本文主要是介绍Mnist手写体数字数据集介绍与在Pytorch中使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.介绍
MNIST(Modified National Institute of Standards and Technology)数据集是一个广泛用于机器学习和计算机视觉研究的常用数据集之一。它由手写数字图像组成,包括0到9的数字,每张图像都是28x28像素的灰度图像,图片和标签均采用二进制编码,共70000张图像,其中包括60000张训练集和10000测试集。每张图像都对应一个one-hot标签,表示图像中显示的是哪个数字。
这个数据集因其相对较小的规模和简单的图像内容也成为了许多机器学习入门教程和示例的标准数据集,因为它的简单性和普遍性,使得学习者能够快速开始构建和训练模型,从而更好地理解机器学习的基本概念和流程,可以说它就是计算机视觉的“Hello World”。
官网地址https://yann.lecun.com/exdb/mnist/
2.在Pytorch中使用Mnist
Pytorch的torchvision中的datasets自带下载与读取Mnist数据集的函数,可以很方便的使用
1.导入所需库
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt2.下载Mnist数据集
# 定义数据转换
transform = transforms.Compose([transforms.ToTensor() # 将图像转换为 PyTorch 张量
])# 下载并加载 MNIST 训练和测试数据集
train_dataset = datasets.MNIST(root='./dataset', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./dataset', train=False, download=True, transform=transform)- root为数据集保存的位置
- train为是否为训练集
- download为是否自动下载该数据集,如果数据集已经下载过,即使设置为True也没关系,他会自动检测
- transform为数据转换的操作,ToTensor()是必须的
这里如果不使用科学上网可能无法下载,或者下载有点慢。而直接去官网的话又需要登陆

这里另外一个介绍使用迅雷下载数据集的方法,不止适用于这个数据集,我们复制好链接后打开迅雷就会自动弹出下载界面
| 数据集 | 文件名 | 下载地址 |
|---|---|---|
| 训练集图像 | train-images-idx3-ubyte.gz | http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz |
| 训练集标签 | train-labels-idx1-ubyte.gz | http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz |
| 测试集图像 | t10k-images-idx3-ubyte.gz | http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz |
| 测试集标签 | t10k-labels-idx1-ubyte.gz | http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz |
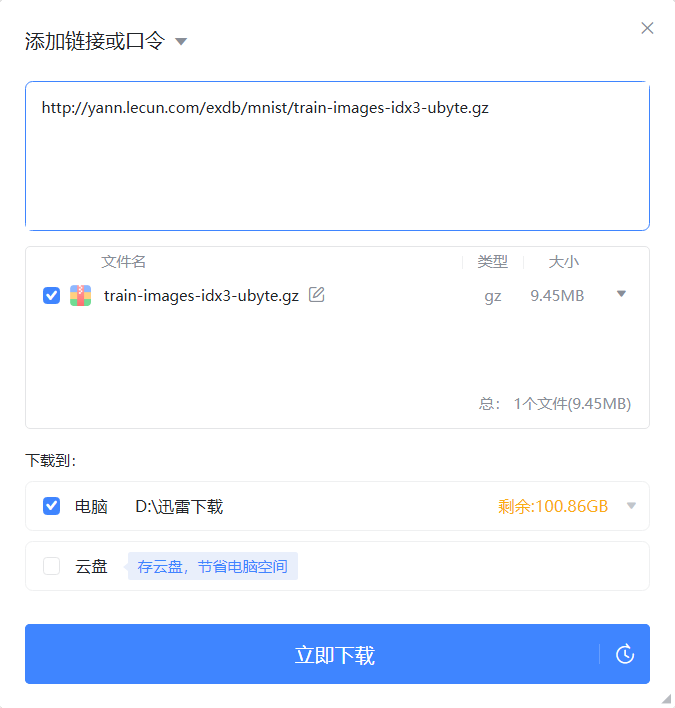
没有弹出的话就把链接复制到搜索框
下载好后,在root参数指定的位置下新建一个MNIST文件夹,再在MNIST中新建一个raw文件夹,对于其他数据集不知道如何建文件夹可以先尝试自动下载,他会建好文件夹,然后把下载好的四个压缩包直接放进去就可以
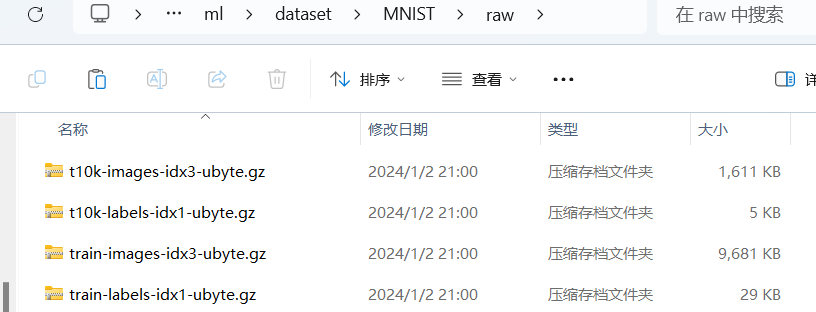
接着我们再运行一次上面的代码,他会检测到数据集已存在,然后自动解压缩,这样就完成了
3.读取数据集与展示
使用dataloader将数据分为一个个批量大小的数据,生成一个迭代器,shuffle为是否洗牌
# 创建数据加载器以批量加载数据
batch_size = 128
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 输出训练集和测试集的长度
train_length = len(train_dataset)
test_length = len(test_dataset)
print(f"训练集的长度:{train_length}")
print(f"测试集的长度:{test_length}")

# 创建一个字典以存储类别索引及其对应的图像
images_by_class = {}# 填充字典,每个类别只保留几张图像
num_images_per_class = 5# 循环遍历训练集中的每个图像和对应的标签
for image, label in train_dataset:# 如果当前标签不在字典中,为该标签创建一个空列表if label not in images_by_class:images_by_class[label] = []# 如果当前类别的图像数量未达到指定的数量(num_images_per_class),则将当前图像添加到对应类别的列表中if len(images_by_class[label]) < num_images_per_class:images_by_class[label].append(image)# 显示每个类别的图像
for label, images in images_by_class.items():print(f"Class {label}:")# 创建一个新的图像窗口,并设置大小plt.figure(figsize=(num_images_per_class * 2, 2))# 遍历每个类别的图像列表并显示for i in range(num_images_per_class):plt.subplot(1, num_images_per_class, i + 1)# 显示图像,并使用灰度颜色图plt.imshow(images[i].squeeze(), cmap='gray')plt.axis('off') # 不显示坐标轴plt.show() # 显示图像

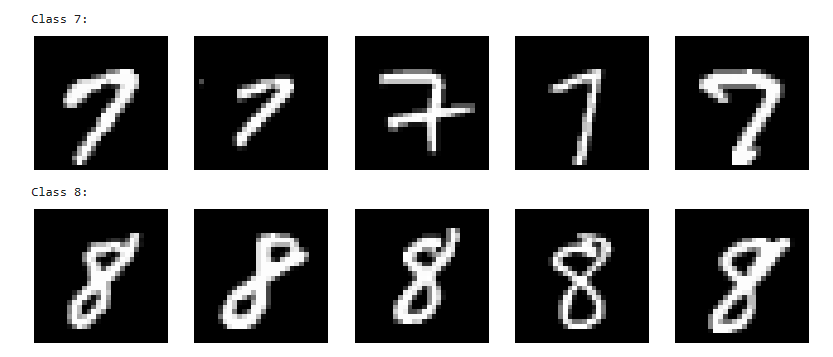
然后使用for循环就可以一次读取一个批量的数据,进行后面的一系列任务,这里只是展示一个批次数据
# 读取一个批次的数据
for i, (images, labels) in enumerate(train_loader):print("第{}批次".format(i+1))print(images.shape) # 图像批次的形状 (batch_size, 通道数, 高度, 宽度)print(labels.shape) # 标签批次的形状 (batch_size,)break 
这篇关于Mnist手写体数字数据集介绍与在Pytorch中使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







