本文主要是介绍java零拷贝zero copy MappedByteBuffer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
调用操作系统的 mmap
未使用 mmap 的文件通过网络传输的过程
使用 mmap 的文件通过网络传输的过程
使用例子
调用操作系统的 sendfile()
在 java 中的具体实现
mmap的优劣
mmap 的不足
mmap 的优点
mmap 的使用场景
对于零拷贝(zero copy),目前操作系统支持多种方式,具体如下
调用操作系统的 mmap
在之前的页缓存文章的基础上
https://blog.csdn.net/zlpzlpzyd/article/details/135317588
如果在 linux 上如果直接对 page cache 怎么办?
鉴于 java 语言是建立在 jvm 基础上调用操作系统的 api 来对机器资源进行访问的,可以通过 mmap 来实现,从 java 1.4 开始提供了 FileChannel 的 map() 来实现这个功能,这样就可以类似指针的方式来直接操作文件了。这样带来的好处是,不用进行用户态和内核态的切换了,减少了机器的资源开销。
未使用 mmap 的文件通过网络传输的过程

可见发生了4次用户态与内核态的上下文切换(调用 read()后返回数据与调用write()后返回数据),4次数据拷贝(两次DMA拷贝,两次CPU拷贝)。
传统的IO性能是非常差的,所以,要想提高文件传输的性能,就需要减少用户态与内核态的上下文切换和内存拷贝的次数。
使用 mmap 的文件通过网络传输的过程
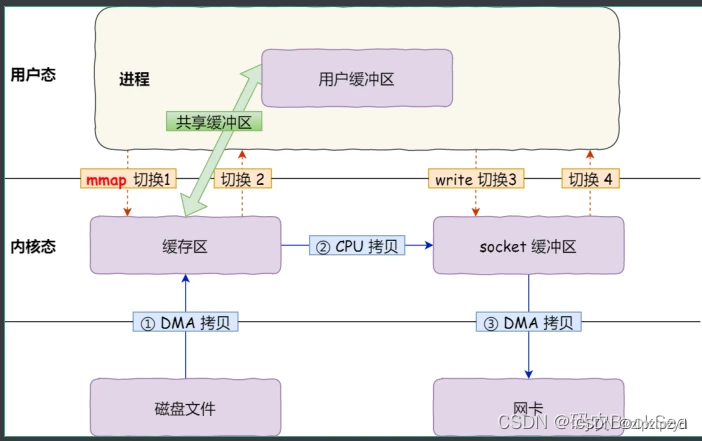
需要 4 次上下文切换,因为系统调用还是 2 次。但是拷贝从4次变成了3次。
使用例子
java 中通过 MappedByteBuffer 来实现直接对 page cache 的操作。
import java.io.IOException;
import java.io.Serializable;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;public class TestMapMemeryBuffer2 implements Serializable {private final static String CONTENT = "Zero copy implemented by MappedByteBuffer";private final static String FILE_NAME = "mmap.txt";public static void main(String[] args) throws IOException {xieshuju();dushuju();}public static void xieshuju() throws IOException {/**写文件数据* 打开文件通道 fileChannel 并提供读权限、写权限和数据清空权限,通过 fileChannel 映射到一个可写的内存缓冲区 mappedByteBuffer,* 将目标数据写入 mappedByteBuffer,通过 force() 方法把缓冲区更改的内容强制写入本地文件。*/Path path = Paths.get("E:/data",FILE_NAME);if (Files.notExists(path)) {Files.createDirectories(path.getParent());Files.createFile(path);}byte[] bytes = CONTENT.getBytes(StandardCharsets.UTF_8);try (FileChannel fileChannel = FileChannel.open(path, StandardOpenOption.READ,StandardOpenOption.WRITE, StandardOpenOption.TRUNCATE_EXISTING)) {MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, bytes.length);if (mappedByteBuffer != null) {mappedByteBuffer.put(bytes);mappedByteBuffer.force();}} catch (Throwable e) {e.printStackTrace();}}public static void dushuju() throws IOException {/*** 读文件数据:打开文件通道 fileChannel 并提供只读权限,通过 fileChannel 映射到一个只可读的内存缓冲区 mappedByteBuffer,* 读取 mappedByteBuffer 中的字节数组即可得到文件数据。* */Path path = Paths.get("E:/data",FILE_NAME);if (Files.notExists(path)) {Files.createDirectories(path.getParent());Files.createFile(path);}int length = CONTENT.getBytes(StandardCharsets.UTF_8).length;try (FileChannel fileChannel = FileChannel.open(path, StandardOpenOption.READ)) {MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_ONLY, 0, length);if (mappedByteBuffer != null) {byte[] bytes = new byte[length];mappedByteBuffer.get(bytes);String content = new String(bytes, StandardCharsets.UTF_8);System.out.println(content);}} catch (Throwable e) {e.printStackTrace();}}
}
调用操作系统的 sendfile()
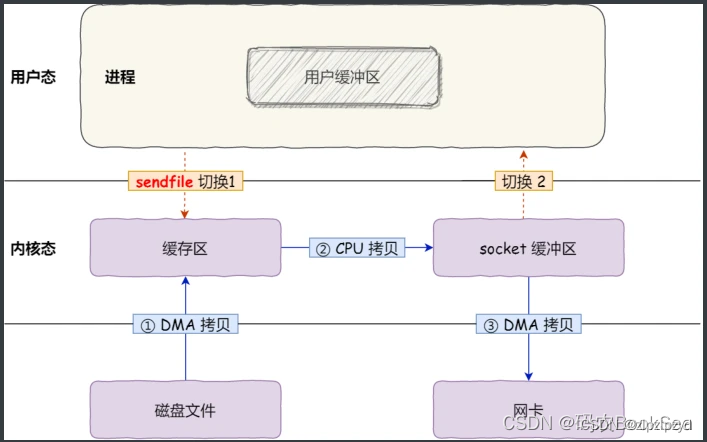
在 Linux 内核版本 2.1 中,提供了1个专门发送文件的系统调用函数 sendfile()。
它可以替代前面的 read() 和 write() 这两个系统调用,这样就可以减少1次系统调⽤,文件传输变为在操作系统执行,不需要应用程序的参与,也就减少了 2 次上下文切换的开销。
这样就只有 2 次上下文切换,和 3 次数据拷贝。
在 java 中的具体实现
FileChannel 的 transferFrom() 和 transferTo()。
两者使用调用方式不同,transferFrom() 是目标 FileChannel 调用,transferTo() 是源 FileChannel 调用。
https://blog.csdn.net/weixin_44371237/article/details/122322890
以上的还不是真正的零拷贝技术,如果网卡支持 SG-DMA(The Scatter-Gather DirectMemory Access)技术(和普通的 DMA 有所不同),可以减少通过 CPU 把内核缓冲区的数据拷贝到 socket 缓冲区的过程。
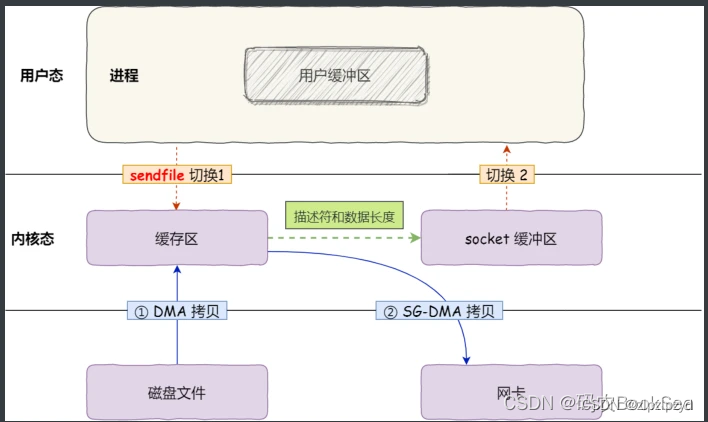
Linux运行这条命令查看网卡是否支持 SG-DMA
$ ethtool -k eth0 | grep scatter-gather
scatter-gather: on这样,最终只有2次上下文切换和2 次数据拷贝。
mmap的优劣
mmap 的不足
鉴于操作系统的 page cache 为 4KB,所以在使用过程中最好是 4KB 的整数倍,不然会造成内存空间浪费。
map方法中 size 的类型是 long,但是在注释中指定不能大于 Integer#MAX_VALUE,也就是2147483647字节,换算一下大概是2G。也就是说 MappedByteBuffer 的最大值是2G,一次最多只能 map 2G 的数据。

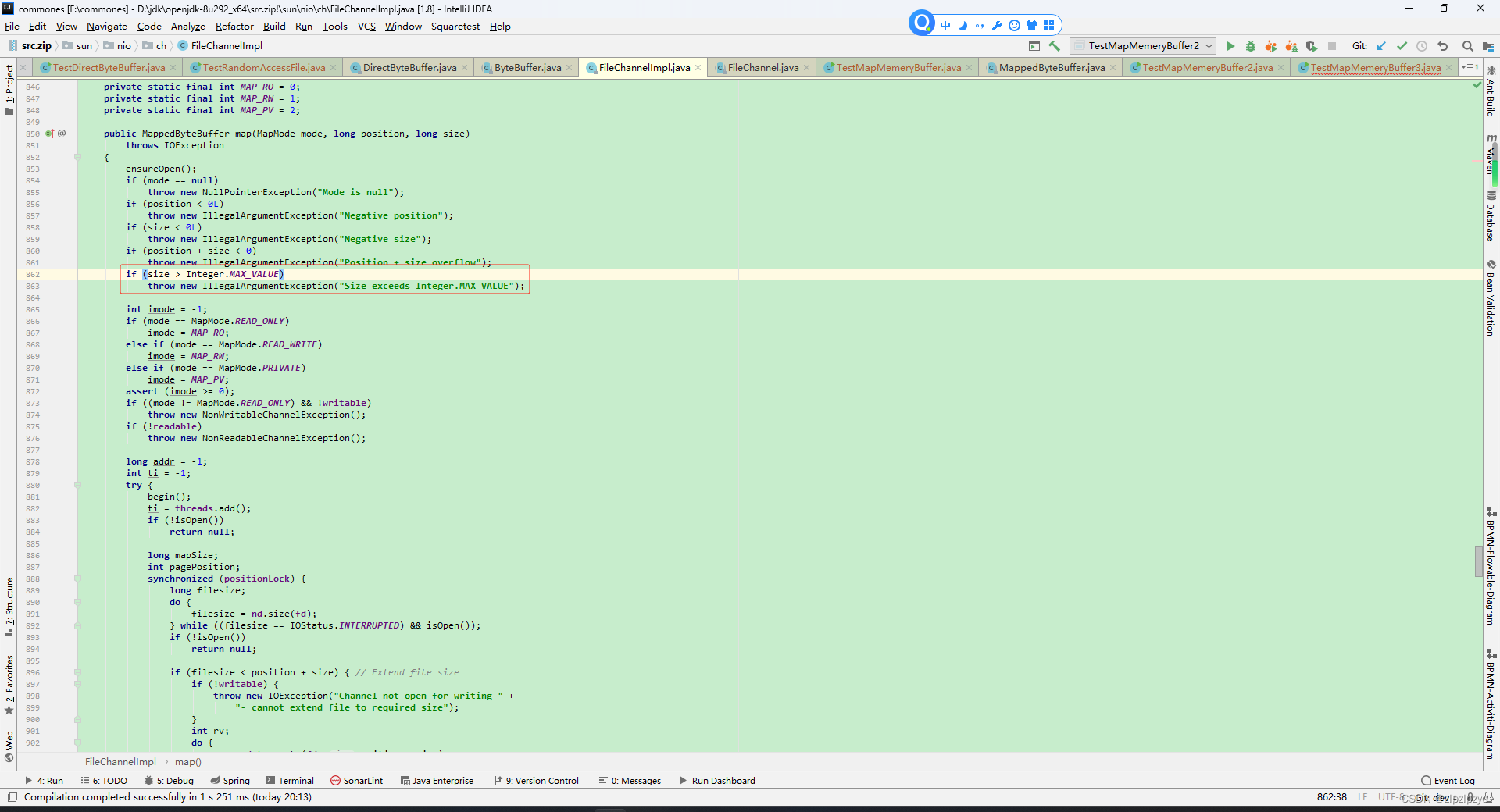
由于 MappedByteBuffer 最终的实现类为 DirectByteBuffer,即使用了堆外内存,这就使得在使用的时候对内存回收时变得困难。
如果针对大文件使用 MappedByteBuffer,会造成内存不足的情况,其他一些经常使用的文件会造成经常被回收的情况(因为 page cache 的在操作系统实现了 lru 算法来处理)。
mmap内存映射的大小始终是整数页,因此对于文件实际大小和映射的空间之间多少会有差异,这个差异的空间是被浪费的,对于小文件来说这个浪费比例被放大,因此 mmap 更适合频繁操作的大文件。频繁映射大量不同大小的内存,会导致内存碎片化。
针对大文件的传输,不应该使用 Page Cache,也就是说不应该使用零拷贝技术,因为可能由于 Page Cache 被大文件占据,由于大文件难以命中 Page Cache 缓存,导致热点小文件无法命中 Page Cache,这样在高并发的环境下,会带来严重的性能问题。
传输大文件的时候,使用异步 IO + 直接 IO,因为可以绕过 Page Cache
传输小文件的时候,使用零拷贝技术
针对所谓的文件大小的定义,需要通过压力测试来验证一下,这个需要后面看一下。
MappedByteBuffer 是没有close方法的,即使它的 FileChannel 被close了,MappedByteBuffer 仍然处于打开状态,只有JVM进行垃圾回收的时候才会被关闭。而这个时间是不确定的。
对于具体的写入磁盘时间是由操作系统来决定的,如果想要马上写入磁盘需要手动调用 force()。
mmap 的优点
mmap基于操作系统的 mmap 的内存映射技术,通过 MMU 映射文件,将文件直接映射到用户态的内存地址,使得对文件的操作不再是 write/read,而转化为直接对内存地址的操作,使随机读写文件和读写内存相似的速度。
把文件映射到用户空间里的虚拟内存,省去了从内核缓冲区复制到用户空间的过程,文件中的位置在虚拟内存中有了对应的地址,可以像操作内存一样操作这个文件,这样的文件读写文件方式少了数据从内核缓存到用户空间的拷贝,效率很高。
将用户态和内核态的重操作减少了。
mmap 的使用场景
频繁操作的文件,因为是基于 page cache 实现的,主要将磁盘的文件暂时缓存到内存中。如果只是用一次或者次数很少,放在内存里没有必要。
参考链接
https://blog.csdn.net/alex_xfboy/article/details/90174840
https://blog.csdn.net/bookssea/article/details/122099186
https://blog.csdn.net/qq_45038038/article/details/134975039
https://blog.csdn.net/qq_39668099/article/details/130240286
https://juejin.cn/post/6921977140946845704
https://blog.csdn.net/m0_50662680/article/details/128420713
https://www.cnblogs.com/flydean/p/io-nio-mappedbytebuffer.html
https://blog.csdn.net/yzh_1346983557/article/details/119760911
https://www.cnblogs.com/sky-heaven/p/16280797.html
https://mp.weixin.qq.com/s/oPv1-wrhYjiOC1o0M0tjMA
https://www.cnblogs.com/jmcui/p/15256464.html
https://www.cnblogs.com/liujinhui/p/15847633.html
https://zhuanlan.zhihu.com/p/377237946
https://blog.csdn.net/andybegin/article/details/129304899
https://blog.csdn.net/dyuan134/article/details/130126955
https://zhuanlan.zhihu.com/p/54762255
https://tech.meituan.com/2017/05/19/about-desk-io.html
https://www.jianshu.com/p/59dad2d290a1
https://www.jianshu.com/p/c83fa8bd564f
https://blog.csdn.net/NF_ALONG/article/details/129399559
https://zhuanlan.zhihu.com/p/439380628
https://blog.csdn.net/xystrive/article/details/125692926
https://zhuanlan.zhihu.com/p/607416958
https://zhuanlan.zhihu.com/p/665075935
这篇关于java零拷贝zero copy MappedByteBuffer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






