本文主要是介绍Cassandra nodetool repair 原理、操作详细解释,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、为什么需要修复?
Cassandra 为了保证数据的可用性不丢失,一个数据往往多个节点备份。 当一个节点数据发生改变,其他备份节点节点可能因为宕机、网络不通畅,高负载导致长时间gc原因, 数据没有及时同步,会出现数据不一致的情况,这个时候需要进行node repair

二、Casandra 三种修复方式:
1、Hinted Handoff(写入修复)
数据在写入的时候没有完成同步,会在协调节点上记录hint log (留下日志记录)。 当备份节点恢复正常,可以写入的时候,系统根据日志记录,完成修复。

可以配置的参数(Cassandra.yaml)
•hinted_handoff_enabled
•max_hint_window_in_ms (默认3 小时)
•write_request_timeout_in_ms(默认1s)
2、读修复
Cassandra 根据读 Consistency Level , 读取相应的副本,并比较副本内容,返回最新版本数据。
如果副本之间内容不一致,后台就会启动读修复,以最新版本的数据为基准修复其他节点数据

3、反熵修复(手动修复)
3.1 主要使用的是 nodetool repair 命令
3.2 意义:
集群负载过大,频繁的宕机,或者删除数据,会导致数据不一致,读修复和写修复有时候不能维持集群的健康.
3.3 过程:
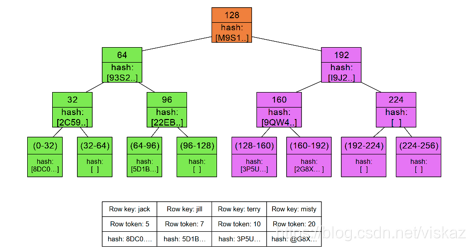
1)为每个副本构建 Merkle tree
2)比较Merkle tree , 发现不一致,进行修复
(merkle树的定义可以参考: https://www.cnblogs.com/s-lisheng/p/11301063.html)
三、Casandra 手动修复命令参数详解
1、Full repair vs incremental repair (-full vs -inc)
- Full repair
为所有sstable构建完全Merkle tree,做一次全面扫描, 对所有不一致数据数据进行修复 - Incremental Repair:
将数据分成repaired 和 unrepaired, 只修复unrepaired的数据33
Parallel repair vs Sequential repair (-seq vs -par)
- Sequential Repair
先为副本创建快照, 协调节点使用Merkle tree 依次比较各个副本,遇到差异使用快照对各个节点进行修复
特点: 对节点CPU资源占用较小,但是修复速度慢
- Parallel Repair
同时为各个节点创建Merkle tree, 然后同时比较,对不一致节点数据进行修复
特点: 对节点CPU等资源占用较大, 但是修复速度快
3、 partitioner range repair (-pr)
概念:Token Ranges
[参考]
假设有一个集群:
(节点数:10; Token:100; 复制因子:3)
数据分布如下:
token1–10 : N1, N2, N3;
token:11–20 :N2, N3, N4;
token:21–30 :N3, N4, N5
…
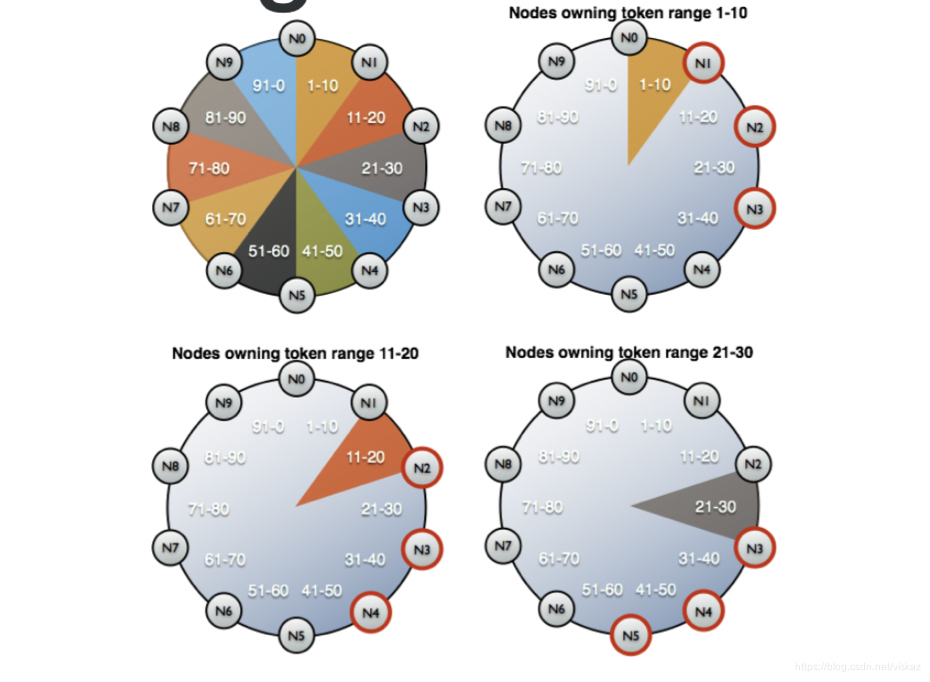
N3 拥有token 数为 1-30 的数据,假设在N3 运行 nodetool repair, 它会修复token 1-30的数据
N4 拥有token 树为 11-40 的数据,如果在N4上运行nodetool repair, 它会修复token 11 - 40 的数据, 发现重复修复,效率降低了,所以需要使用 partitioner range repair
如果在N3上运行 nodetool repair -pr, 只会修复 token 为20 - 30 的数据,避免重复修复
使用方法: 这个命令必须在集群中每个节点上运行,否则会导致部分数据没有修复
四、Casandra 手动修复集群的建议
- 定时运行 nodetool repair , 及时没有删除数据,服务器宕机等情况
- 节点宕机之后,故障处理完毕,重新加入集群
- 对某些数据进行修改之后(如删除), 但是这些数据不经常被读
- 恢复丢失数据或者破损了的SSTable( 这种必须使用full repair)
参考网站:
Repairing nodes
Anticompaction in Cassandra 2.1
这篇关于Cassandra nodetool repair 原理、操作详细解释的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




