本文主要是介绍python库:scapy使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、安装:sudo pip install scapy
2、查看scapy依赖关系:
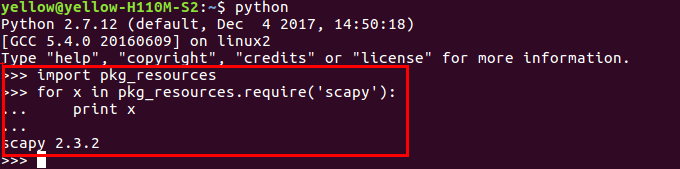
2.3.2版本,不依赖任何python库。
3、使用help('scapy')查看帮助
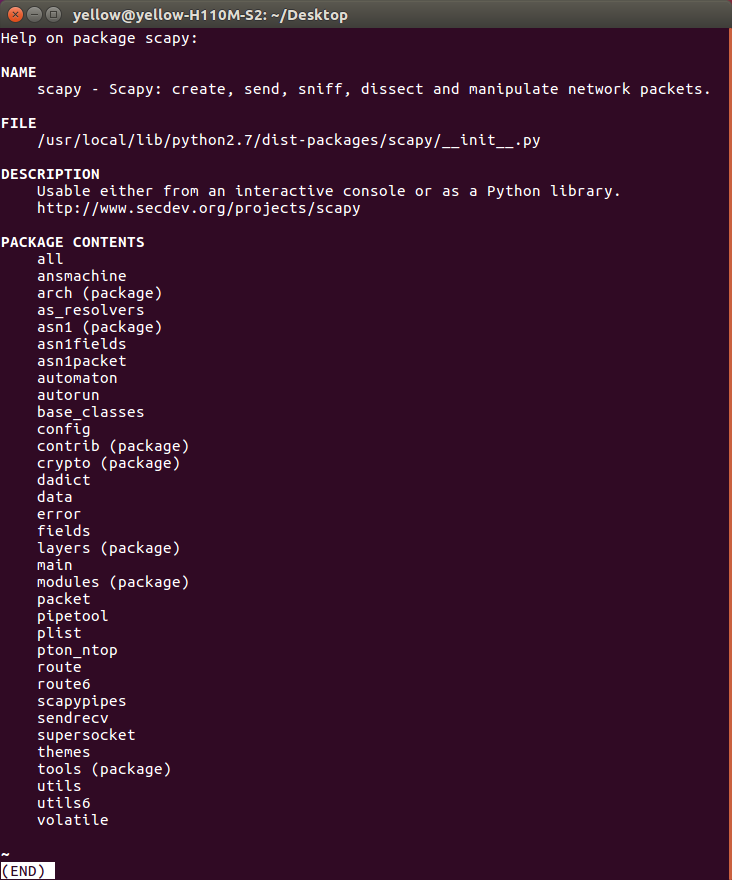
就这么点,任何发送、接受数据包函数都没有看到,和以前的任何显示模块帮助都不一样
正确显示帮助如下:进入python环境
导入scapy : ( from scapy.all import * 正确 下面的3种导入方法一概错误(为什么?不知道)
import scapy 错误
from scapy import all 错误
from scapy import * 错误 )
ls():显示支持所有协议
lsc():显示支持所有命令(就是发送、接受数据包函数)
使用help(协议、命令),注意协议、命令不加单引号或者双引号,显示更详细帮助
用起来
先发tcp的数据包,代码如下:
# -- coding: utf-8 --
from scapy.all import *#数据包应用层数据部分
data='wangpeng'
#发送端IP地址10.0.3.83不是本机ip地址 目的端IP地址不详 传输层的TCP并未指明数据包类型:syn fin ack 窗口大小 数据包如果分片,要指明序号
pkt=IP(src='10.0.3.83',dst='10.0.3.88')/TCP(sport=12345,dport=5555)/data
#间隔一秒发送一次 总共发送5次 发送网卡口:enp1s0
send(pkt,inter=1,count=5,iface="enp1s0") wireshark截取数据包如下:
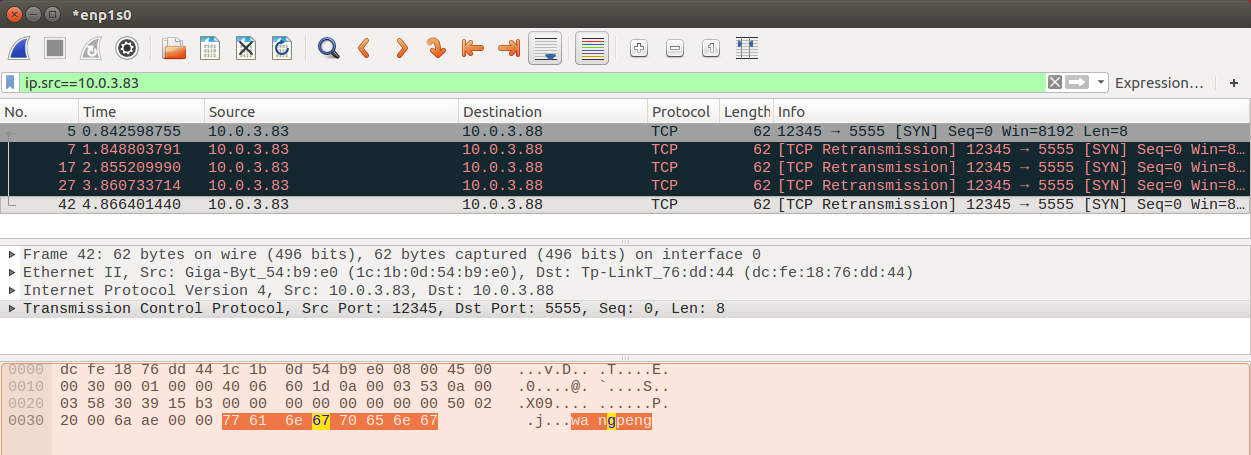
网卡口是enp1s0 正确
源IP地址、目的IP地址也都正确
总共发送了5次也正确,5次数据包发送时间是:0.84 1.84 2.85 3.86 4.86,间隔在一秒左右,也正确
其他类型的数据包以后有机会慢慢写
这篇关于python库:scapy使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





