本文主要是介绍JVM内存的划分及职能(各种变量所存储得位置),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大佬的文章就是不一样图文并茂。
首先根据这篇文章入手了解。
这一次,彻底解决Java的值传递和引用传递
JVM内存的划分及职能
Java语言本身是不能操作内存的,它的一切都是交给JVM来管理和控制的,因此Java内存区域的划分也就是JVM的区域划分,在说JVM的内存划分之前,我们先来看一下Java程序的执行过程,如下图:
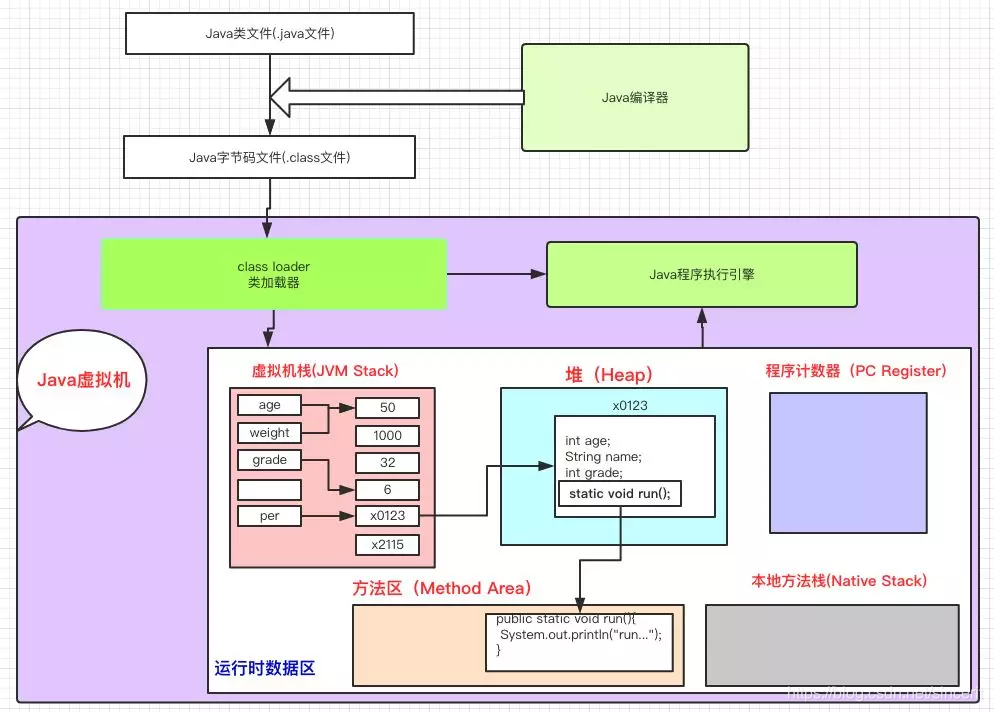
有图可以看出:Java代码被编译器编译成字节码之后,JVM开辟一片内存空间(也叫运行时数据区),通过类加载器加到到运行时数据区来存储程序执行期间需要用到的数据和相关信息,在这个数据区中,它由以下几部分组成:
虚拟机栈,堆 ,程序计数器,方法区,本地方法栈
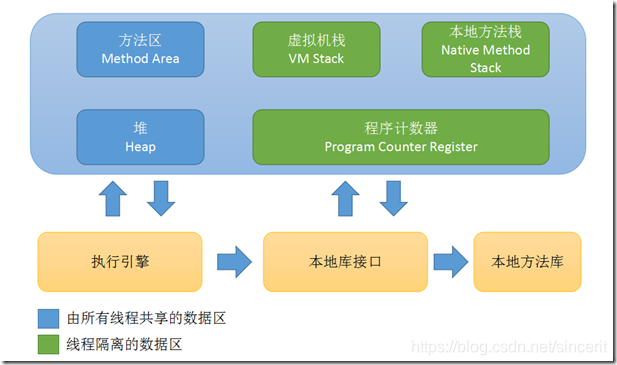
我们接着来了解一下每部分的原理以及具体用来存储程序执行过程中的哪些数据。
- 虚拟机栈(栈区)
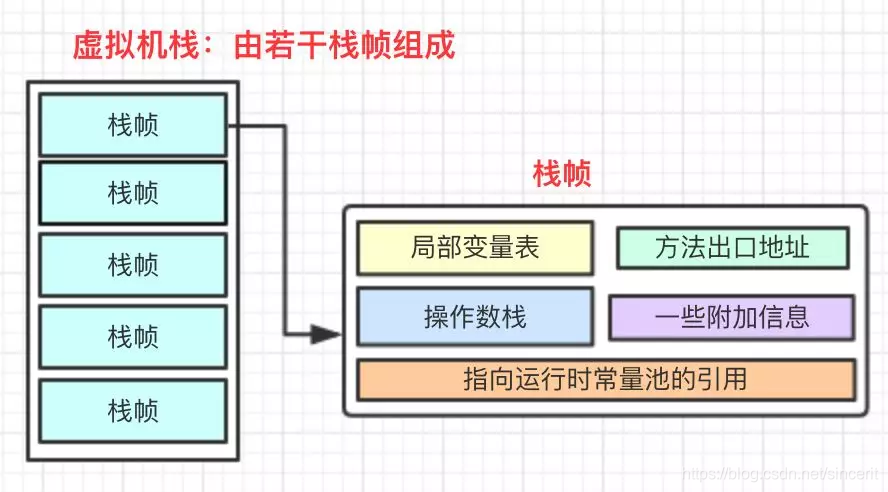
栈是线程私有的,也就是线程之间的栈是隔离的(每一个线程都有一个虚拟机站);当程序中某个线程开始执行一个方法时就会相应的创建一个栈帧并且入栈(位于栈顶),在方法结束后,栈帧出栈。每个方法在执行的同时都会创建一个栈帧(Stack Frame),每个栈帧分别对应一个被调用的方法,方法的调用过程对应栈帧在虚拟机中入栈到出栈的过程。
1.每个线程包含一个栈区,栈中只保存基础数据类型的对象和自定义对象的引用(不是对象),对象都存放在堆区中
2.每个栈中的数据(原始类型和对象引用)都是私有的,其他栈不能访问。
3.栈分为3个部分:基本类型变量区、执行环境上下文、操作指令区(存放操作指令)。
每个栈帧中包括:
1.局部变量表:用来存储方法中的局部变量(非静态变量、函数形参)。当变量为基本数据类型时,直接存储值,当变量为引用类型时(对象),存储的是指向具体对象的引用(对象得地址而非正真的数据)。
2.操作数栈:Java虚拟机的解释执行引擎被称为"基于栈的执行引擎",其中所指的栈就是指操作数栈。
3.指向运行时常量池的引用:存储程序执行时可能用到常量的引用。
4.方法返回地址:存储方法执行完成后的返回地址。
int age=50;
int weight=50;
int grade=6;
当我们写“int age=50;”,其实是分为两步的:
int age;//定义变量
age=50;//赋值
在一个虚拟机栈的栈侦里:
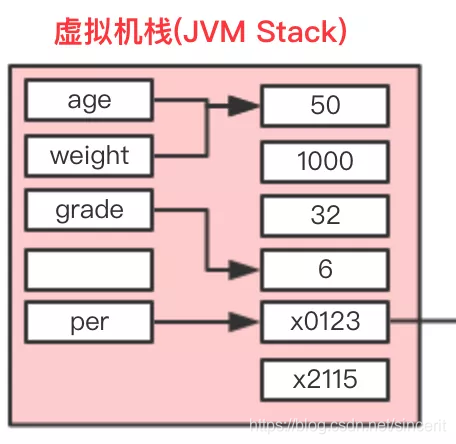
首先JVM创建一个名为age的变量,存于局部变量表中,然后去栈中查找是否存在有字面量值为50的内容,如果有就直接把age指向这个地址,如果没有,JVM会在栈中开辟一块空间来存储“50”这个内容,并且把age指向这个地址。因此我们可以知道:
我们声明并初始化基本数据类型的局部变量时,变量名以及字面量值都是存储在栈中,而且是真实的内容。
我们再来看“int weight=50;”,按照刚才的思路:字面量为50的内容在栈中已经存在,因此weight是直接指向这个地址的。由此可见**:栈中的数据在当前线程下是共享的。**
基本数据类型的数据本身是不会改变的,当局部变量重新赋值时,并不是在内存中改变字面量内容,而是重新在栈中寻找已存在的相同的数据,若栈中不存在,则重新开辟内存存新数据,并且把要重新赋值的局部变量的引用指向新数据所在地址。
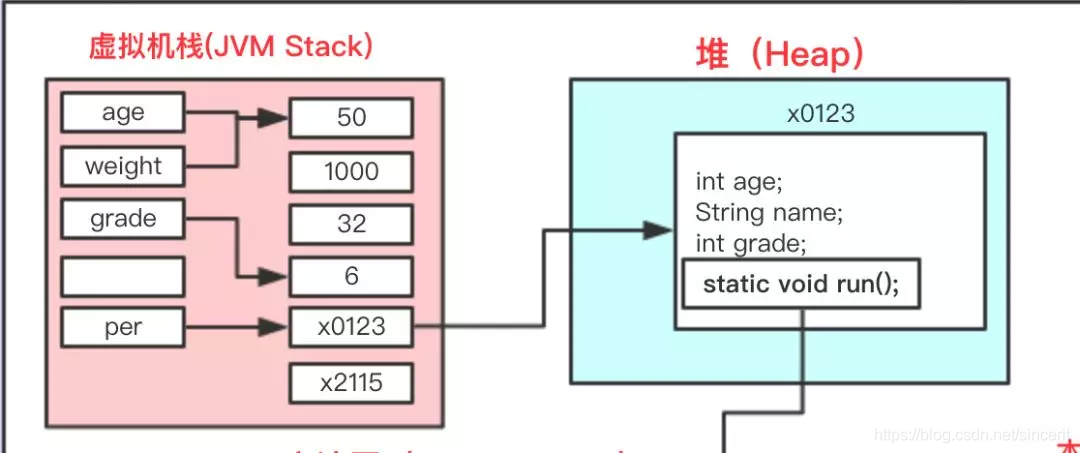
我们看per的地址指向的是堆内存中的一块区域,我们来还原一下代码:
public class Person{
private int age;private String name;private int grade;
//篇幅较长,省略setter getter方法static void run(){System.out.println("run...."); };
}
//调用
Person per=new Person();
同样是局部变量的age、name、grade却被存储到了堆中为per对象开辟的一块空间中。因此可知:基本数据类型的成员变量名和值都存储于堆中,其生命周期和对象的是一致的。
2.方法区(又叫静态区)
1.又叫静态区,跟堆一样,被所有的线程共享。方法区包含所有的class和static变量。
2.方法区中包含的都是在整个程序中永远唯一的元素,如class,static变量。
存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据
3.堆区
1.存储的全部是对象,每个对象都包含一个与之对应的class的信息。(class的目的是得到操作指令)
2.jvm只有一个堆区(heap)被所有线程共享,堆中不存放基本类型和对象引用(对象地址),只存放对象本身
引用一下博客
https://www.cnblogs.com/fengbs/p/7029013.html
https://mp.weixin.qq.com/s?__biz=MzU2MzY3ODI4OA==&mid=2247483796&idx=1&sn=c1885dc01707fc1f73dbcf08e8fb27f4&chksm=fc57dcabcb2055bd0c342eb1bbc265ae0e2cbf89cb9e1df85bf2afe0a643b8d46505e2fc8ac3&mpshare=1&scene=1&srcid=1031epRmyxssOs0gQOfQMTig#rd
这篇关于JVM内存的划分及职能(各种变量所存储得位置)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




