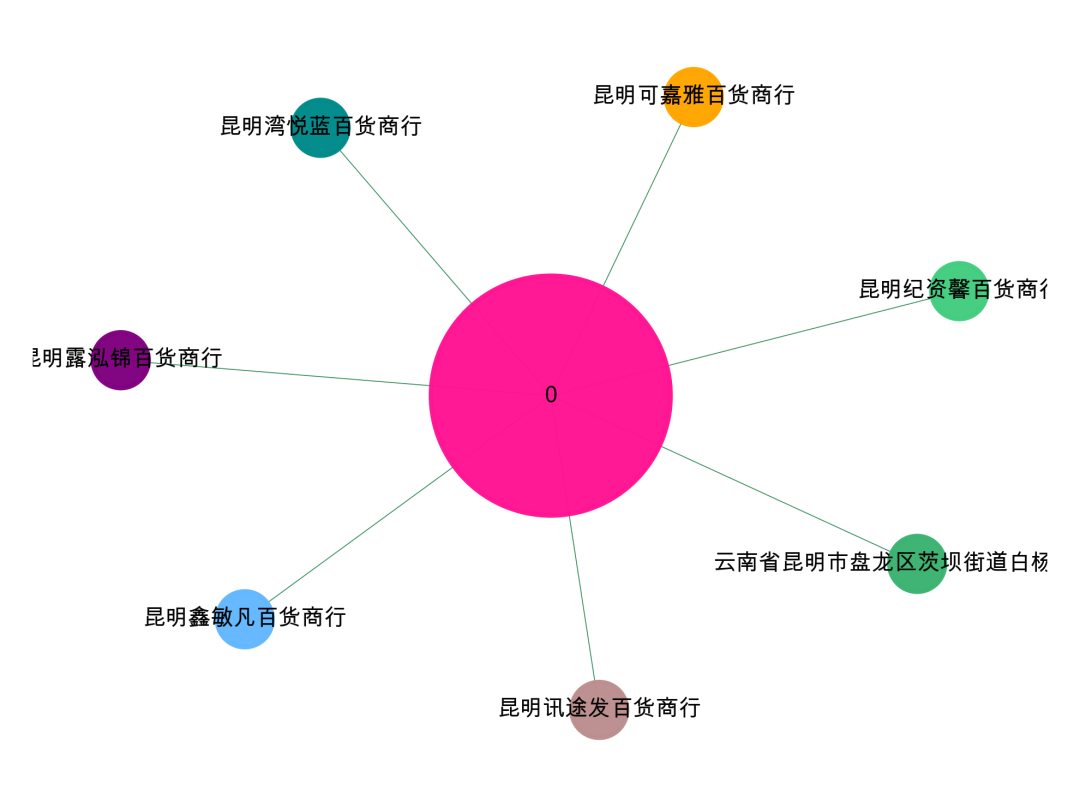
可视化第0个社群,可以看到围绕【云南省昆明市盘龙区茨坝街道白杨路号附】地址进行关联的。
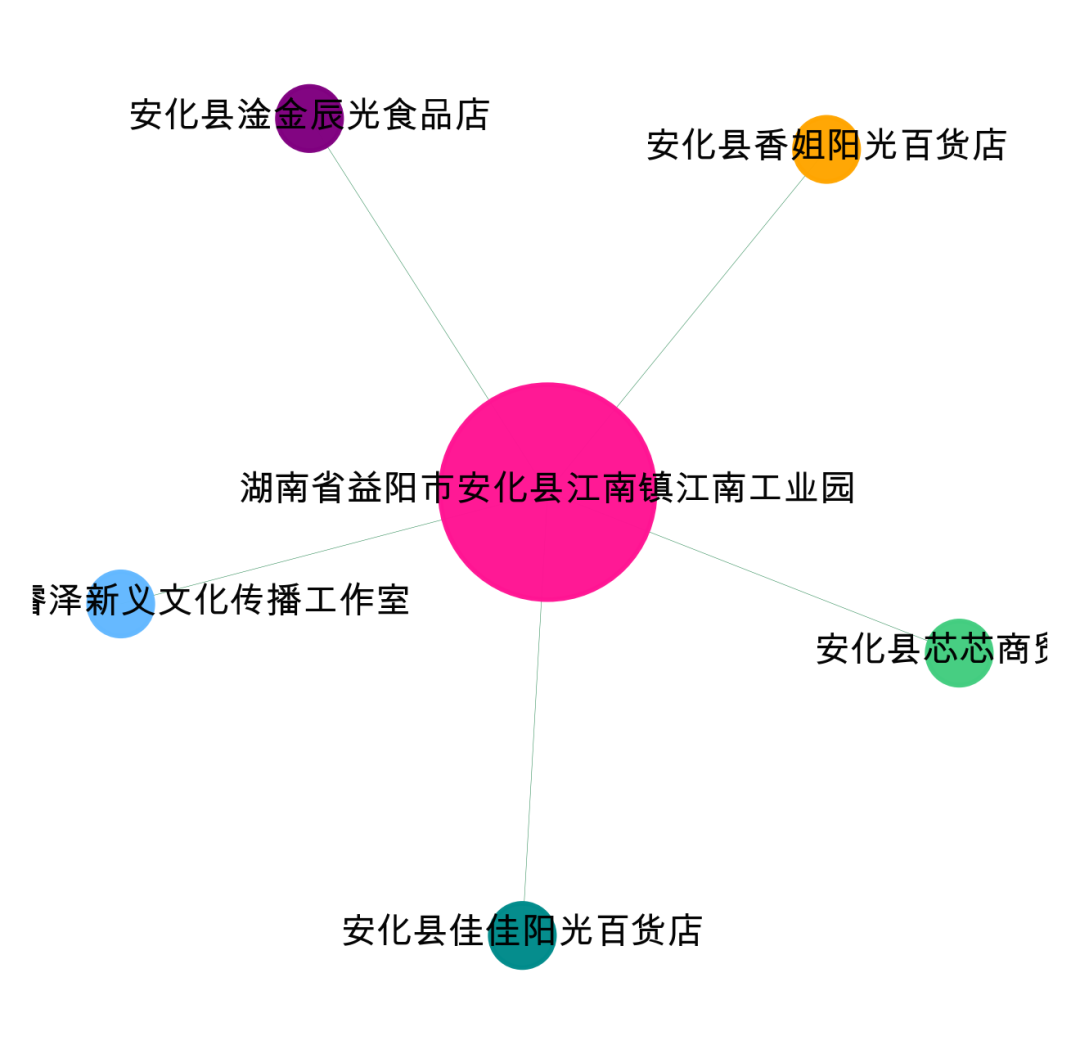
可视化第1个社群,可以看到围绕【湖南省益阳市安化县江南镇江南工业园】这个地址进行关联的。
二、DBSCAN聚类处理
1、英文数字正则
书接上回,关于风控中的地址处理,我们接着唠,看看下面这3个地址,正则之后大部分相似,但是又没办法完全匹配,就会当成独立的社群处理了,其实是有关系的,或者说相似性非常高的。
佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之号三层号(住所申报)
佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之号三层之二(住所申报)
佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之号三层之一(住所申报)
对于这种处理之后,还有微小差异的,我们怎么处理呢,有个比较好的方案就是去做聚类,为了方便学习的连贯性,我们代码重新写一遍。
对于聚类算法,我们可以不正则处理的,但是我们的地址相对比较标准,正则处理了能够进一步提高准确率,考虑处理后在聚类。
#加载所需要的包import pandas as pdimport numpy as npimport os#设置工作空间os.chdir('/Users/wuzhengxiang/Documents/DataSets/地址处理')data = pd.read_csv('公司地址数据.csv')data.head()公司名称 公司地址0 昆明纪资馨百货商行 云南省昆明市盘龙区茨坝街道白杨路233号附1-PL1 昆明可嘉雅百货商行 云南省昆明市盘龙区茨坝街道白杨路2011号附1-PL2 昆明湾悦蓝百货商行 云南省昆明市盘龙区茨坝街道白杨路114号附1-PL3 昆明露泓锦百货商行 云南省昆明市盘龙区茨坝街道白杨路355号附1-PL4 昆明鑫敏凡百货商行 云南省昆明市盘龙区茨坝街道白杨路395号附1-PL'''构建正则处理函数我们要剔除数字字母以及- 很多地址中间带着-'''import redef replace_address(text):return re.sub('[A-Za-z0-9-]','',text)# 测试下效果text = '湖南省益阳市安化-县江南镇江南工业园48-090'replace_address(text)'湖南省益阳市安化县江南镇江南工业园'# 可以看到 结果非常完美 下面进行批量化的处理,当然,不方便可以不做这一步的处理的data['公司地址'] = data['公司地址'].apply(lambda x:replace_address(x))data.head()公司名称 公司地址0 昆明纪资馨百货商行 云南省昆明市盘龙区茨坝街道白杨路号附1 昆明可嘉雅百货商行 云南省昆明市盘龙区茨坝街道白杨路号附2 昆明湾悦蓝百货商行 云南省昆明市盘龙区茨坝街道白杨路号附3 昆明露泓锦百货商行 云南省昆明市盘龙区茨坝街道白杨路号附4 昆明鑫敏凡百货商行 云南省昆明市盘龙区茨坝街道白杨路号附
做了基础的处理,我们开始做聚类处理,这里的聚类我们用DBSCAN,这个算法可以不指定标签聚类,可以根据业务自身的数据决定聚多少类,不像kmeans,需要事先指定类的数量,真是个完全没法应用的算法。
2、DBSCAN聚类
# 加载所需要的包from sklearn.feature_extraction.text import TfidfVectorizerimport jieba#进行分字处理 用结巴分词df = data['公司地址'].apply(lambda x:' '.join(jieba.lcut(x)) )df.head()# 进行向量转化vectorizer_word = TfidfVectorizer(max_features=800,token_pattern=r"(?u)\b\w+\b",min_df = 1,#max_df=0.1,analyzer='word',ngram_range=(1,2))vectorizer_word = vectorizer_word.fit(df)tfidf_matrix = vectorizer_word.transform(df)#查看词典的大小len(vectorizer_word.vocabulary_)#查看词典里面的词-部分词语vectorizer_word.vocabulary_# 进行模型训练from sklearn.cluster import DBSCANclustering = DBSCAN(eps=0.95, min_samples=1).fit(tfidf_matrix)# 我们看看分了所少个群,每个群的样本数是多少len(pd.Series(clustering.labels_).value_counts())pd.Series(clustering.labels_).value_counts()
可以看到,我们的地址被分成了3个团伙,最早没用聚类算法处理的时候,我们是分成了5个团伙,聚类把三个相似的重新聚合到一起了,比较符合我们的预期了。
# 分群标签打进原来的数据data['labels_'] = clustering.labels_# 抽取编号为0的群看看 可以看到,这个群都是吃拉肚子的反馈,聚类效果还是非常可以的for i in data[data['labels_']==2]['公司地址']:print(i)佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之号三层号(住所申报)佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之号三层之二(住所申报)佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之号三层之一(住所申报)
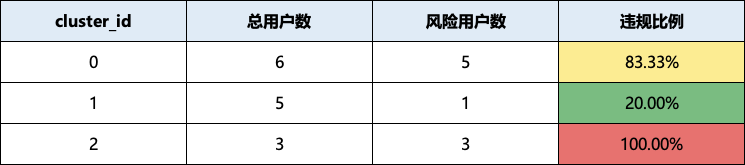
3、聚类簇画像
同样的逻辑,我们有了聚类的labels_,就可以对每个聚类簇进行画像了,计算每个类的违规情况、属性等,这样就能找到对应的风险簇类了,如下图所示。
除了对聚类的簇进行画像,我们可以把簇的ID当成图的节点,然后去做图,特别是多个介质构建异构图的时候,这种处理是非常完美的方式。
4、聚类簇+公司社群挖掘
我们把聚类簇labels_当成节点,与公司构建异构图,来进行图网络挖掘,如下所示。
# 可视化我们的数据集import networkx as nximport matplotlib.pyplot as plt# 公司名称-labels_构建图da = data[['公司名称','labels_']].valuesG = nx.Graph()for num in range(len(da)):G.add_edge(str(da[num,0]),str(da[num,1]))#节点大小设置,与度关联node_size = [G.degree(i)**0.75*80 for i in G.nodes()]import random#设置颜色 随机来点colors = ['#43CD80','DeepPink','orange','#008B8B','purple','#63B8FF','#BC8F8F','#3CB371','b','orange','y','c','#838B8B','purple','olive','#A0CBE2','#4EEE94']*500colors = colors[0:len(G.nodes())]colors = random.sample(colors, len(G.nodes()))#显示图片plt.figure(figsize=(4,3),dpi=500)## 图像显示中文的问题plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = False#kamada_kawai_layout spring_layoutnx.draw_networkx(G,pos = nx.kamada_kawai_layout(G),node_color = colors,edge_color = '#2E8B57',#with_labels=False,font_size =3,node_size = node_size,alpha = 0.98,width = 0.1)plt.axis('off')plt.show()
pos = nx.spring_layout(G)
pos = nx.kamada_kawai_layout(G)
5、单社群可视化
公司和聚类ID是多对一的关系,同一个ID也会对一个或者多个地址。我们可以考虑把是三个对象一起可视化,这样就可以一起评估公司以及地址的聚类情况。
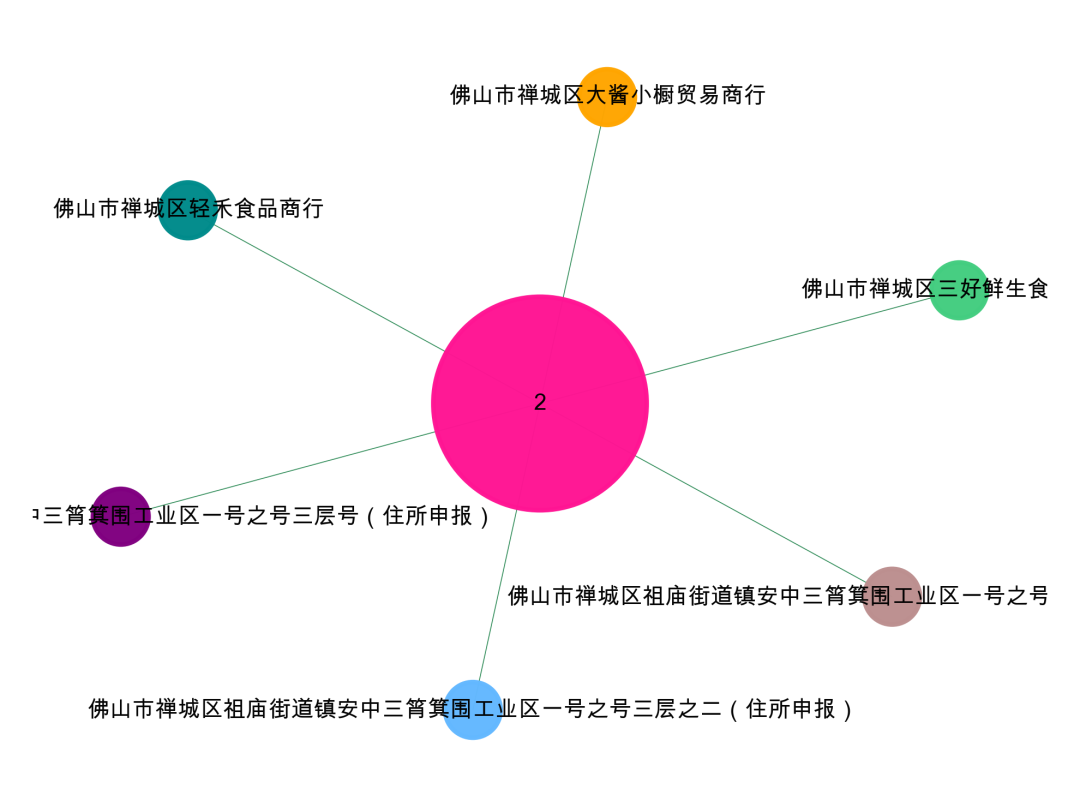
'''利用三个类型的节点进行异构构图【异构构图是个非常好的思路,我课程里有专门讲】我们这里有三个团伙,可以分别进行可视化data['labels_']==0,1,2'''d1 = data[['公司名称','labels_']][data['labels_']==2]d1.columns = {'object_id','cluster_id'}d2 = data[['公司地址','labels_']][data['labels_']==2]d2.columns = {'object_id','cluster_id'}da = pd.concat([d1,d2],axis=0).valuesG = nx.Graph()for num in range(len(da)):G.add_edge(str(da[num,0]),str(da[num,1]))#节点大小设置,与度关联node_size = [G.degree(i)**1.5*150 for i in G.nodes()]#设置颜色 随机来点colors = ['#43CD80','DeepPink','orange','#008B8B','purple','#63B8FF','#BC8F8F','#3CB371','b','orange','y','c','#838B8B','purple','olive','#A0CBE2','#4EEE94']*500colors = colors[0:len(G.nodes())]#显示图片plt.figure(figsize=(4,3),dpi=600)## 图像显示中文的问题plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = False#kamada_kawai_layout spring_layoutnx.draw_networkx(G,pos = nx.kamada_kawai_layout(G),node_color = colors,edge_color = '#2E8B57',font_size = 5,node_size = node_size,alpha = 0.98,width = 0.2)plt.axis('off')plt.show()
佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之号三层号(住所申报)
佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之号三层之二(住所申报)
佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之号三层之一(住所申报)
可以看到,这个三个地址聚类成了2,这个2和三个公司相连,就得到了我们想要的结果,把高度相似的地址当成一个地址,然后把聚类ID当成一个节点构图去做分析。
labels_ == 2
我们再来看看0、1这个聚类
labels_ == 0
labels_ ==1

到这里,我们的聚类这一部分就讲完了,其实这里的魅力,在于构建更复杂的网络,比如加入设备关系、IP关系、支付关系等。会得到非常丰富的图,且地址这个元素可以把所有的刻意规避关联起来。
三、KNN限制半径构图
今天我们写第三篇,用KNN去做相似地址的构图。当然,这个文章虽然写的是地址,但是很多场景,都是可以借鉴的。大家一定要学会举一反三。
在多提一句,很多同学,在学习算法的时候,其实是非常浅显的,找个demo,然后跑个案例,可能就觉得自己会了。下面的文章,如果看不懂的,可以参考我之前写的文章:?
如果不缺钱的,也可以买个我的课,其中一个类似的案例也讲解的比较细。我们回到开始正文,先看看地址数据的格式。
需要练习数据的关注「小伍哥聊风控」后台回复【地址数据】。
1、文本tf-idf转换
开始我们要对文本进行处理,可以简简单单的进行tf-idf转换,也可以使用深度学习,得到更稠密的矩阵。
#加载所需要的包import pandas as pdimport numpy as npimport os#读取数据 - 需要数据的关注「小伍哥聊风控」后台回复【地址数据】os.chdir('/Users/wuzhengxiang/Documents/DataSets/地址处理')data = pd.read_csv('公司地址数据.csv')print(data.head(20))# 结巴分词-测试import jiebajieba.lcut('小伍哥全宇宙最帅')['小伍', '哥', '全宇宙', '最帅']#进行分字处理 用结巴分词df = datadf = df['公司地址'].apply(lambda x:' '.join(jieba.lcut(x)) )df.head()# 进行向量转化 tf-idfvectorizer_word = TfidfVectorizer(max_features=20000,token_pattern=r"(?u)\b\w+\b",min_df = 1,analyzer='word',ngram_range=(1,2))vectorizer_word = vectorizer_word.fit(df)tfidf_matrix = vectorizer_word.transform(df)#查看词典的大小print(len(vectorizer_word.vocabulary_))109#查看词典里面的词-部分词语vectorizer_word.vocabulary_{'云南省': 51,'昆明市': 72,'盘龙区': 85,'茨坝': 93,'街道': 95,'白杨': 81,'路': 98,'233': 13}
上面的代码,我们得到了文本的向量表示,下面就是KNN算法的地方了。
2、KNN半径构图
KNN算法里面有两个图算法:kneighbors_graph 和 radius_neighbors_graph
radius_neighbors_graph构建限制半径近邻图,也就是在一定距离范围内的邻居,我们就算是尽量,超过的就不要了,我们也可以用kneighbors_graph,给每个节点找相同个数的邻居。
from sklearn.neighbors import radius_neighbors_graphfrom sklearn.neighbors import kneighbors_graph# 构建限制半径近邻图,我们也可以用kneighbors_graph,给每个节点找相同个数的邻居A = radius_neighbors_graph(tfidf_matrix,radius = 0.99,mode ='connectivity',include_self=False)A.toarray()array([[0., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0.],[1., 0., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0.],[1., 1., 0., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0.],[1., 1., 1., 0., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0.],[1., 1., 1., 1., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],[1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 1., 0., 1., 1., 1., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 1., 1., 0., 1., 1., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 1., 1., 1., 0., 1., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 1.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 0.]])# 数据转换成图形式G = nx.from_numpy_matrix(A.toarray())
通过KNN,我们得到的是一个邻接矩阵,也就是图的矩阵化表现形式。邻接矩阵可以通过 nx.from_numpy_matrix读取,形成图的格式,方便后续的可视化或者是社群挖掘。
3、社群挖掘
# 并用极大连通子图去挖掘import networkx as nximport matplotlib.pyplot as plt# 数据转换成图形式G = nx.from_numpy_matrix(A.toarray())# 找到所有连通子图com = list(nx.connected_components(G))# 将 列表-字典 整理成数据表格形式df_com = pd.DataFrame()for i in range(0, len(com)):d = pd.DataFrame({'group_id': [i] * len(com[i]), 'user_id': list(com[i])})df_com = pd.concat([df_com,d])# 查看数据结果df_comgroup_id user_id0 0 01 0 12 0 23 0 34 0 45 0 50 1 61 1 72 1 83 1 94 1 100 2 111 2 122 2 13##### 用这个scipy库的极大连通子图算法,就不用转换了,结果本来就是稀疏矩阵了from scipy.sparse.csgraph import connected_componentsfrom scipy.sparse import csr_matrixn_components, group_id = connected_components(csgraph = A,directed = False,connection = 'weak',return_labels = True)print(n_components)print(group_id)[0 0 0 0 0 0 1 1 1 1 1 2 2 2]
4、单社群可视化
上面我们就得到了各个样本划分的团伙,为了更直观,我们下一步做可视化,这里的可视化理解难度就比较大了,大家仔细研究
# 分群数据还原回到原始数据data['group_id'] = pd.Series(group_id)pd.Series(group_id).value_counts().head(20)# 单独查看某个团伙data[data['group_id']==0].sort_values(by='公司名称')公司名称 公司地址 group_id1 昆明可嘉雅百货商行 云南省昆明市盘龙区茨坝街道白杨路2011号附1-PL 02 昆明湾悦蓝百货商行 云南省昆明市盘龙区茨坝街道白杨路114号附1-PL 00 昆明纪资馨百货商行 云南省昆明市盘龙区茨坝街道白杨路233号附1-PL 05 昆明讯途发百货商行 云南省昆明市盘龙区茨坝街道白杨路310号附1-PL 04 昆明鑫敏凡百货商行 云南省昆明市盘龙区茨坝街道白杨路395号附1-PL 03 昆明露泓锦百货商行 云南省昆明市盘龙区茨坝街道白杨路355号附1-PL 0# 根据索引取出可视化团伙的文本comment_group = data['公司地址'][data[data['group_id']==0].index].reset_index(drop=True)labels =dict(comment_group)labels# 根据索引取出可视化团伙的tf-idftfidf_group = tfidf_matrix.toarray()[data[data['group_id']==0].index]# 重新计算连通矩阵A = radius_neighbors_graph(tfidf_group,radius = 0.99,mode ='connectivity',include_self=False)# 地址数据可视化import networkx as nximport matplotlib.pyplot as plt# 矩阵格式转换成图格式G = nx.from_numpy_matrix(A.toarray())## 图像显示中文的问题plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = False# 颜色设置colors = ['r','c','y','c']*1000#colors = ['#008B8B','r','b','orange','y','c','DeepPink','#838B8B','purple','olive','#A0CBE2','#4EEE94']*500colors = colors[0:len(G.nodes())]#kamada_kawai_layout spring_layoutplt.figure(figsize=(4,4),dpi=400)nx.draw_networkx(G,pos = nx.spring_layout(G),node_color = colors,labels = labels,node_size = 500,font_size = 5,width=0.2,alpha=1)plt.axis('off')plt.show()
data['group_id']==0
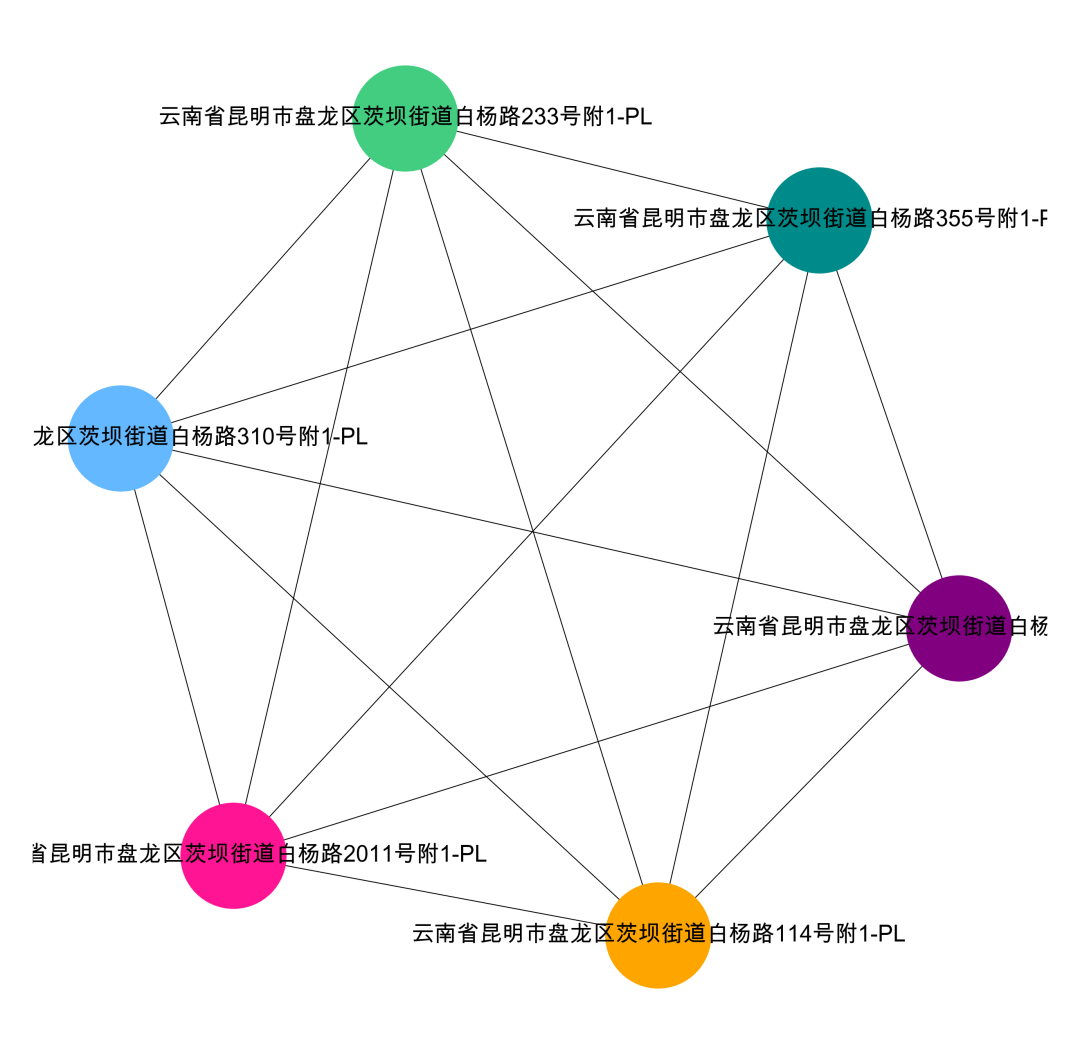
data['group_id']==1
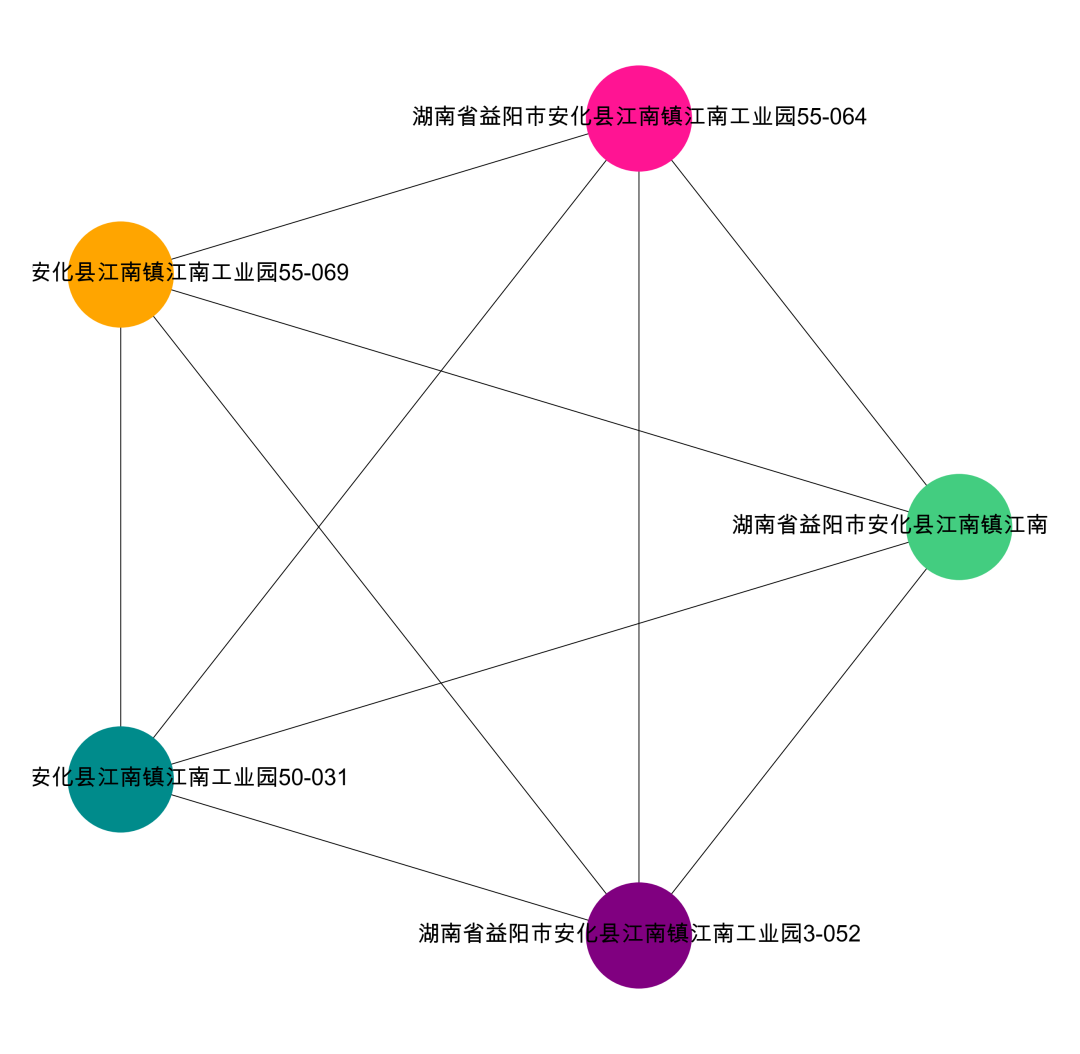
data['group_id']==2
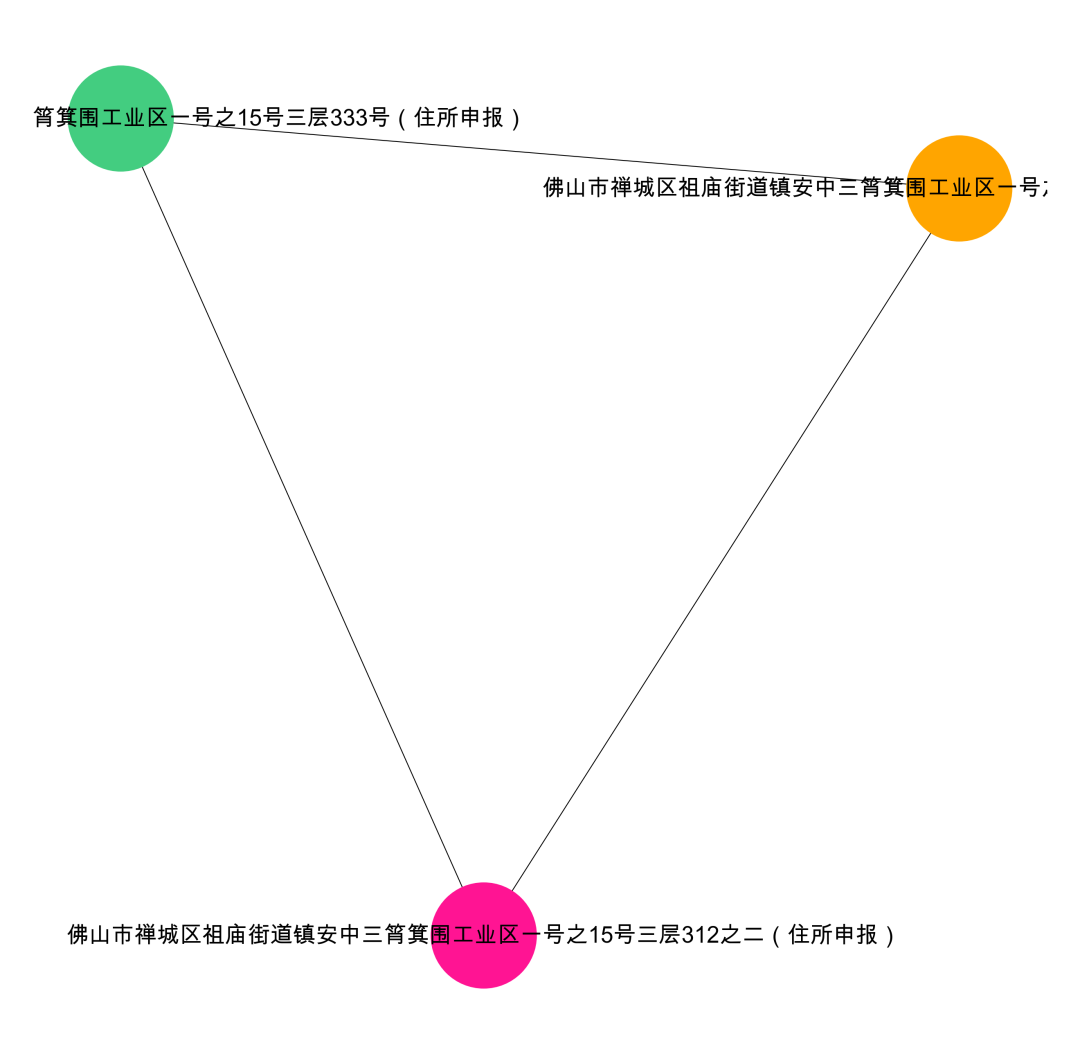
四、基于文本相似度
大家好,我是小伍哥,今天我们继续写风控中的地址处理,前面写了3种处理方法。对于相似度计算,可能是大家听得最多的了,之前一直没写,我们还是用上次的数据集,我们开始正文,先看看地址数据的格式。
对于相似度度计算,最可怕的就是笛卡尔积,基本上跑不出来,所以在计算的时候,一定要进行降维处理,这里挺三个降维思路:
-
省+市+区匹配降噪:根据地址的【省+市+区】为主键,匹配后再计算相似度
-
截取固定长度降噪:截取地址的前N位匹配后进行相似度计算
-
截取固定比例降噪:截取地址前一定比例的数据后计算相似度。
比如有300w的地址数据
直接计算:3000000*3000000 = 9000000000000=90000亿!太夸张,9万亿。
如果地址包含30个省的,且均匀分布,只匹配到省级,则有:100000*100000*30 = 300000000000=3000亿,虽然很多,但是已经大幅度下降了30倍。
如果匹配到县级,下降幅度更大,假设有3000个县,则有:1000*1000*3000=3000000000=30亿。直接下降了3000倍.
所有的地址都去重、或者正则话、或者更细的行政区划,都可以进一步降维,所以很多相似问题,在没有降维的条件下,基本上不可计算。有时候,要想好怎么去降维,比精准更重要。
地址降维,其实还有个好处,很多时候更加能提高准确性。
上海乌鲁木齐中路99号
乌鲁木齐上海中路99号
比如这两个地址,其实是八竿子打不着的,如果直接采用不考虑语序的文本相似计算,适得其反,会得出极高的准确率。但是降维了,就不会出现在同一个区块里了。
1、黑名单相似查找
一般来说,如果你有黑地址,那可以通过相似计算,直接去做拓展计算了,我下面写个示例,我这里为了简单,直接用截取的方式做降维,大家根据自己的数据,去设计降维。
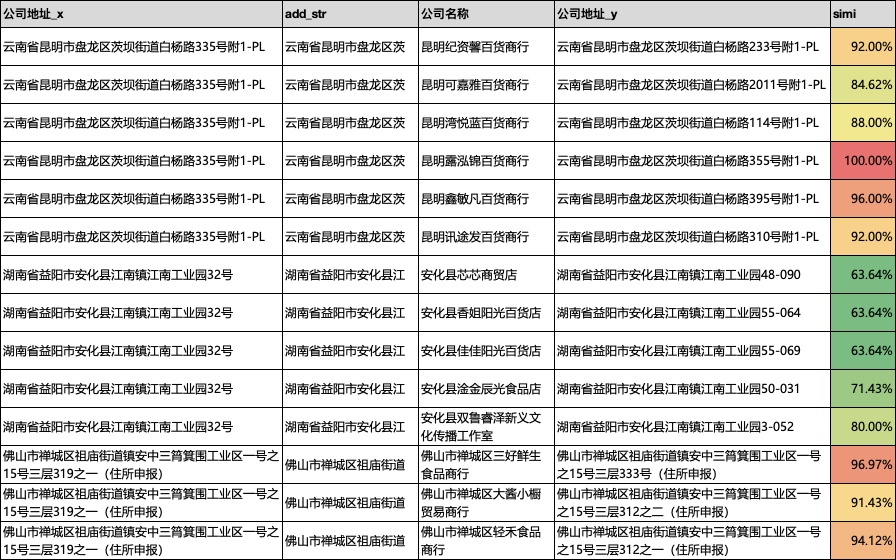
#加载所需要的包import pandas as pdimport numpy as npimport os#设置工作空间os.chdir('/Users/wuzhengxiang/Documents/DataSets/地址处理')data = pd.read_csv('公司地址数据.csv')data.head()# 构建几个黑样本black =pd.DataFrame ({'公司地址':['湖南省益阳市安化县江南镇江南工业园32号','云南省昆明市盘龙区茨坝街道白杨路335号附1-PL','佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之15号三层319之一(住所申报)']})black['add_str'] = black['公司地址'].str.slice(0,10)# 原来的地址也做个截取data['add_str'] = data['公司地址'].str.slice(0,10)da = black.merge(data,how='inner',on='add_str',)def add_simi(x,y):x = set(x)y = set(y)if len(x.union(y))>0:return len(x.intersection(y))/len(x.union(y))else:return 0# 测试下x = '湖南省益阳市安化县江南镇江南工业园32号'y = '湖南省益阳市安化县江南镇业园32号'add_simi(x,y)# 进行相似计算da['simi'] = da.apply(lambda row:add_simi(row['公司地址_x'],row['公司地址_y']), axis=1)# 保存相似计算数据da.to_csv('data_simi_add.csv',header=True)
可以看到,我们得到了如下的一个相似度识别结果,可以根据自己的业务需求,设置适当的阈值,就可以使用了。
2、相似构图-包含黑样本
# 可视化我们的数据集import networkx as nximport matplotlib.pyplot as pltdf = da[['公司地址_x','公司地址_y']].valuesG = nx.Graph()for num in range(len(da)):G.add_edge(str(df[num,0]),str(df[num,1]))#节点大小设置,与度关联node_size = [G.degree(i)**0.75*100 for i in G.nodes()]#设置颜色 随机来点colors = ['#43CD80','DeepPink','orange','#008B8B','purple','#63B8FF','#BC8F8F','#3CB371','b','orange','y','c','#838B8B','purple','olive','#A0CBE2','#4EEE94']*500colors = colors[0:len(G.nodes())]#显示图片plt.figure(figsize=(4,4),dpi=500)## 图像显示中文的问题plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = False#kamada_kawai_layout spring_layoutnx.draw_networkx(G,pos = nx.kamada_kawai_layout(G),node_color = colors,edge_color = '#2E8B57',#with_labels=False,font_size =3,node_size = node_size,alpha = 0.98,width = 0.1)plt.axis('off')plt.show()
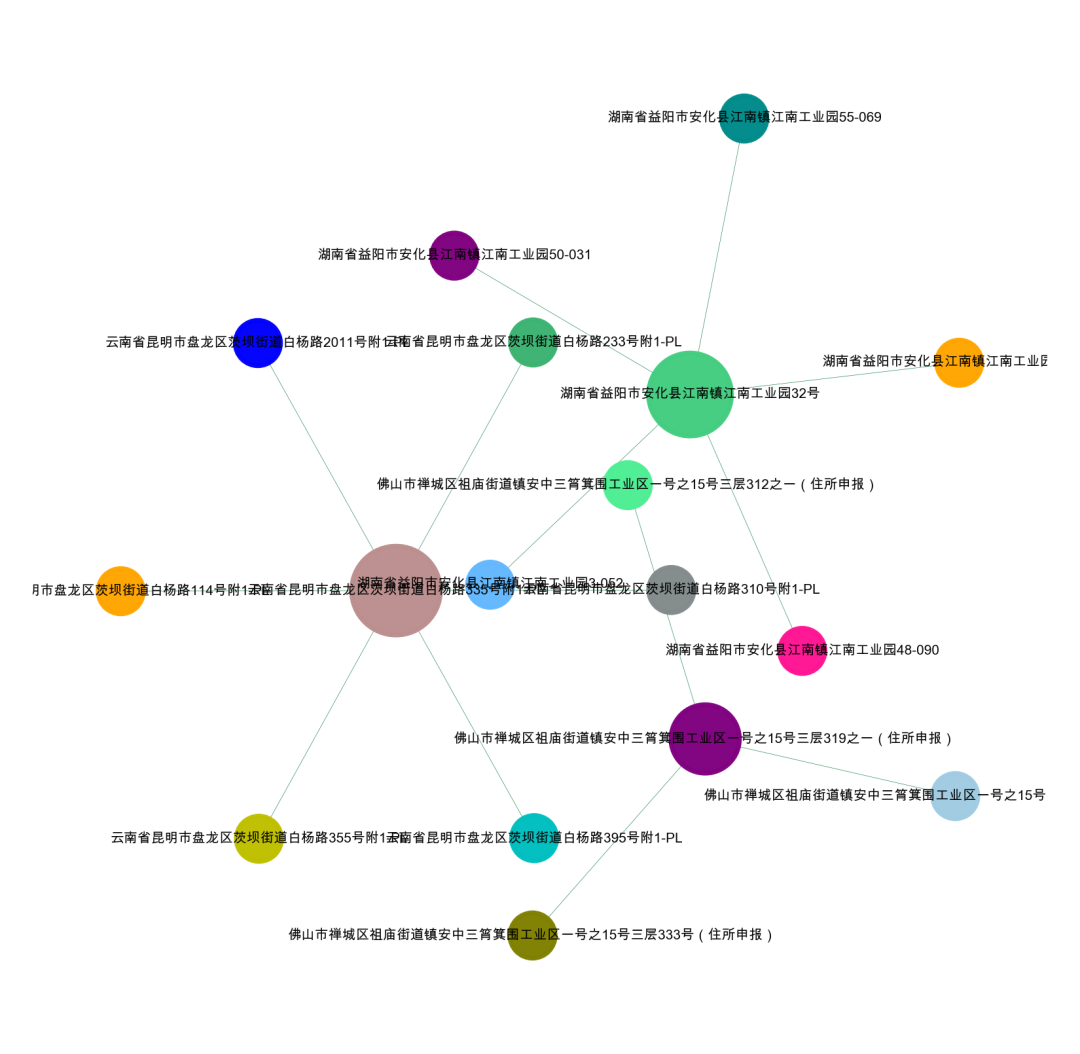
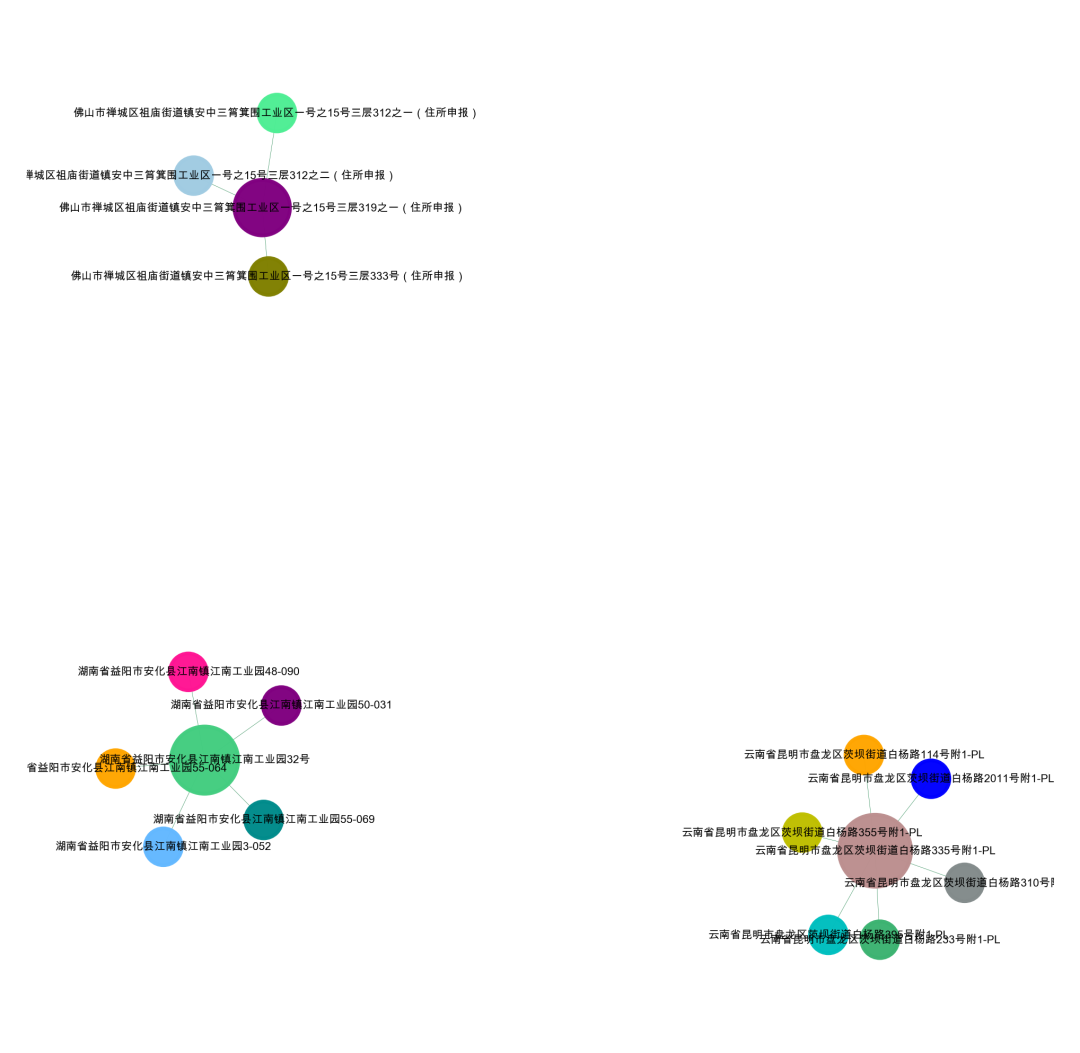
3、全量地址构图
#加载所需要的包import pandas as pdimport numpy as npimport osimport networkx as nximport matplotlib.pyplot as plt#设置工作空间os.chdir('/Users/wuzhengxiang/Documents/DataSets/地址处理')data = pd.read_csv('公司地址数据.csv')data.head()# 原来的地址也做个截取data['add_str'] = data['公司地址'].str.slice(0,10)da = data.merge(data,how='inner',on='add_str',)da = da[da['公司地址_x']!=da['公司地址_y']]def add_simi(x,y):x = set(x)y = set(y)if len(x.union(y))>0:return len(x.intersection(y))/len(x.union(y))else:return 0#相似度计算,并选择合适的相似比例,我这里选择的是0.9da['simi'] = da.apply(lambda row:add_simi(row['公司地址_x'],row['公司地址_y']), axis=1)# 可视化我们的数据集import networkx as nximport matplotlib.pyplot as plt# 转换成图数据类型df = da[da['simi']>=0.7]df = df[['公司地址_x','公司地址_y']].valuesG = nx.Graph()for num in range(len(df)):G.add_edge(str(df[num,0]),str(df[num,1]))#节点大小设置,与度关联node_size = [G.degree(i)**0.75*50 for i in G.nodes()]#设置颜色 随机来点colors = ['#43CD80','DeepPink','orange','#008B8B','purple','#63B8FF','#BC8F8F','#3CB371','b','orange','y','c','#838B8B','purple','olive','#A0CBE2','#4EEE94']*500colors = colors[0:len(G.nodes())]#显示图片plt.figure(figsize=(3,3),dpi=500)## 图像显示中文的问题plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = False#kamada_kawai_layout spring_layoutnx.draw_networkx(G,pos = nx.kamada_kawai_layout(G),node_color = colors,edge_color = '#2E8B57',#with_labels=False,font_size =3,node_size = node_size,alpha = 0.98,width = 0.1)plt.axis('off')plt.show()
我们可以看看不同相似度下的图怎么样
simi>=0.9
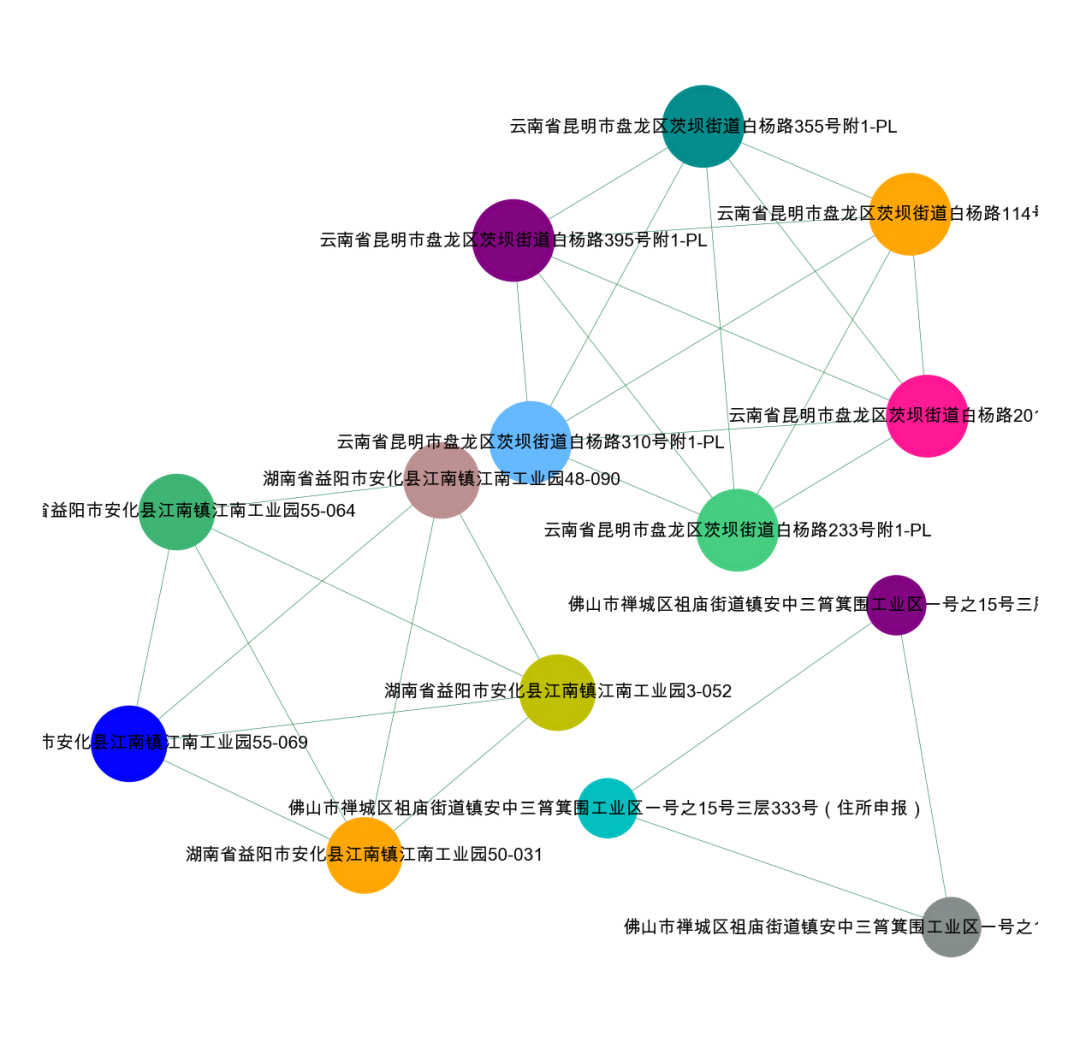
simi>=0.9
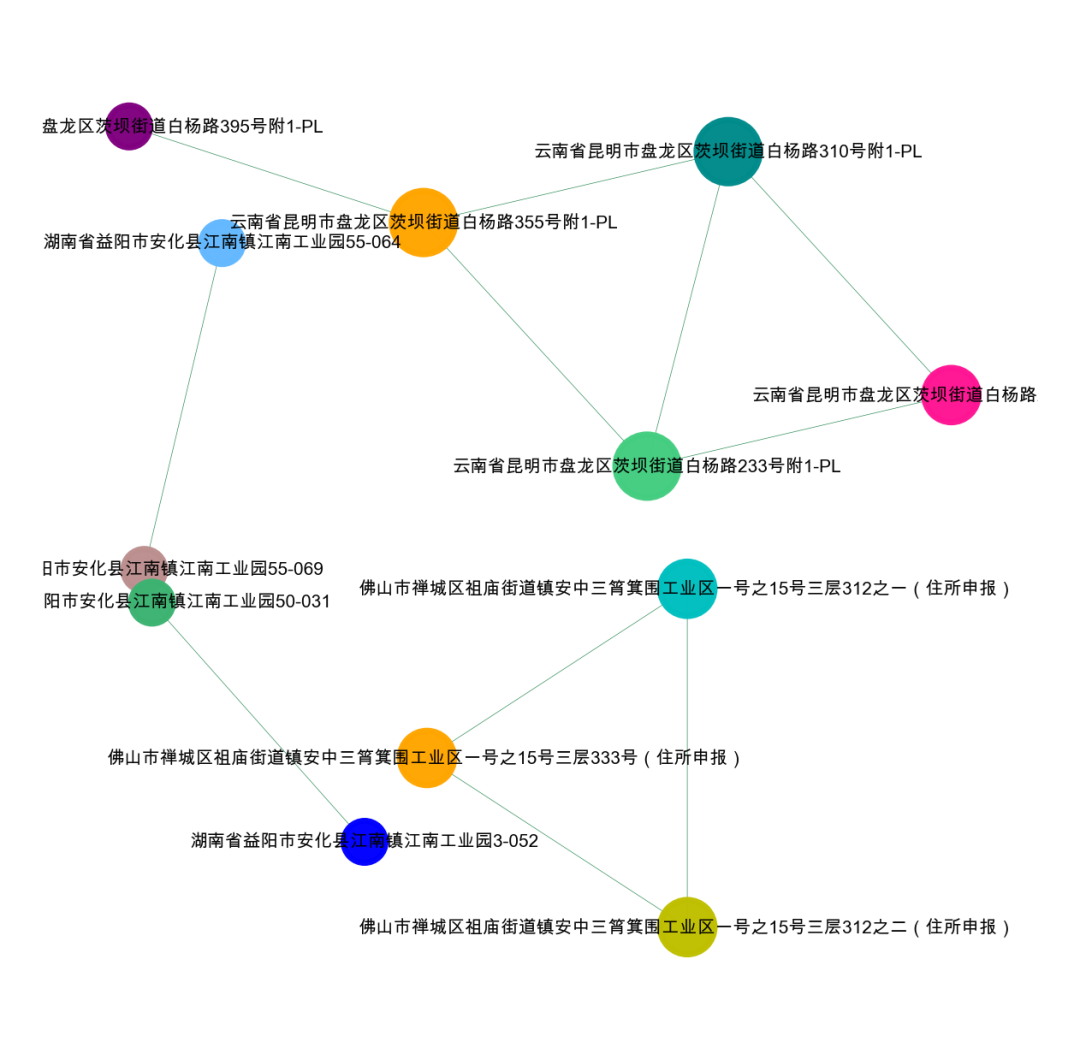
可以看到,我们的相似度越高,剩下的节点越少,也就是团伙越严格,可以根据自己的业务需求,测试不用的相似度。
4、社群发现
对形成的关系图进行分群,可以看到,我们分成了4个群。这样可以单独度每个群进行可视化。
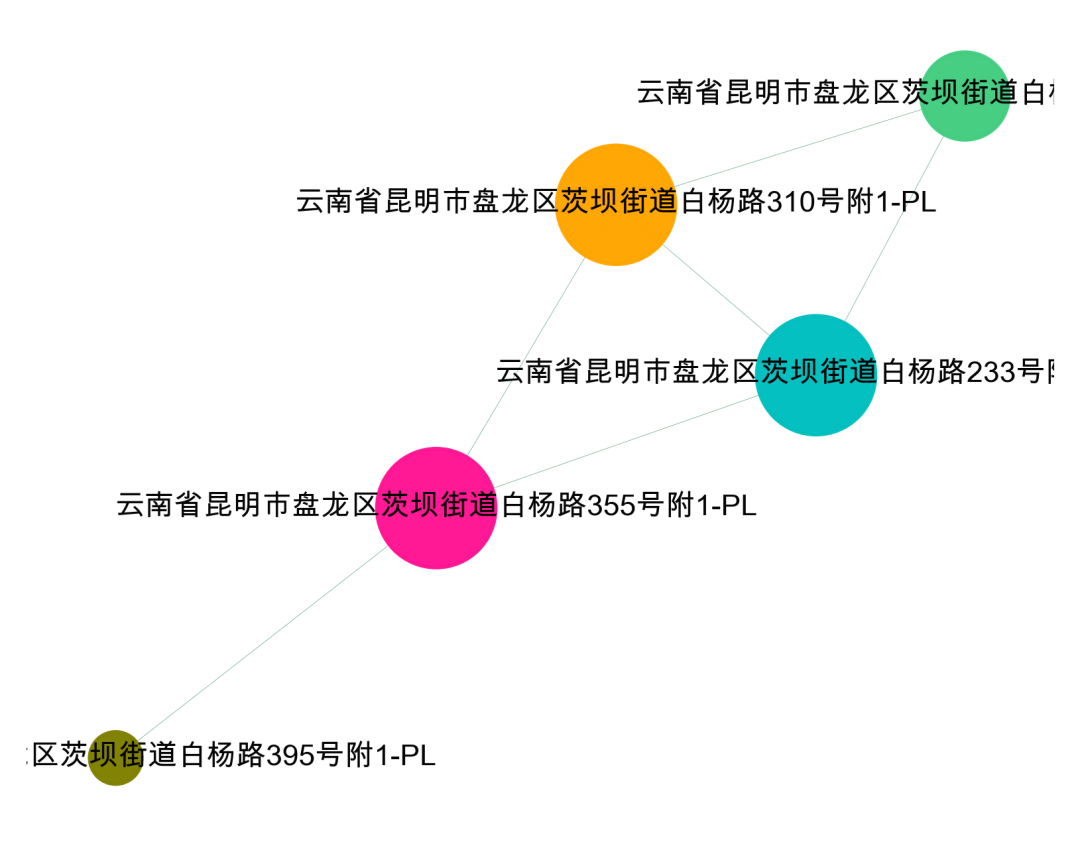
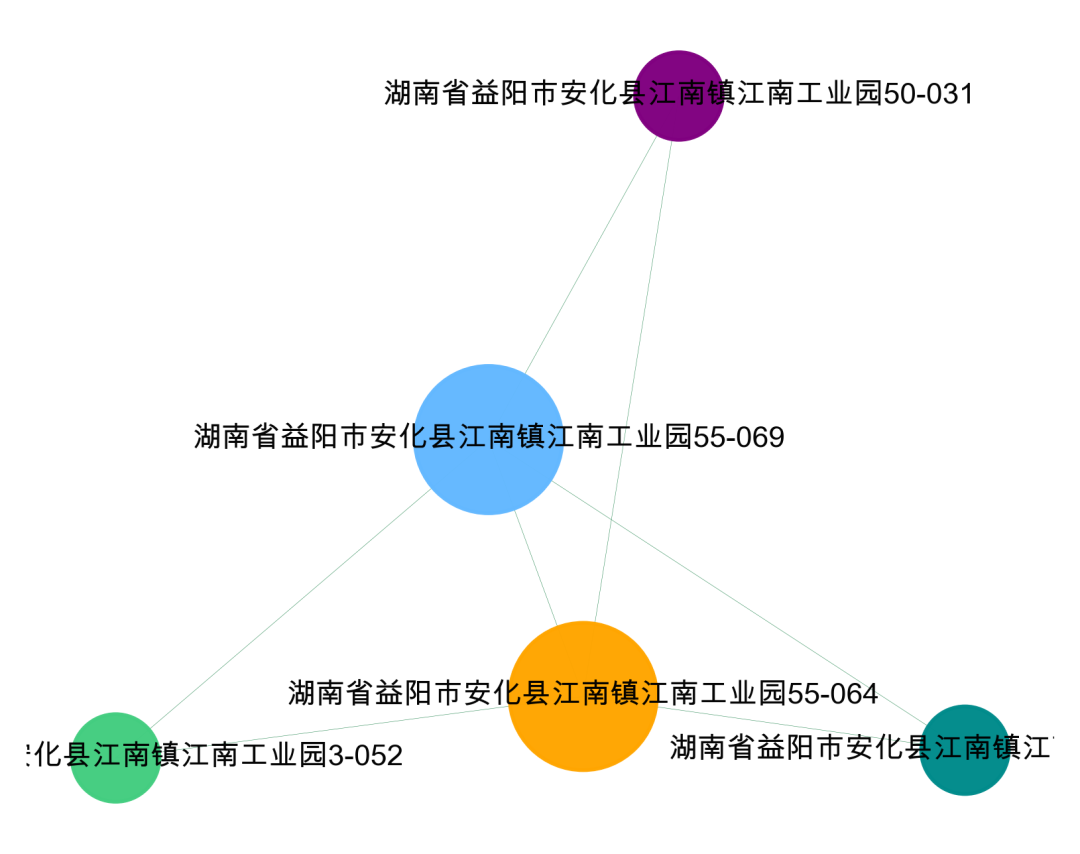
import networkx as nximport matplotlib.pyplot as plt# 找到所有连通子图df = da[['公司地址_x','公司地址_y']].valuesG = nx.Graph()for num in range(len(da)):G.add_edge(str(df[num,0]),str(df[num,1]))# 用极大连通子图算法com = list(nx.connected_components(G))# 打印看看什么格式的,可以看到得到的结果为列表-集合格式print(com)# 将 列表-字典 整理成数据表格形式df_com = pd.DataFrame()for i in range(0, len(com)):d = pd.DataFrame({'group_id': [i] * len(com[i]), 'object_id': list(com[i])})df_com = pd.concat([df_com,d])# 查看数据结果df_comgroup_id object_id0 0 云南省昆明市盘龙区茨坝街道白杨路395号附1-PL1 0 云南省昆明市盘龙区茨坝街道白杨路233号附1-PL2 0 云南省昆明市盘龙区茨坝街道白杨路2011号附1-PL3 0 云南省昆明市盘龙区茨坝街道白杨路310号附1-PL4 0 云南省昆明市盘龙区茨坝街道白杨路355号附1-PL0 1 湖南省益阳市安化县江南镇江南工业园55-0691 1 湖南省益阳市安化县江南镇江南工业园55-0640 2 湖南省益阳市安化县江南镇江南工业园3-0521 2 湖南省益阳市安化县江南镇江南工业园50-0310 3 佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之15号三层312之二(住所申报)1 3 佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之15号三层312之一(住所申报)2 3 佛山市禅城区祖庙街道镇安中三筲箕围工业区一号之15号三层333号(住所申报)
5、单社群可视化
#提取某一个群组进行可视化,根据每个社群的节点,去找边。可以去调整不同的准确率di = da[da['simi']>=0.9]i= 0edges = []for k,v in zip(di['公司地址_x'].tolist(),di['公司地址_y'].tolist()):if k in com[i] or v in com[i]:edges.append((k,v))#转换成图结构,可以从元组列表直接构建图G = nx.Graph(edges)#节点大小设置,与度关联node_size = [G.degree(i)**1.5*200 for i in G.nodes()]#设置颜色 随机来点colors = ['#43CD80','DeepPink','orange','#008B8B','purple','#63B8FF','#BC8F8F','#3CB371','b','orange','y','c','#838B8B','purple','olive','#A0CBE2','#4EEE94']*500import randomcolors = random.sample(colors, len(G.nodes()))#设置显示图片大小plt.figure(figsize=(5,4),dpi=400)## 图像显示中文的问题plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = False#可以替换两种不同的布局看看效果 kamada_kawai_layout spring_layoutnx.draw_networkx(G,pos = nx.spring_layout(G),node_color = colors,edge_color = '#2E8B57',#with_labels=False,font_size = 8,node_size = node_size,alpha = 0.98,width = 0.1)plt.axis('off')plt.show()
这篇关于会这个4个方法,风控中的地址再也不愁了的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



