本文主要是介绍SELinux 安全模型——MLS,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首发公号:Rand_cs
BLP 模型:于1973年被提出,是一种模拟军事安全策略的计算机访问控制模型,它是最早也是最常用的一种多级访问控制模型,主要用于保证系统信息的机密性,是第一个严格形式化的安全模型
暂时无法在飞书文档外展示此内容
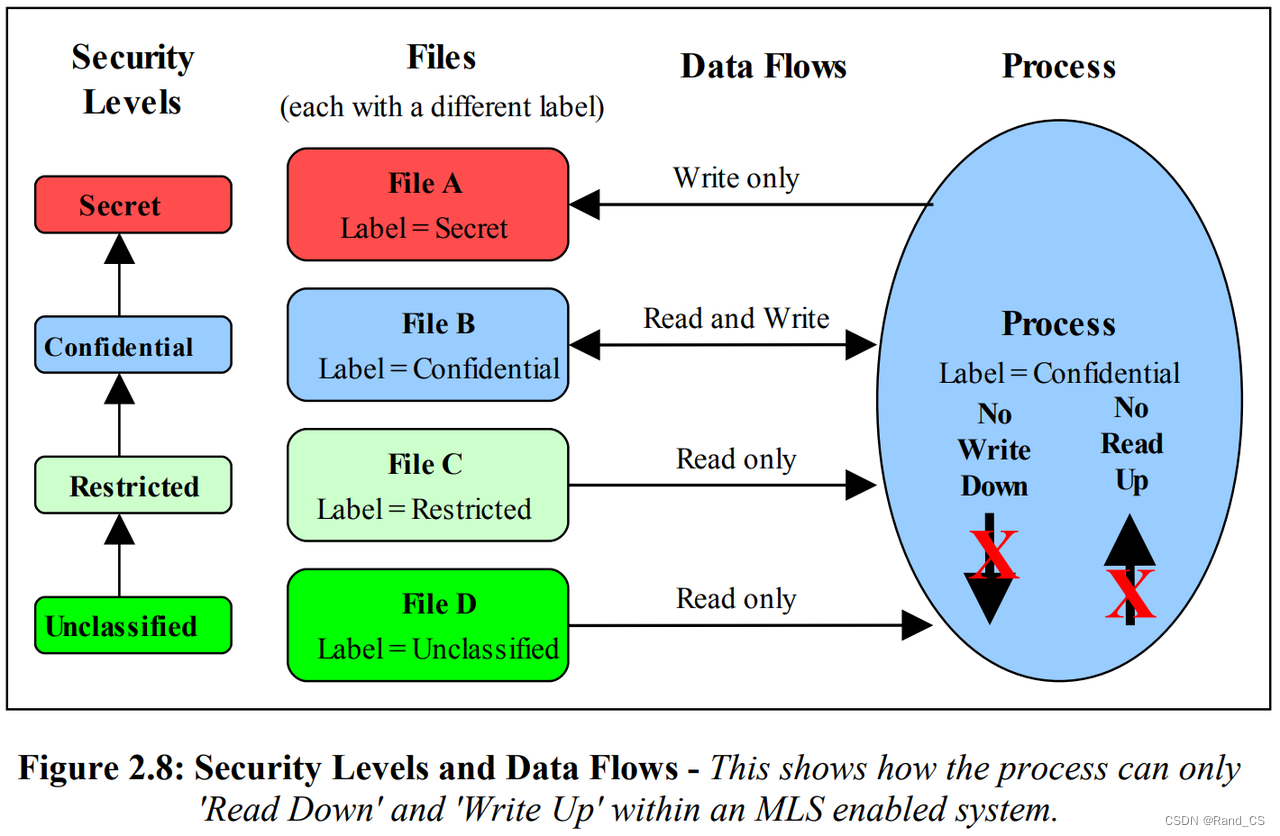
多层安全的核心:“数据流向只能是由低到高(或者平级流动)”,所以只能向上写数据,从下层读数据,或者同级之间读写数据。
此图有四个安全级别,由低到高分别为:unclassified → restricted → confidential → secret
进程和4个文件的安全级别如上图所示:
- 进程只能写文件A,不能读。因为文件A的安全级别程度高于进程,所以进程不能读。但是数据流向可以由低到高,所以进程可以向文件A进行写操作
- 进程和文件B是同级,所以数据流向可以双向流通,即进程可以读写文件B
- 文件C的安全级别低于进程,所以数据流向只能是文件到进程,即进程只能读取文件数据,不能写。假如进程可以写文件C,那么confidential的数据流向了restrict类型的文件,则该confidential数据可能被其他的restrict级别的进程读取,造成机密信息泄露,所以高级别进程只能对低级别文件进行读操作。
Context
MLS 模式在 SELinux 中是可选的,在编译时期开启,SELinux 的编译工具有 checkpolicy 或者 checkmodule,当使用这两个命令时加上选项 -M 便可以开启多层安全模式。这时你的策略应该也要支持 MLS,也就是定义某个文件的安全上下文的时候应该带上它的 mls/mcs
开启多层安全后安全上下文扩展最后一个字段 “安全级别(Security Level or Level)”,安全上下文完整形式如下所示:
安全级别分为两个部分,敏感度和类别,敏感度可以对文件分级,类别对文件分类,具体如下所示:

sensitivity
敏感度,必须要有
定义方式:
sensitivity s0;
sensitivity s1;
sensitivity s2;
sensitivity s3 alias secret; //给s3定义个别名secret
优先级高低定义:
dominance { s0 s1 s2 s3 } #优先级从低到高,即s0最低,s3最高
category
类别,可选
定义方式:
category c0 alias blue;
category c1 alias red;
category c2 alias green;
category c3 alias orange;
category c4 alias white;
level
安全级别:一个敏感度和零个或多个类别的组合,即 sensitivity[:category...] 这个整体就是安全级别
有两个安全级别:低安全级别-高安全级别,高安全级别可选。
定义方式:
level s0:c0.c2; #此安全级别的敏感度为s0,类别为c0 c1 c2,即 . 表示范围
level s1:c0.c2,c4; #此安全级别的敏感度为s1,类别为c0 c1 c2 c4,没有c3,即,表示分开的两段类别
安全级别之间的关系
- l1 dominates l2
- l 1. s e n s i t i v i t y ≥ l 2. s e n s i t i v i t y l1.sensitivity \ge l2.sensitivity l1.sensitivity≥l2.sensitivity l1的敏感度高于或等于l2
- l 2. c a t e g o r y ⊆ l 1. c a t e g o r y l2.category \subseteq l1.category l2.category⊆l1.category l1的类别是l2超集或等于l2
- l1 is dominated by l2:
- l 1. s e n s i t i v i t y ≤ l 2. s e n s i t i v i t y l1.sensitivity \le l2.sensitivity l1.sensitivity≤l2.sensitivity
- l 1. c a t e g o r y ⊆ l 2. c a t e g o r y l1.category \subseteq l2.category l1.category⊆l2.category
- l1 equals l2:
- l 1. s e n s i t i v i t y = l 2. s e n s i t i v i t y l1.sensitivity = l2.sensitivity l1.sensitivity=l2.sensitivity
- l 1. c a t e g o r y = l 2. c a t e g o r y l1.category = l2.category l1.category=l2.category
- l1 is incomparable to l2
!(l1 dom l2) && !(l2 dom l1)
具体代码:
struct mls_level {u32 sens; /* sensitivity */ //敏感度,一个整数struct ebitmap cat; /* category set */ //类别,一个位图
};
//range:低安全级别-高安全级别
struct mls_range {struct mls_level level[2]; /* low == level[0], high == level[1] */
};static inline int mls_level_eq(struct mls_level *l1, struct mls_level *l2)
{return ((l1->sens == l2->sens) && //敏感度相同ebitmap_cmp(&l1->cat, &l2->cat)); //类别集合也相同
}static inline int mls_level_dom(struct mls_level *l1, struct mls_level *l2)
{return ((l1->sens >= l2->sens) && //敏感度大于等于ebitmap_contains(&l1->cat, &l2->cat)); //类别集合要包含
}//两个安全级别不相关
#define mls_level_incomp(l1, l2) \
(!mls_level_dom((l1), (l2)) && !mls_level_dom((l2), (l1)))//l2安全级别在 l1 l3 之间
#define mls_level_between(l1, l2, l3) \
(mls_level_dom((l1), (l2)) && mls_level_dom((l3), (l1)))//l1-h1 包含 l2-h2
#define mls_range_contains(r1, r2) \
(mls_level_dom(&(r2).level[0], &(r1).level[0]) && \mls_level_dom(&(r1).level[1], &(r2).level[1]))
通过 mlsconstrain 实现 BLP 模型:
mlsconstrain 又是另外一个策略语法,直接来看例子:
mlsconstrain class_set perm_set expression ;
#expression部分为u r t l h的布尔表达式
#u1, r1, t1, l1, h1 – source user, role and type, low security level, high security level;
#u2, r2, t2, l2, h2 – target user, role and type, low security level, high security level;
举例说明:mlscontrain file read (l1 dom l2); 此语句说明当源进程想要读取目标文件时,需要源进程的安全级别 l1 高于或等于目标文件的安全级别 l2
实现 no read up,即只能读取同级别或者低级别的数据
mlsconstrain { dir file lnk_file chr_file blk_file sock_file fifo_file } { read getattr execute } ((l1 eq l2) or ( l1 dom l2 ) or (t1 == mlsfileread));
- l1 eq l2 表示 源和目标的安全级别相同,所以对于 dir file 等类型文件的 read getattr execute 操作可以执行
- l1 dom l2,表示源的安全级别高于目标的安全级别,高级别可以读取低级别,所以此情况下 dir file 等类型文件的 read getattr execute 操作也允许执行
- 再或者我们可以特殊定义一个类型,只要源类型是 mlsfileread,那么就可以执行读取操作
实现 no write down,即只能写同级别或者高级别的数据:
mlsconstrain { file lnk_file fifo_file dir chr_file blk_file sock_file } { write create setattr relabelfrom append unlink link rename mounton } (( l1 eq l2 ) or (l1 domby l2) or (t1 == mlsfilewrite));
含义基本同上,只不过是反着来。上述就是 SELinux 中实现 BLP 的两个例子,想要完整的实现,还有其他的策略,有兴趣的可以去看 refpolicy 的源码
好了,本文先到这里,有什么问题欢迎来讨论交流
首发公号:Rand_cs
这篇关于SELinux 安全模型——MLS的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









