本文主要是介绍MySQL非正常关闭导致无法再次启动的问题以及无法启动如何将数据库表和数据进行转储详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、解决方式1
1.查阅官网文档,在mysql配置文件中/etc/my.cnf添加配置,成功启动
[mysqld]
innodb_force_recovery = 1
2、启动成功后使用Navicat连接数据库,由于配置了innodb_force_recovery = 1,此时数据库只能读取,不能插入、修改和删除。但是这已经足够了
3、右键要转储数据的【数据库 】------- 【转储SQL文件】 ------- 【结构和数据】
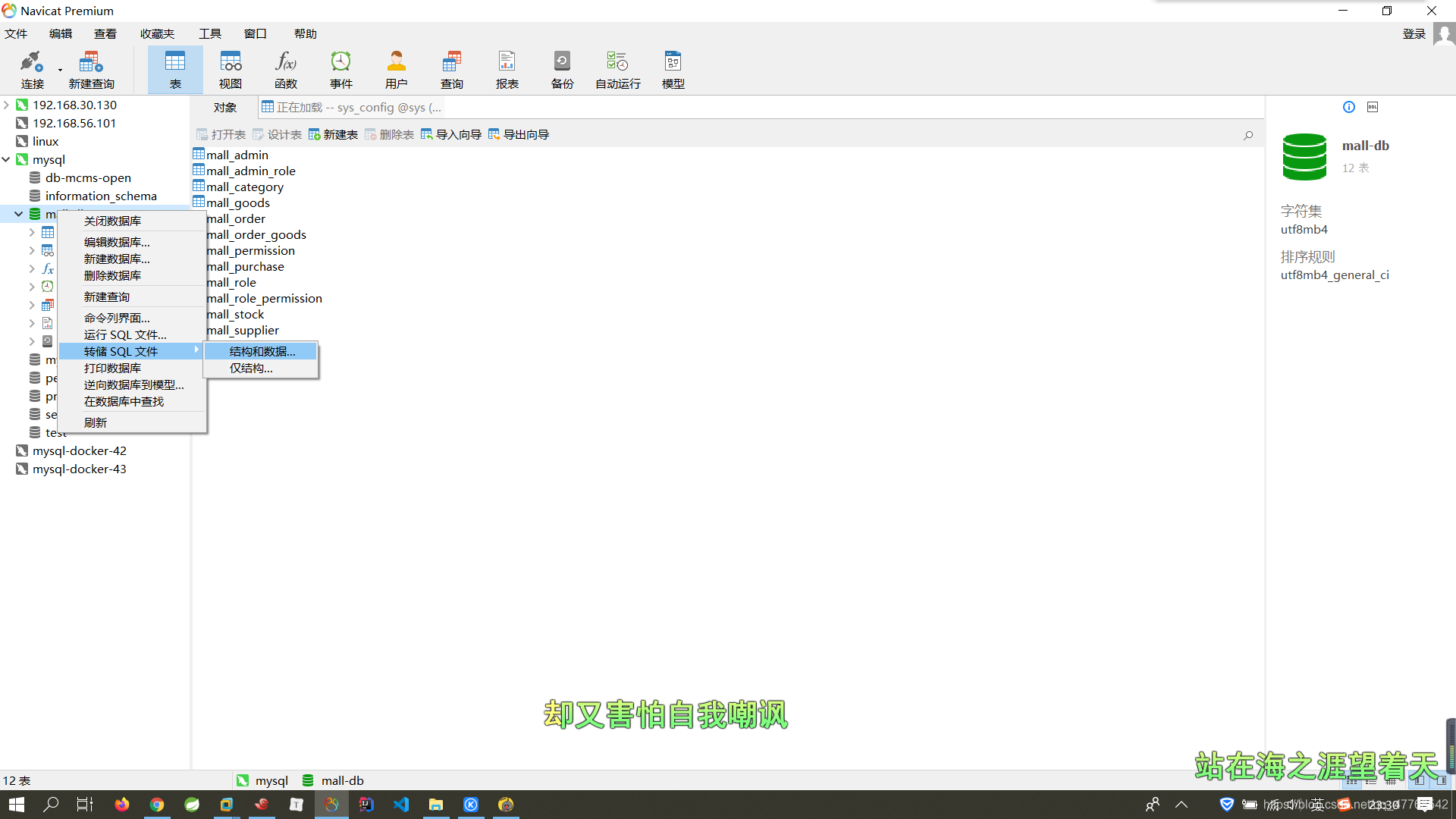
4、保存到自己想保存的位置
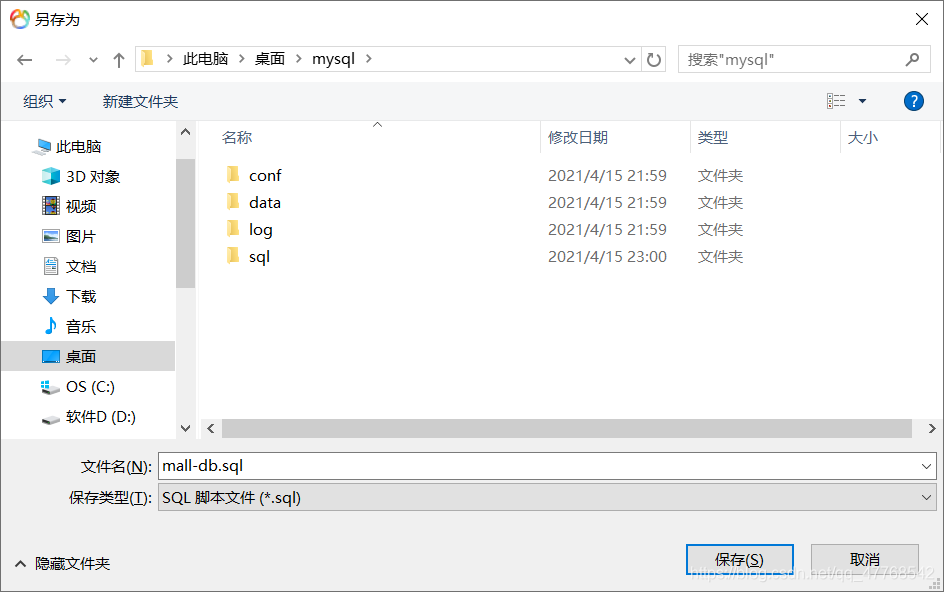
5、点击保存即可将数据库的各个表的结构和数据保存为SQL文件了
二、解决方式2
1.查阅官网文档,在mysql配置文件中/etc/my.cnf添加配置,成功启动
[mysqld]
innodb_force_recovery = 1
2.备份数据库
mysqldump -h172.168.2.100 -uroot -p -A > mysql_all_bak.sql
如遇报表不存在,mysqldump可以添加参数:--force ,跳过错误
3.删除数据库
drop database hxdb; 或者将数据库数据库目录 mv hxdb hxdb_bak (保险)
4.去掉参数 innodb_force_recovery
将之前设置的参数去掉后,重新启动数据库
5.导入数据
mysql -uroot -p < mysql_all_bak.sqlWarning: Using a password on the command line interface can be insecure.
ERROR 1050 (42S01) at line 25: Table '`hxdb`.`tb_info`' already exists如果提示表已经存在,这是因为将innodb_force_recovery参数去掉后,数据库会进行回滚操作,会生成相应的ibd文件,所以需要将该文件删除掉,删除后重新导入
mysql -uroot -p < mysql_all_bak.sq
这篇关于MySQL非正常关闭导致无法再次启动的问题以及无法启动如何将数据库表和数据进行转储详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




