本文主要是介绍Langchain-Chatchat开源库使用的随笔记(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
笔者最近在研究Langchain-Chatchat,所以本篇作为随笔记进行记录。
最近核心探索的是知识库的使用,其中关于文档如何进行分块的详细,可以参考笔者的另几篇文章:
- 大模型RAG 场景、数据、应用难点与解决(四)
- RAG 分块Chunk技术优劣、技巧、方法汇总(五)
原项目地址:
- Langchain-Chatchat
- WIKI教程(有点简单)
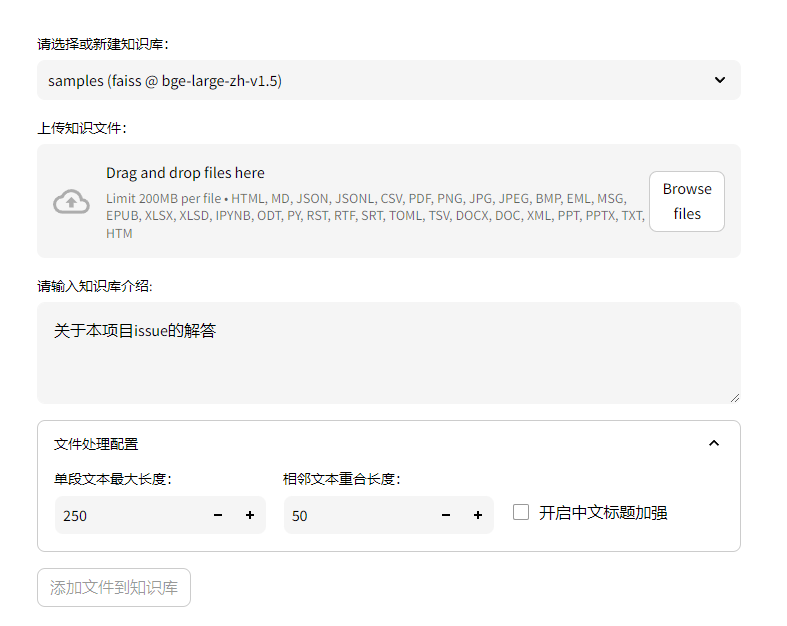
1 Chatchat项目结构
整个结构是server 启动API,然后项目内自行调用API。
API详情可见:http://xxx:7861/docs ,整个代码架构还是蛮适合深入学习
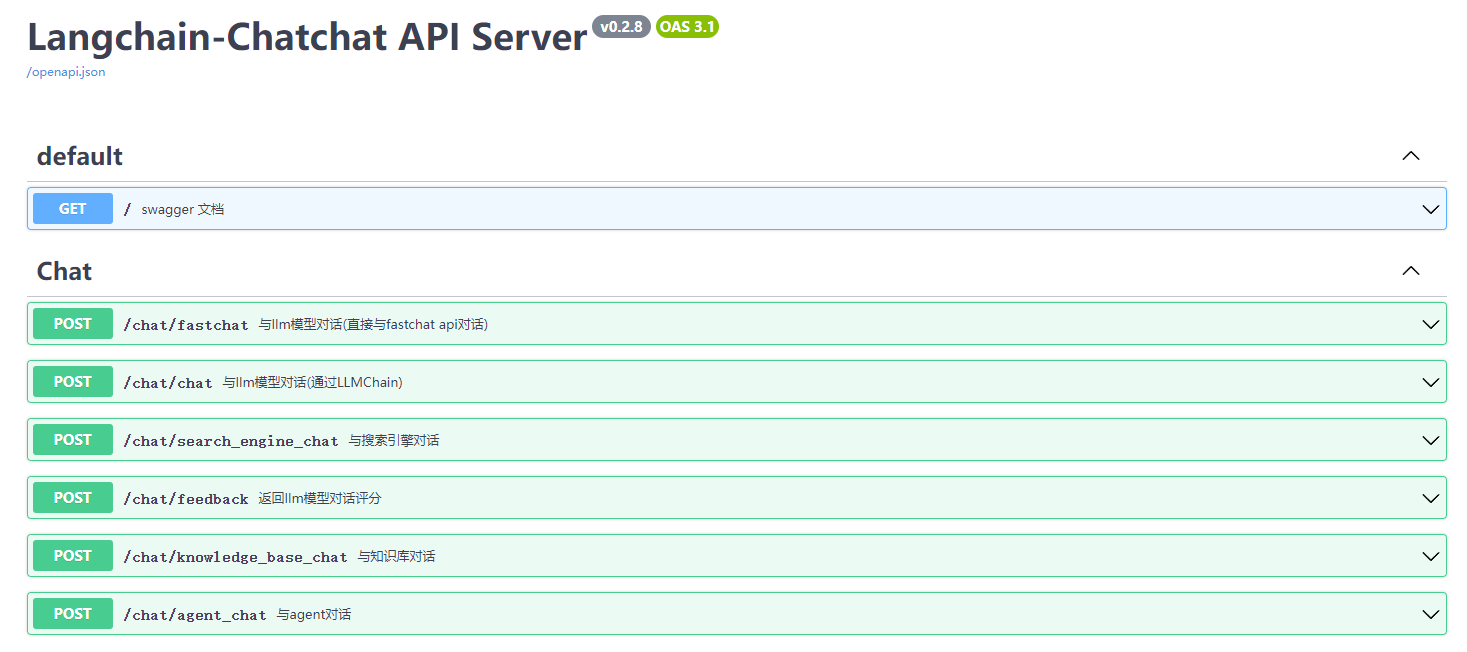
2 Chatchat一些代码学习
2.1 12个分块函数统一使用
截止 20231231 笔者看到chatchat一共有12个分chunk的函数:
CharacterTextSplitter
LatexTextSplitter
MarkdownHeaderTextSplitter
MarkdownTextSplitter
NLTKTextSplitter
PythonCodeTextSplitter
RecursiveCharacterTextSplitter
SentenceTransformersTokenTextSplitter
SpacyTextSplitterAliTextSplitter
ChineseRecursiveTextSplitter
ChineseTextSplitter
借用chatchat项目中的test/custom_splitter/test_different_splitter.py来看看一起调用make_text_splitter函数:
from langchain import document_loaders
from server.knowledge_base.utils import make_text_splitter# 使用DocumentLoader读取文件
filepath = "knowledge_base/samples/content/test_files/test.txt"
loader = document_loaders.UnstructuredFileLoader(filepath, autodetect_encoding=True)
docs = loader.load()CHUNK_SIZE = 250
OVERLAP_SIZE = 50splitter_name = 'AliTextSplitter'
text_splitter = make_text_splitter(splitter_name, CHUNK_SIZE, OVERLAP_SIZE)
if splitter_name == "MarkdownHeaderTextSplitter":docs = text_splitter.split_text(docs[0].page_content)for doc in docs:if doc.metadata:doc.metadata["source"] = os.path.basename(filepath)
else:docs = text_splitter.split_documents(docs)
for doc in docs:print(doc)2.2 知识库问答Chat的使用
本节参考chatchat开源项目的tests\api\test_stream_chat_api_thread.py 以及 tests\api\test_stream_chat_api.py
来探索一下知识库问答调用,包括:
- 流式调用
- 单次调用
- 多线程并发调用
2.2.1 流式调用
import requests
import json
import sysapi_base_url = 'http://0.0.0.0:7861'api="/chat/knowledge_base_chat"
url = f"{api_base_url}{api}"headers = {'accept': 'application/json','Content-Type': 'application/json',
}data = {"query": "如何提问以获得高质量答案","knowledge_base_name": "ZWY_V2_m3e-large","history": [{"role": "user","content": "你好"},{"role": "assistant","content": "你好,我是 ChatGLM"}],"stream": True
}
# dump_input(data, api)
response = requests.post(url, headers=headers, json=data, stream=True)
print("\n")
print("=" * 30 + api + " output" + "="*30)
for line in response.iter_content(None, decode_unicode=True):data = json.loads(line)if "answer" in data:print(data["answer"], end="", flush=True)
pprint(data)
assert "docs" in data and len(data["docs"]) > 0
assert response.status_code == 200>>>==============================/chat/knowledge_base_chat output==============================你好!提问以获得高质量答案,以下是一些建议:1. 尽可能清晰明确地表达问题:确保你的问题表述清晰、简洁、明确,以便我能够准确理解你的问题并给出恰当的回答。
2. 提供足够的上下文信息:提供相关的背景信息和上下文,以便我能够更好地理解你的问题,并给出更准确的回答。
3. 使用简洁的语言:尽量使用简单、明了的语言,以便我能够快速理解你的问题。
4. 避免使用缩写和俚语:避免使用缩写和俚语,以便我能够准确理解你的问题。
5. 分步提问:如果问题比较复杂,可以分步提问,这样我可以逐步帮助你解决问题。
6. 检查你的问题:在提问之前,请检查你的问题是否完整、清晰且准确。
7. 提供反馈:如果你对我的回答不满意,请提供反馈,以便我改进我的回答。希望这些建议能帮助你更好地提问,获得高质量的答案。结构也比较简单,call 知识库问答的URL,然后返回,通过response.iter_content来进行流式反馈。
2.2.2 正常调用以及处理并发
import requests
import json
import sysapi_base_url = 'http://139.196.103.143:7861'api="/chat/knowledge_base_chat"
url = f"{api_base_url}{api}"headers = {'accept': 'application/json','Content-Type': 'application/json',
}data = {"query": "如何提问以获得高质量答案","knowledge_base_name": "ZWY_V2_m3e-large","history": [{"role": "user","content": "你好"},{"role": "assistant","content": "你好,我是 ChatGLM"}],"stream": True
}# 正常调用并存储结果
result = []
response = requests.post(url, headers=headers, json=data, stream=True)for line in response.iter_content(None, decode_unicode=True):data = json.loads(line)result.append(data)answer = ''.join([r['answer'] for r in result[:-1]]) # 正常的结果
>>> ' 你好,很高兴为您提供帮助。以下是一些提问技巧,可以帮助您获得高质量的答案:\n\n1. 尽可能清晰明确地表达问题:确保您的问题准确、简洁、明确,以便我可以更好地理解您的问题并为您提供最佳答案。\n2. 提供足够的上下文信息:提供相关的背景信息和上下文,以便我更好地了解您的问题,并能够更准确地回答您的问题。\n3. 使用简洁的语言:尽量使用简单、明了的语言,以便我能够更好地理解您的问题。\n4. 避免使用缩写和俚语:尽量使用标准语言,以确保我能够正确理解您的问题。\n5. 分步提问:如果您有一个复杂的问题,可以将其拆分成几个简单的子问题,这样我可以更好地回答每个子问题。\n6. 检查您的拼写和语法:拼写错误和语法错误可能会使我难以理解您的问题,因此请检查您的提问,以确保它们是正确的。\n7. 指定问题类型:如果您需要特定类型的答案,请告诉我,例如数字、列表或步骤等。\n\n希望这些技巧能帮助您获得高质量的答案。如果您有其他问题,请随时问我。'refer_doc = result[-1] # 参考文献
>>> {'docs': ["<span style='color:red'>未找到相关文档,该回答为大模型自身能力解答!</span>"]}然后来看一下并发:
# 并发调用
def knowledge_chat(api="/chat/knowledge_base_chat"):url = f"{api_base_url}{api}"data = {"query": "如何提问以获得高质量答案","knowledge_base_name": "samples","history": [{"role": "user","content": "你好"},{"role": "assistant","content": "你好,我是 ChatGLM"}],"stream": True}result = []response = requests.post(url, headers=headers, json=data, stream=True)for line in response.iter_content(None, decode_unicode=True):data = json.loads(line)result.append(data)return resultfrom concurrent.futures import ThreadPoolExecutor, as_completed
import timethreads = []
times = []
pool = ThreadPoolExecutor()
start = time.time()
for i in range(10):t = pool.submit(knowledge_chat)threads.append(t)for r in as_completed(threads):end = time.time()times.append(end - start)print("\nResult:\n")pprint(r.result())print("\nTime used:\n")
for x in times:print(f"{x}")通过concurrent的ThreadPoolExecutor, as_completed进行反馈
3 知识库相关实践问题
3.1 .md格式的文件 支持非常差
我们在configs/kb_config.py可以看到:
# TextSplitter配置项,如果你不明白其中的含义,就不要修改。
text_splitter_dict = {"ChineseRecursiveTextSplitter": {"source": "huggingface", # 选择tiktoken则使用openai的方法"tokenizer_name_or_path": "",},"SpacyTextSplitter": {"source": "huggingface","tokenizer_name_or_path": "gpt2",},"RecursiveCharacterTextSplitter": {"source": "tiktoken","tokenizer_name_or_path": "cl100k_base",},"MarkdownHeaderTextSplitter": {"headers_to_split_on":[("#", "head1"),("##", "head2"),("###", "head3"),("####", "head4"),]},
}# TEXT_SPLITTER 名称
TEXT_SPLITTER_NAME = "ChineseRecursiveTextSplitter"
chatchat看上去创建新知识库的时候,仅支持一个知识库一个TEXT_SPLITTER_NAME 的方法,并不能做到不同的文件,使用不同的切块模型。
所以如果要一个知识库内,不同文件使用不同的切分方式,需要自己改整个结构代码;然后重启项目
同时,chatchat项目对markdown的源文件,支持非常差,我们来看看:
from langchain import document_loaders
from server.knowledge_base.utils import make_text_splitter# 载入
filepath = "matt/智能XXX.md"
loader = document_loaders.UnstructuredFileLoader(filepath,autodetect_encoding=True)
docs = loader.load()# 切分
splitter_name = 'ChineseRecursiveTextSplitter'
text_splitter = make_text_splitter(splitter_name, CHUNK_SIZE, OVERLAP_SIZE)
if splitter_name == "MarkdownHeaderTextSplitter":docs = text_splitter.split_text(docs[0].page_content)for doc in docs:if doc.metadata:doc.metadata["source"] = os.path.basename(filepath)
else:docs = text_splitter.split_documents(docs)
for doc in docs:print(doc)首先chatchat对.md文件读入使用的是UnstructuredFileLoader,但是没有加mode="elements"(参考:LangChain:万能的非结构化文档载入详解(一))
所以,你可以认为,读入后,#会出现丢失,于是你即使选择了MarkdownHeaderTextSplitter,也还是无法使用。
目前来看,不建议上传.md格式的文档,比较好的方法是:
- 文件改成 doc,可以带
#/##/### - 更改
configs/kb_config.py当中的TEXT_SPLITTER_NAME = "MarkdownHeaderTextSplitter"
这篇关于Langchain-Chatchat开源库使用的随笔记(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





