本文主要是介绍Notion-数据导入,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
通过数据导入可以将Markdown,txt,docx,xls,csv,html文件导入Notion,也可以从印象笔记导入数据(需要花钱)
将数据导入Notion
像大多数人,你可能将数据,文档和笔记分散到许多文件或者软件中,你可以通过把他们全部放进Notion里面来集中你的信息到一个地方.🚚
怎么导入
- Notion让你直接导入以下文件类型:
.txt,.md,.docx,.xls,.csv,.html - 你也可以从其他的一些apps中导入数据(例如Confluence,Asana,Evernote,和trello等)
- 导入按钮(Import)在左侧侧边栏的底部
- 这将打开导入窗口,你可以选择其中合适的应用来导入(特定应用的导入指令如下)
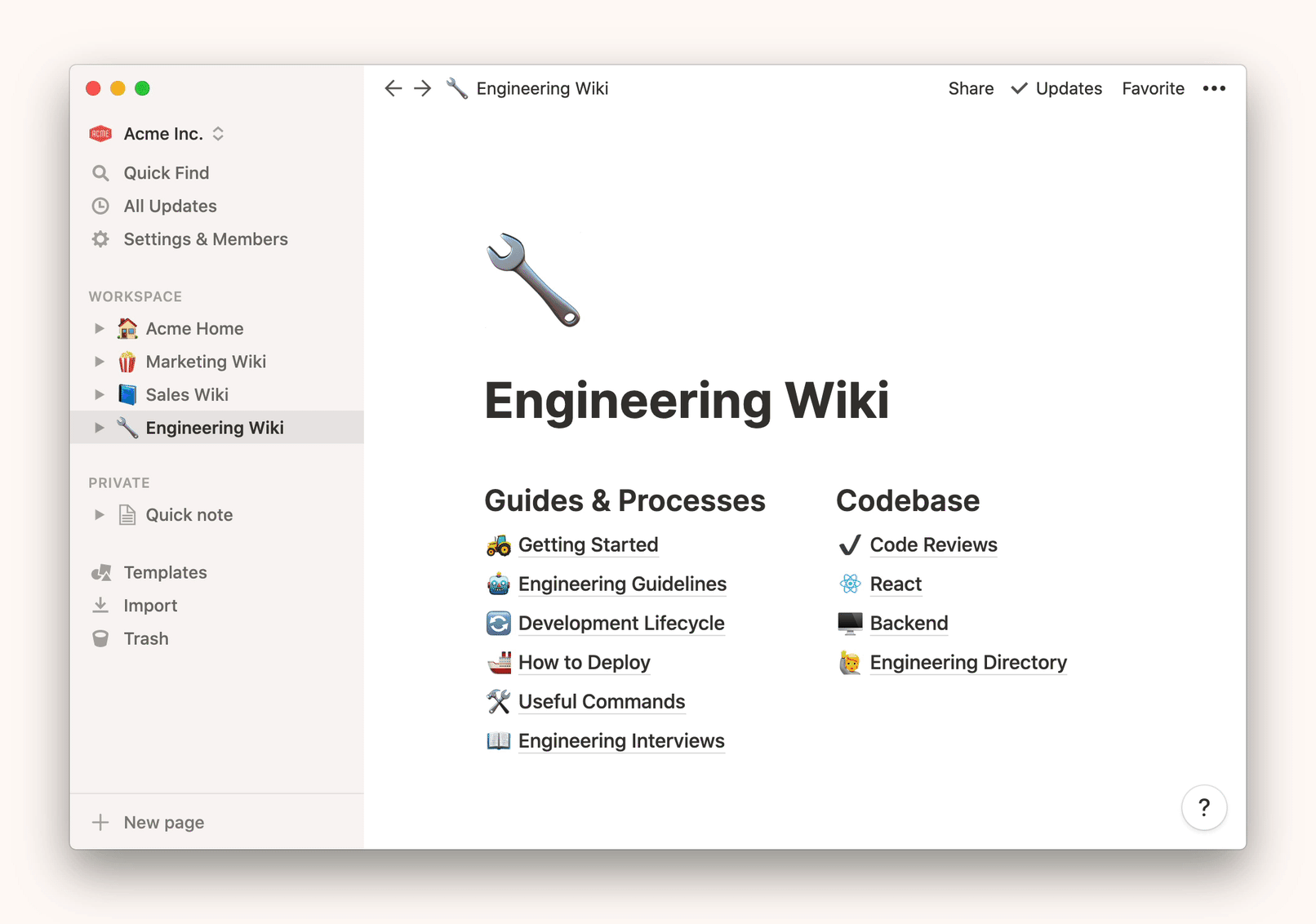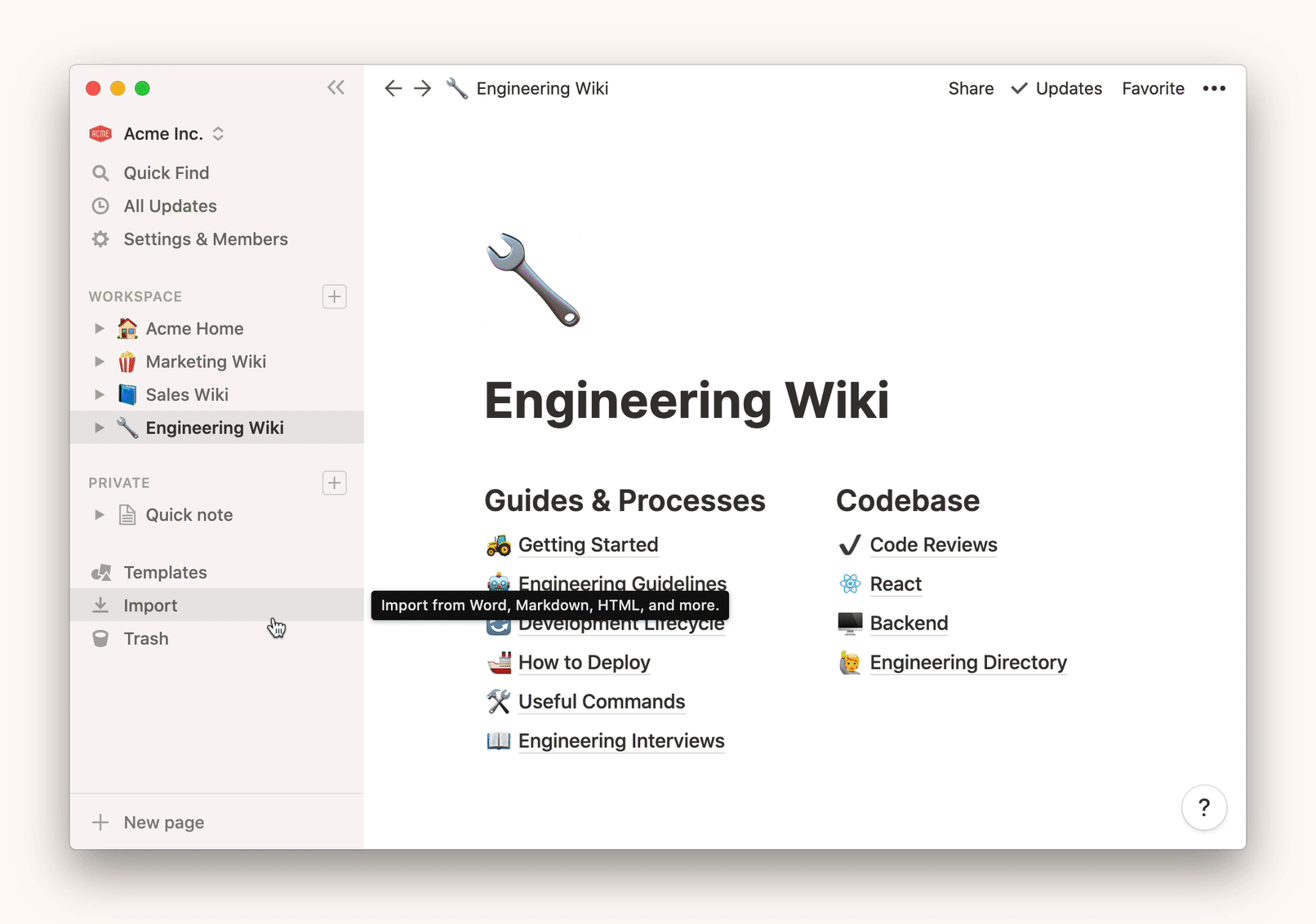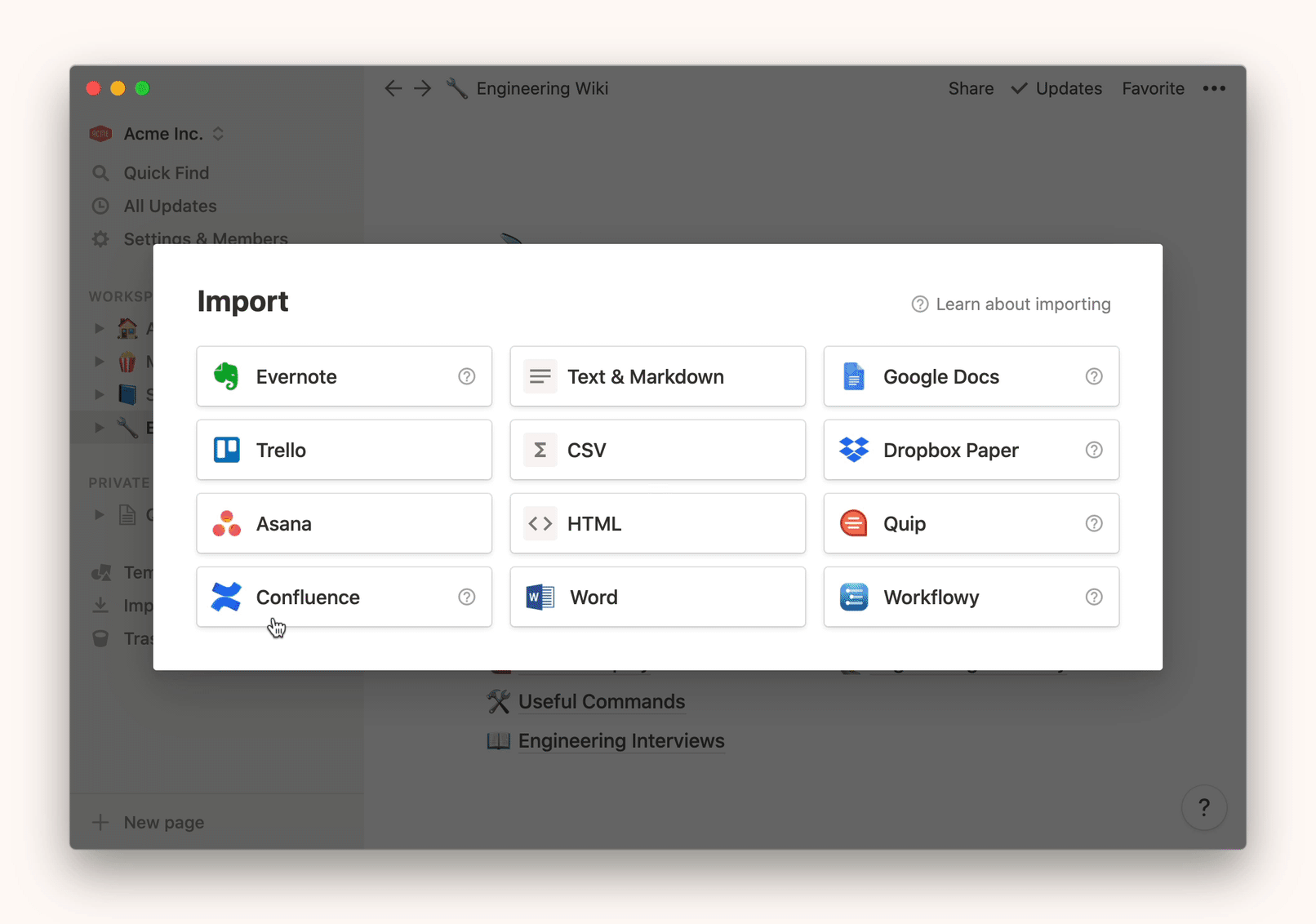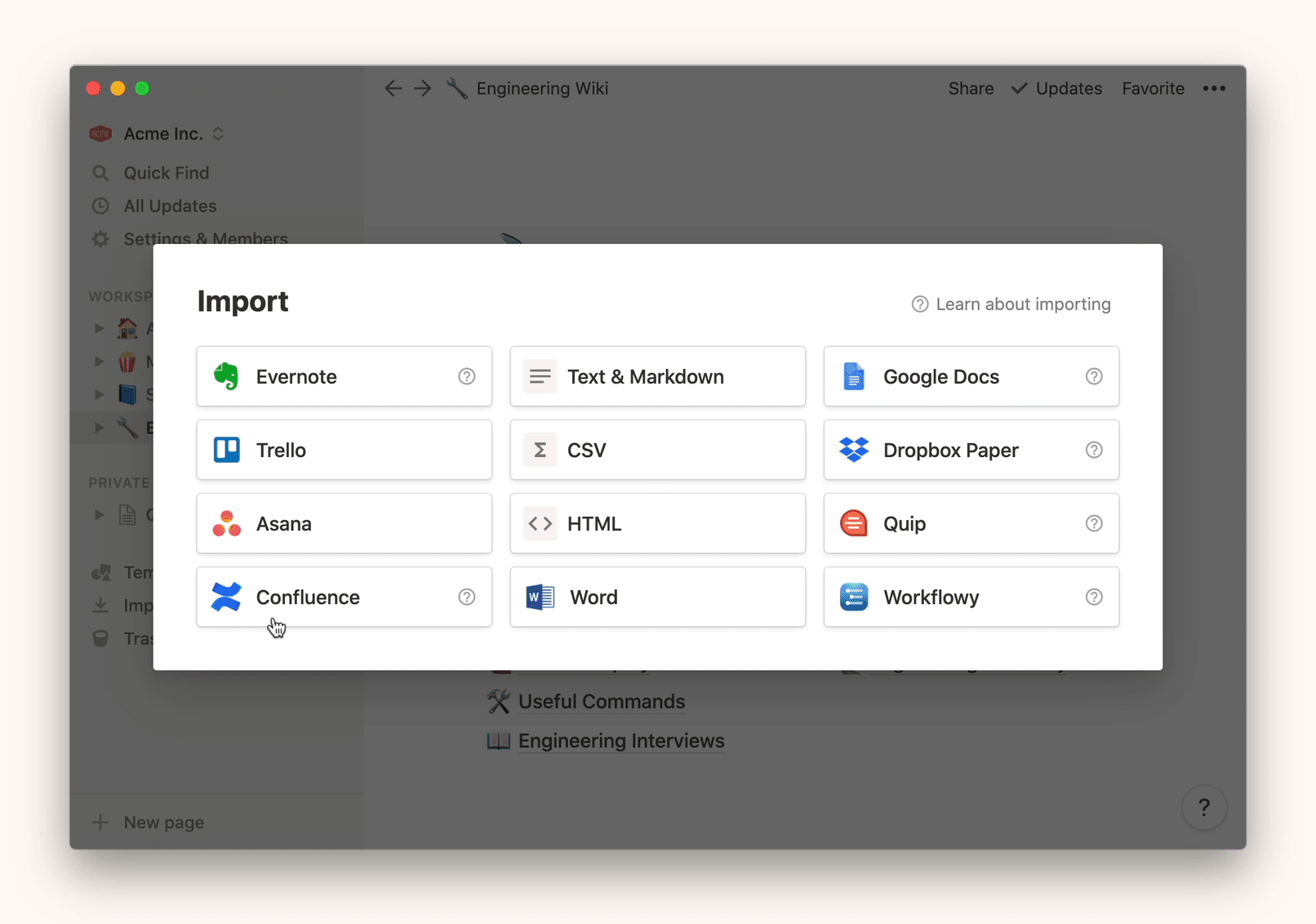
你只能导入桌面或web上的内容,而不能导入移动设备中的内容
指令的应用
例如Evernote🐘
你可以一次将所有的印象笔记的数据导入到Notion中,并且保留他们的结构
- 从导入窗口,选择Evernote
- 登录你的印象笔记账户
- 授权印象笔记连接到Notion
- 一旦连接上印象笔记的账户,选中你想导入笔记本附近的复选框,并且点击导入
- 你的印象笔记会以页面的形式出现在Notion的侧边栏.在里面你会发现你的笔记本是一个列表数据库中的项目
- 每个笔记都可以被拖放到Notion中任何地方
FAQS Links
价格表2020-12-13

这篇关于Notion-数据导入的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







