本文主要是介绍一步步编写操作系统 12 代码段、数据段、栈和cpu寄存器的关系,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
先说下什么是寄存器。
寄存器是一种物理存储元件,只不过它是比一般的存储介质要快,能够跟上cpu的步伐,所以在cpu内部有好多这样的寄存器用来给cpu存取数据。
先简短说这一两句,暂时离开一下主题,咱们先看看相对熟悉一些的概念——缓存。
缓存也是一项非常伟大的发明,成功解决了速度不匹配设备之间的数据传输,并且在一般情况下,IO是整个系统的瓶颈,缓存的出现,有效减少了低速IO设备的访问频率,从而大幅度的提升了速度。
大家对缓存一定不会陌生,生活中处处都是缓存的应用。比如浏览器在请求一个域名的ip时:
- 1浏览器内部都有dns客户端,它先查询本地dns缓存中是否有该域名的ip,如果有就直接去访问该ip。如果没有,该dns客户端先要查找自己主机所设置的dns服务器,然后去该dns服务器去查询ip。
- 如果该dns服务器本地缓存中有该域名的A记录(域名与ip地址的对应记录),则直接返回给浏览器中的dns客户端。没有该域名的A记录,就通过递归的方式向上询问其它dns服务器,也许问到了根dns服务器才找到了答案。于是这路上所有被询问过的dns服务器,都将此域名对应的A记录缓存到自己的cache中,以备下次再有相同域名查询时好直接返回。
- 浏览器中的dns客户端得到此域名的ip地址后,也将该域名和ip放在自己的缓存中,以备下次用户再键入同一域名时,避免再查一次ip。
- 浏览器开始通过网络用http协议访问该ip地址的80端口(默认是80端口,除非特别指定)。
- 一般情况下该ip对应的设备不是最终的web服务器,很少有人把web服务器直接暴露在公网。假设该ip对应的设备是台网关(一般是硬件路由设备),该网关检查本地缓存中是否有相关web服务器的缓存,若有则直接将该http请求分配给缓存中的web服务器。否则从服务器列表中重新分配一台web服务器,将该http请求转发给该web服务器处理。随后将该web服务器的ip地址(一般是内网地址)和端口号缓存起来,以备下次该用户的请求到来时,依然给该web服务器。有的网关可以识别用户cookie信息,从而将可以请求再次落到上一个请求的web服务器上。
- web服务器拿到请求后,如果是静态请求,先检查自己的缓存中是否有该页面的记录,否则直接从硬盘上取出页面,将其返回后,再存入本地静态缓存中。如果动态请求,先交给自己的cgi去处理。
- cgi拿到请求后,先检查自己的缓存系统如memcache,如果缓存中没有,与数据库建立连接,向数据库发出请求。
- 数据库也是先检查自己的缓存,若没有结果集,则从表中检索到数据后返回,并将结果集缓存起来。
- cgi拿到数据后,返回给web服务器。并将数据缓存到memcache中。
- web服务器拿到了数据后,将数据返回给网关。由于是动态数据,不需要缓存。
- 网关拿到数据后,直接返回给浏览器。
- 如果浏览器发现其中有静态数据,如图片,也将静态数据缓存到用户的internet 临时目录。
您看,就这么一个不起眼的网页请求,就经过了12步,几乎每一步都要缓存结果,当然每一层的缓存都有一定的失效时间,超过多少秒后就将缓存中的记录置为无效。这其中还有另外一个术语,如果缓存中恰好有需要的内容,这就称为命中hit,否则称为缺失mis。
其实上面的缓存,我还没说全呢,硬件之间还有缓存呢,比如硬盘控制器和硬盘……得,您还是打住吧,我是来学操作系统的,您跟我说这干吗,还说了12个步骤,这与我何干?
兄弟稍安误燥,待小弟细细道来。前面所说的各种缓存,是为了引出cpu中的缓存。cpu中的一级缓存L1,二级缓存L2,它们都是SRAM,即静态随机访问存储器,它是最快的存储器啦。也许您又说:“是啊,这个我知道,那又怎么样?”
好啦不卖关子啦,也许您只听说L1、L2、SRAM,但您可能不知道的是,SRAM是用寄存器来存储数据的,这就是SRAM快的原因。而寄存器为什么快呢?原因是,寄存器是使用触发器实现的,这也是一种存储电路,工作速度极快,是纳秒级别的,您想寄存器能不快吗,这和cpu的速度是一个级别啦。硬件我也不是很了解,所以只能跟您说到这了,点到为止,对于硬件背后的原理,咱们蜻蜓点水即可。
巧妇难为无米之炊,不管是指令还是数据,cpu内部总该有个地方存放它们,否则cpu这位巧妇连锅都没有,还怎么给大家烧一桌好菜呢。所以,寄存器是给cpu处理数据的场所。
到这里,大家心里应该对寄存器有个感性认识了,这样学起来,似乎看得见摸得着了。
cpu中的寄存器大致上分为两大类:
- λ一类是其内部使用的,对程序员不可见。“是否可见”不是说寄存器是否能看得见,是指程序员是否能使用。cpu内部有其自己的运行机制,是按照某个预定框架进行的,为了cpu能够运行下去,必然会有一些寄存器来做数据的支撑,给cpu内部的数据提供存储空间。这一部分对外是不可见的,我们无法使用它们。比如全局描述符表寄存器GDTR,中断描述符表寄存器IDTR,局部描述符表寄存器LDTR,任务寄存器TR,控制寄存器CR0~3,指令指针寄存器IP,标志寄存器flags,调试寄存器DR0~7。
- λ另一类是对程序员可见的寄存器。我们进行汇编语言程序设计时,能够直接操作的就是这些寄存器。如段寄存器,通用寄存器。
虽说第一类的程序是不可见寄存器,我们没办法直接使用,但它们中的一部分还得由咱们给初始化呢。比如全局描述符表寄存器GDTR,以后咱们还要通过lgdt指令为其指定全局描述符表的地址及偏移量。对于中断描述符表寄存器IDTR,咱们也是要通过lidt指令为其指定中断描述符表的地址。而局部描述符表寄存器LDTR,可以用lldt指令为其指定局部描述符表ldt(但我们效仿了现代操作系统,未用局部描述符表ldt)。对于任务寄存器TR,我们也要用ltr指令为其在指定一个任务状态段tss。对于flags寄存器,我们也有办法设置它,系统提供了pushf和popf指令,分别用于将flags寄存器的内容压入栈,将栈中内容弹到flags寄存器。额外说一句,ldt和tss都位于gdt中。这些方面的内容咱们在学习保护模式后都会讲到。
在实模式下,默认用到的寄存器都是16位宽,咱们说说具体的寄存器吧。段寄存器是做啥的呢。说到段寄存器存在的理由,得先说到内存访问机制。cpu是用“段基址:段内偏移地址”的形式来访问内存的,如果您对此访存形式不了解,前面第0章中有解释过分段,而且在下一节中也是讲内存分段的理由。您合理安排阅读。
现在假设您已经了解分段机制啦,上面提到的“段基址:段内偏移地址”中的段基址,就是用段寄存器来存储的,段寄存器的作用就是指定一片内存的起始地址,故也称为段基址寄存器。尽管段基址在实模式下要乘以16,在保护模式下只是个选择子(保护模式中会讲),但其作用就是指定一片内存的起始地址。而段内偏移地址,顾名思义,仅仅相对于此起始地址的偏移量。
访问内存,是要通过地址总线,给地址总线一个数字(也就是地址),地址总线就能找到以该数字为地址的内存。可是这个数字是哪来的呢?对于首次访问内存之前,其内存地址肯定是要放在与内存不同的存储介质中更合适也更容易。如果用内存来存储内存地址,首先访问该内存就是个问题,该内存的地址是什么?这就跟先有鸡还是先有蛋的本源问题一样了。您可能会有疑问,地址也只是个数字,把数字存放在内存中有什么不行的。我这里所说的并不是内存寻址,您说的这个数字只是该内存单元中的内容,这是内存寻址,前提是您已经给地址总线提交了保存该数字的内存地址。我说的是,提交给地址总线的地址,是从哪里获得的。不知道我说清楚了没有,再举个例子,我想用木材做一个船模,我不可能还用木质工具去加工它,只能用铁器等比木更硬的材料通过削、磨等方式将它加工出来。换在计算机中也一样,访问内存就要提供地址,初次访问内存时,该地址要么用立即数,要么存储在某个存储器中能让cpu取出来再访问内存,肯定不能用内存本身来存。由于寄存器比内存更高级,cpu更能接受,所以就用寄存器来存储内存地址。由于要指定的是内存中的一段区域的起始地址,所以称之为段基址寄存器,也称段寄存器,无论是在实模式下还是保护模式下,它们都是16位宽。
下面就是实模式下的段寄存器
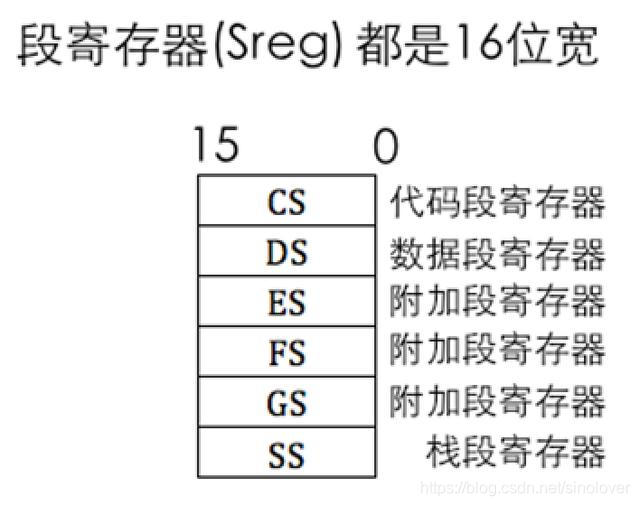
代码段简而言之就是把所有指令都连续排放在一起,形成了一个全部都是指令的区域,里面存储的是指令的操作码及寻址方式等。该区域可以在硬盘上的文件中,也可以是被加载后的内存中。总之是一段指令区域,它们内部都是紧凑挨着的,内容形式完全一样,只是存放的介质不一样而已。代码段寄存器CS就是用来指向内存中这段指令区域的起始地址。具体程序分段的解释,可见第0章。
数据段和代码段类似,只是这段区域中的内容不是指令而是纯粹的数据,也就是说里面存储的是程序运行所需要的数据,属于指令的操作数。数据段寄存器DS便是用来指向此数据区域的起始地址。
栈段是在内存中,硬盘文件中可真没有。一般的栈段是由操作系统分配指定的,所以是属于被加载到内存后才有的。本章后面还会讲栈,这里大家就先当它是一段内存区域就好。栈段寄存器SS就是用来指向此区域的起始地址。
代码段、数据段、栈段寄存器从名字上就较容易理解,那三个附加段寄存器是干吗的?其实就是多给大家提供几个段寄存器用而已,多几个寄存器用不是更好吗,省得紧巴巴的,纯粹是为了方便大家。
值得说明的是,在16位cpu中,只有一个附加段寄存器——ES。而FS和GS附加段寄存器是在32位cpu中增加的。我们使用的是32位cpu,并不是说32位cpu在实模式下的16位环境中就不能用FS和GS寄存器。32位的cpu是兼容16位cpu的特性,就像一个小学生也可以穿中学生的衣服一样,无非是多用了个可用的资源。
IP寄存器是不可见寄存器,CS寄存器是可见寄存器。这两个配合在一起后就是cpu的罗盘,它们是给cpu导航用的。cpu执行到何处,完成要听这两个寄存器的安排。为什么要用两个寄存器?因为指令是在内存中,访问内存就要用“段:段内偏移”的形式,所以CS寄存器用来存代码段段基址,IP寄存器用来存储代码段段内偏移地址,同CS寄存器一样都是16位宽。
其实这两个寄存器没什么神奇的,并不是它们真的决定了cpu的航向,只是cpu的航向被存入了这两个寄存器之中。之前说过啦,指令在逻辑上是紧凑的,这样cpu便能连续不断的执行下去,天荒地老,直到断电。cpu执行完一条指令后,顺便就把下一条指令的内存地址读进来。注意看,读入的是下一条指令的内存地址,这有两个关键字,一个是内存,一个是地址。刚刚说过啦,是内存就应该用“段基址:段内偏移地址”的机制来访问。是地址就该有地方存放。您想,即使是洗菜,菜也得先找个盘子或盆之类的器具盛着再拿到水笼头下冲洗。在x86体系架构中,本着先满足“段基址:段内偏移”的形式,这个地址就分开存到了代码段CS寄存器和指令指针IP寄存器。在执行当前指令的同时,在不跨段的情况下,cpu以“当前IP寄存器中的值+当前执行指令的机器码长度”的和做为新的代码段内偏移地址,将其存入IP寄存器,再到该新地址处读取指令并执行。如果下一条指令需要跨段访问,还要加载新的段基址到CS寄存器。此后,继续重复以上“取址、执行”的循环。
好啦,客官以后常来玩儿哦。
本节内容摘自操作系统真象还原,请大家支持正版。
这篇关于一步步编写操作系统 12 代码段、数据段、栈和cpu寄存器的关系的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







