本文主要是介绍霹雳吧啦Wz《pytorch图像分类》-p4GoogLeNet网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
《pytorch图像分类》p4GoogLeNet网络详解
- 一、GoogLeNet网络中的亮点
- 1.inception结构
- 2.使用1×1的卷积核进行降维及映射处理
- 3.GoogLeNet辅助分类器
- 4.模型参数
- 二、模块代码
- 1.BasicConv2d
- 2.Inception
- 三、课程代码
- 1.module.py
- 2.train.py
- 3.predict.py
一、GoogLeNet网络中的亮点
论文链接:Going Deeper with Convolutions
代码链接:霹雳吧啦Wzdeep-learning-for-image-processing
1.inception结构
Inception结构是由Google团队提出的一种卷积神经网络架构。
Inception结构的主要目标是解决卷积神经网络中平衡计算量和表示能力之间的权衡问题。它通过并行执行多个不同尺寸的卷积操作和池化操作,从而充分利用不同大小的感受野(receptive field)来捕捉图像的特征。
ps.英语单词inception n.开端,创始
 )
)
2.使用1×1的卷积核进行降维及映射处理
使用1×1的卷积网络进行降维,可以在神经网络中减少特征图的维度,提高神经网络的效率和性能。

3.GoogLeNet辅助分类器
主要目的是通过这些辅助分类器来引入额外的目标函数来帮助训练深层神经网络。(太抽象了)
简单来说就是,当训练非常深的神经网络时,梯度消失是一个普遍的问题,导致较低层的权重很难更新。为了解决这个问题,GoogLeNet引入了辅助分类器。
我记得Sigmoid函数在饱和时,容易出现梯度消失现象。
可见我的博客:pytorch机器学习各种激活函数总结

4.模型参数
GoogLeNet使用了Inception结构,在减少参数量的同时保持性能。
VGG网络是一个非常深的卷积神经网络,以VGG16为例,由13个卷积层和3个全连接层组成。由于网络深度的增加,它具有非常多的模型参数。
但是VGG网络搭建方便,GoogLeNet辅助分类器修改麻烦,所以现实中使用vgg网络的更多。

二、模块代码
1.BasicConv2d
BasicConv2d类里面自定义包含了一个卷积层+Relu激活函数
class BasicConv2d(nn.Module):def __init__(self, in_channels, out_chennels, **kwargs):super(BasicConv2d, self).__init__()self.conv = nn.Conv2d(in_channels, out_chennels, **kwargs)self.relu = nn.ReLU(inplace=True)def forward(self,x):x = self.conv(x)x = self.relu(x)return x
2.Inception

class Inception(nn.Module):def __init__(self,in_channels,ch1x1,ch3x3red,ch3x3,ch5x5red,ch5x5,pool_proj):

添加padding参数时,要保证输出大小等于输入大小
三、课程代码
1.module.py
import torch.nn as nn
import torch
import torch.nn.functional as Fclass GoogLeNet(nn.Module):def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):super(GoogLeNet, self).__init__()self.aux_logits = aux_logitsself.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)self.conv2 = BasicConv2d(64, 64, kernel_size=1)self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)if self.aux_logits:self.aux1 = InceptionAux(512, num_classes)self.aux2 = InceptionAux(528, num_classes)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.dropout = nn.Dropout(0.4)self.fc = nn.Linear(1024, num_classes)if init_weights:self._initialize_weights()def forward(self, x):# N x 3 x 224 x 224x = self.conv1(x)# N x 64 x 112 x 112x = self.maxpool1(x)# N x 64 x 56 x 56x = self.conv2(x)# N x 64 x 56 x 56x = self.conv3(x)# N x 192 x 56 x 56x = self.maxpool2(x)# N x 192 x 28 x 28x = self.inception3a(x)# N x 256 x 28 x 28x = self.inception3b(x)# N x 480 x 28 x 28x = self.maxpool3(x)# N x 480 x 14 x 14x = self.inception4a(x)# N x 512 x 14 x 14if self.training and self.aux_logits: # eval model lose this layeraux1 = self.aux1(x)x = self.inception4b(x)# N x 512 x 14 x 14x = self.inception4c(x)# N x 512 x 14 x 14x = self.inception4d(x)# N x 528 x 14 x 14if self.training and self.aux_logits: # eval model lose this layeraux2 = self.aux2(x)x = self.inception4e(x)# N x 832 x 14 x 14x = self.maxpool4(x)# N x 832 x 7 x 7x = self.inception5a(x)# N x 832 x 7 x 7x = self.inception5b(x)# N x 1024 x 7 x 7x = self.avgpool(x)# N x 1024 x 1 x 1x = torch.flatten(x, 1)# N x 1024x = self.dropout(x)x = self.fc(x)# N x 1000 (num_classes)if self.training and self.aux_logits: # eval model lose this layerreturn x, aux2, aux1return xdef _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)class Inception(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):super(Inception, self).__init__()self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1),BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小)self.branch3 = nn.Sequential(BasicConv2d(in_channels, ch5x5red, kernel_size=1),# 在官方的实现中,其实是3x3的kernel并不是5x5,这里我也懒得改了,具体可以参考下面的issue# Please see https://github.com/pytorch/vision/issues/906 for details.BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小)self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)class InceptionAux(nn.Module):def __init__(self, in_channels, num_classes):super(InceptionAux, self).__init__()self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]self.fc1 = nn.Linear(2048, 1024)self.fc2 = nn.Linear(1024, num_classes)def forward(self, x):# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14x = self.averagePool(x)# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4x = self.conv(x)# N x 128 x 4 x 4x = torch.flatten(x, 1)x = F.dropout(x, 0.5, training=self.training)# N x 2048x = F.relu(self.fc1(x), inplace=True)x = F.dropout(x, 0.5, training=self.training)# N x 1024x = self.fc2(x)# N x num_classesreturn xclass BasicConv2d(nn.Module):def __init__(self, in_channels, out_channels, **kwargs):super(BasicConv2d, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)self.relu = nn.ReLU(inplace=True)def forward(self, x):x = self.conv(x)x = self.relu(x)return x
2.train.py
import os
import sys
import jsonimport torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdmfrom model import GoogLeNetdef main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("using {} device.".format(device))data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),"val": transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root pathimage_path = os.path.join(data_root, "data_set", "flower_data") # flower data set pathassert os.path.exists(image_path), "{} path does not exist.".format(image_path)train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),transform=data_transform["train"])train_num = len(train_dataset)# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}flower_list = train_dataset.class_to_idxcla_dict = dict((val, key) for key, val in flower_list.items())# write dict into json filejson_str = json.dumps(cla_dict, indent=4)with open('class_indices.json', 'w') as json_file:json_file.write(json_str)batch_size = 2nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workersprint('Using {} dataloader workers every process'.format(nw))train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size, shuffle=True,num_workers=nw)validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),transform=data_transform["val"])val_num = len(validate_dataset)validate_loader = torch.utils.data.DataLoader(validate_dataset,batch_size=batch_size, shuffle=False,num_workers=nw)print("using {} images for training, {} images for validation.".format(train_num,val_num))# test_data_iter = iter(validate_loader)# test_image, test_label = test_data_iter.next()net = GoogLeNet(num_classes=5, aux_logits=True, init_weights=True)# 如果要使用官方的预训练权重,注意是将权重载入官方的模型,不是我们自己实现的模型# 官方的模型中使用了bn层以及改了一些参数,不能混用# import torchvision# net = torchvision.models.googlenet(num_classes=5)# model_dict = net.state_dict()# # 预训练权重下载地址: https://download.pytorch.org/models/googlenet-1378be20.pth# pretrain_model = torch.load("googlenet.pth")# del_list = ["aux1.fc2.weight", "aux1.fc2.bias",# "aux2.fc2.weight", "aux2.fc2.bias",# "fc.weight", "fc.bias"]# pretrain_dict = {k: v for k, v in pretrain_model.items() if k not in del_list}# model_dict.update(pretrain_dict)# net.load_state_dict(model_dict)net.to(device)loss_function = nn.CrossEntropyLoss()optimizer = optim.Adam(net.parameters(), lr=0.0003)epochs = 30best_acc = 0.0save_path = './googleNet.pth'train_steps = len(train_loader)for epoch in range(epochs):# trainnet.train()running_loss = 0.0train_bar = tqdm(train_loader, file=sys.stdout)for step, data in enumerate(train_bar):images, labels = dataoptimizer.zero_grad()logits, aux_logits2, aux_logits1 = net(images.to(device))loss0 = loss_function(logits, labels.to(device))loss1 = loss_function(aux_logits1, labels.to(device))loss2 = loss_function(aux_logits2, labels.to(device))loss = loss0 + loss1 * 0.3 + loss2 * 0.3loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,loss)# validatenet.eval()acc = 0.0 # accumulate accurate number / epochwith torch.no_grad():val_bar = tqdm(validate_loader, file=sys.stdout)for val_data in val_bar:val_images, val_labels = val_dataoutputs = net(val_images.to(device)) # eval model only have last output layerpredict_y = torch.max(outputs, dim=1)[1]acc += torch.eq(predict_y, val_labels.to(device)).sum().item()val_accurate = acc / val_numprint('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %(epoch + 1, running_loss / train_steps, val_accurate))if val_accurate > best_acc:best_acc = val_accuratetorch.save(net.state_dict(), save_path)print('Finished Training')if __name__ == '__main__':main()
我的电脑带不动,batch_size=32我改成了batch_size=2,也就运行了一个多小时吧(麻了)

3.predict.py
import os
import jsonimport torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as pltfrom model import GoogLeNetdef main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")data_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# load imageimg_path = "2.jpg"assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)img = Image.open(img_path)plt.imshow(img)# [N, C, H, W]img = data_transform(img)# expand batch dimensionimg = torch.unsqueeze(img, dim=0)# read class_indictjson_path = './class_indices.json'assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)with open(json_path, "r") as f:class_indict = json.load(f)# create modelmodel = GoogLeNet(num_classes=5, aux_logits=False).to(device)# load model weightsweights_path = "./googleNet.pth"assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)missing_keys, unexpected_keys = model.load_state_dict(torch.load(weights_path, map_location=device),strict=False)model.eval()with torch.no_grad():# predict classoutput = torch.squeeze(model(img.to(device))).cpu()predict = torch.softmax(output, dim=0)predict_cla = torch.argmax(predict).numpy()print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],predict[predict_cla].numpy())plt.title(print_res)for i in range(len(predict)):print("class: {:10} prob: {:.3}".format(class_indict[str(i)],predict[i].numpy()))plt.show()if __name__ == '__main__':main()
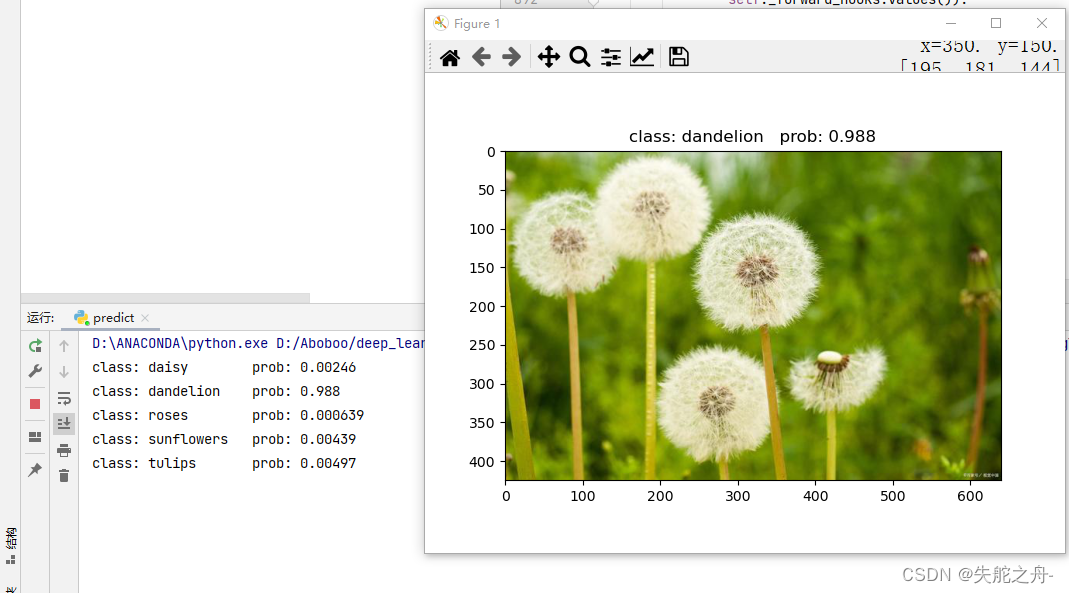
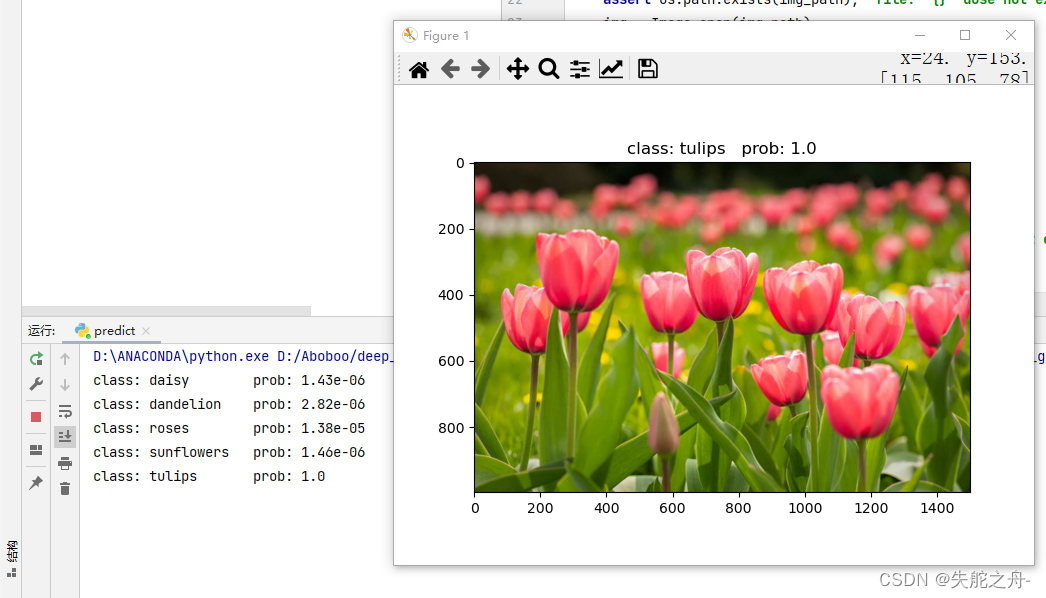
我去,预测这么准的吗?
1.jpg 蒲公英
2.jpg 郁金香
这篇关于霹雳吧啦Wz《pytorch图像分类》-p4GoogLeNet网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







