本文主要是介绍GPT3.5 改用 GPT4 价格翻了30倍 如何破局? GPT 对话成本推演,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
场景介绍
假设你搭建了一个平台,提供 ChatGPT 3.5 的聊天服务。目前已经有一批用户的使用数据,想要测算一下如果更换 GPT 4.0 服务需要多少成本?
方案阐述
如果是全切,最简单粗暴的方案就是根据提供 ChatGPT 3.5 消费的金额乘以一个倍数,这个倍数是 GPT 4 的单格/ChatGPT 3.5 的单价,不过由于输入价和输出价有差异,所以会有一定误差,但不影响全量切换的大致判断。
如果要求更精确一些,就需要根据每一次问答的输入 Token 数和输出 Token 数,分别求和,计算有多少 k Tokens,然后算一个占比,看看各自的消费占比,分别乘以输入和输出的价格倍数。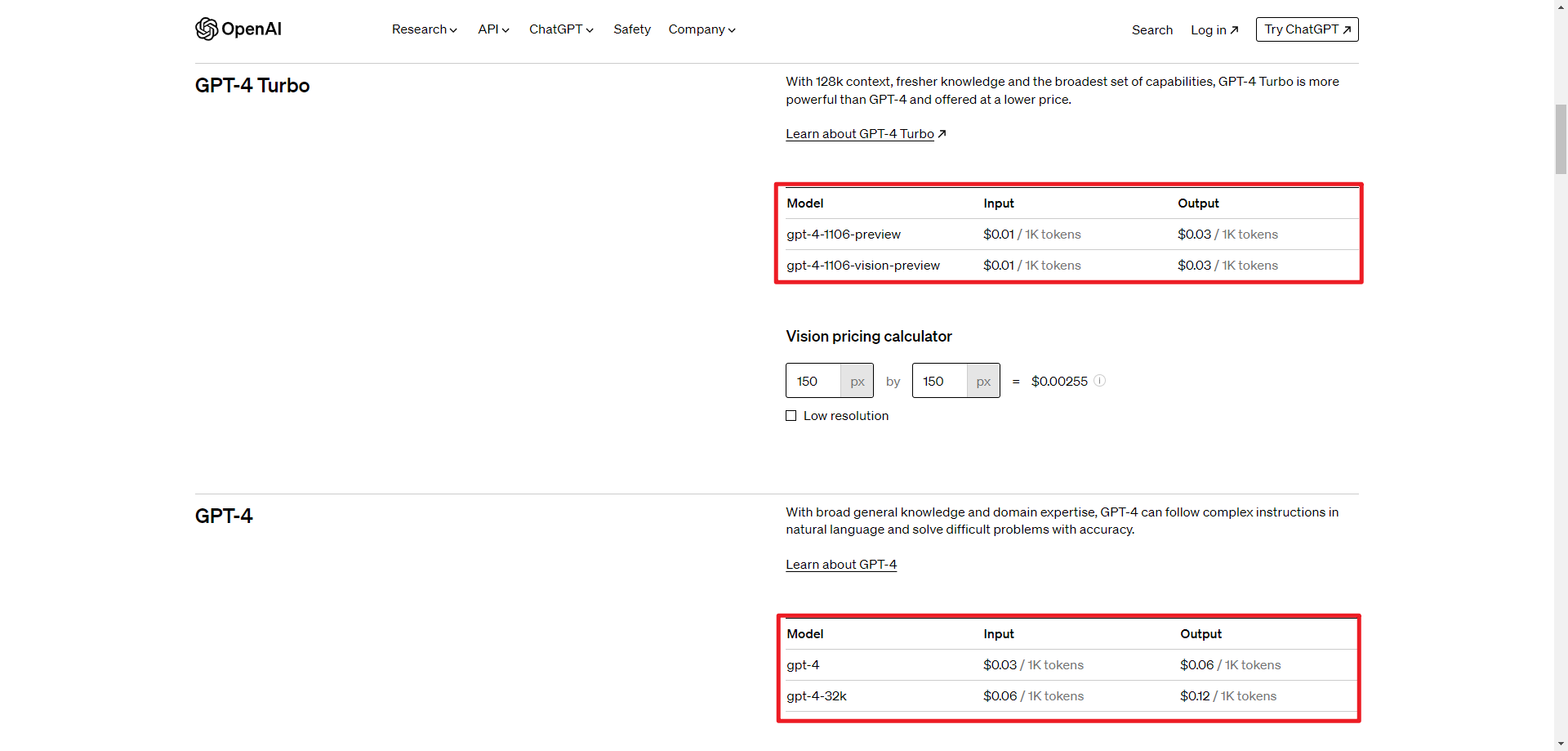
以上是直接接官方的情况,但是更多时候,可能是通过第三方服务,第三方的价格不是根据官方定价,会有出入,需要结合第三方价格具体分析。
由于 GPT 4.0 相对高昂的价格,一般需要做限制,比如:限制访问频率、限制整体用量等。
举个例子,限制每分钟不超过 3 次,每 3 小时不超过 50 次;每天 10 次,每月 100次、200 次等。
这时候就需要精确一些的计算,通过指定的算法,测算切换 GPT 4.0 的成本是多少。
本次用于示例计算的单价为:
| Model | Input | Output |
|---|---|---|
| gpt-4 | $0.03 / 1K tokens | $0.06 / 1K tokens |
| gpt-3.5-turbo-1106 | $0.0010 / 1K tokens | $0.0020 / 1K tokens |
本次拿两个限制做案例开展:
- 案例1:限制每天 10 次
- 案例2:限制每分钟不超过 3 次,每 3 小时不超过 50 次
创建测试数据
本次测试借助数据库 MySQL 来实现这些复杂的算法。
首先在本地创建数据库testdb。
create database if not exists testdb;
创建表chat_logs,并给四个字段都加上索引,提高查询效率:
create table if not exists testdb.chat_logs(user_id bigint comment '用户ID',request_time bigint comment '请求时间',prompt_tokens bigint comment '提示词的 Tokens,input Tokens',output_tokens bigint comment '回答的 Tokens,output Tokens',index userid_idx(user_id),index reqtime_idx(request_time),index prompt_idx(prompt_tokens),index output_idx(output_tokens)
) comment 'GPT对话记录';
插入数据,本次demo 数据量 100 条。
由于数据较长,不便展示,另外上传到资源,可前往免费下载:GPT 对话成本推演-数据demo
插入数据方法
- 方法1:复制代码,接着上面步骤粘贴代码,回车即可执行
- 方法2:直接执行文件,假设文件路径为:D:\insert_into_table.sql,则执行命令如下:
SOURCE D:\insert_into_table.sql;
案例1:限制每天 10 次(总量限制)
该逻辑实现比较简单,按天聚合,然后排序计算不超过 10 有多少 Tokens,大于 10 次又有多少 Tokens,然后再分别乘以单价,计算得出限制后的成本。
使用 SQL 实现
查看每天限制 10 次 GPT 4.0,超过部分按 GPT 3.5 计算,需要先将请求的数据按天进行排序,然后计算不超过 10 的部分和大于 10 的分别的 Tokens 分别是多少。
格式化时间,将request_time转为request_date
-- 格式化时间
select user_id,from_unixtime(request_time,'%Y-%m-%d') request_date,request_time,prompt_tokens,output_tokens
from testdb.chat_logs
按天编号
with chat_logs_format as(-- 格式化时间select user_id,from_unixtime(request_time,'%Y-%m-%d') request_date,request_time,prompt_tokens,output_tokensfrom testdb.chat_logs
)
-- 对话排序
select *,row_number()over(partition by user_id,request_date order by request_time) req_sort
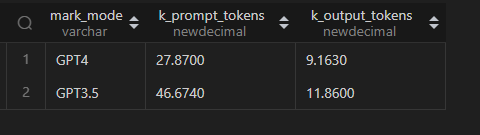
from chat_logs_format分类求 Tokens 数,编号req_sort不超过 10 次的分为GPT4,其他分为GPT3.5。
with chat_logs_format as(-- 格式化时间select user_id,from_unixtime(request_time,'%Y-%m-%d') request_date,request_time,prompt_tokens,output_tokensfrom testdb.chat_logs
)
,chat_sort as(-- 对话排序select user_id,request_date,prompt_tokens,output_tokens,row_number()over(partition by user_id,request_date order by request_time) req_sortfrom chat_logs_format
)
-- 分类求 Tokens 数
select if(req_sort<=10,'GPT4','GPT3.5') mark_model,sum(prompt_tokens)/1000 k_prompt_tokens,sum(output_tokens)/1000 k_output_tokens
from chat_sort
group by mark_model
根据 Tokens 计算成本。
with chat_logs_format as(-- 格式化时间select user_id,from_unixtime(request_time,'%Y-%m-%d') request_date,request_time,prompt_tokens,output_tokensfrom testdb.chat_logs
)
,chat_sort as(-- 对话排序select user_id,request_date,prompt_tokens,output_tokens,row_number()over(partition by user_id,request_date order by request_time) req_sortfrom chat_logs_format
)
,k_tokens as(-- 分类求 Tokens 数select if(req_sort<=10,'GPT4','GPT3.5') mark_model,sum(prompt_tokens)/1000 k_input_tokens,sum(output_tokens)/1000 k_output_tokensfrom chat_sortgroup by mark_model
)
-- gpt-4:input 0.03,output 0.06
-- gpt-3:input 0.0010,output 0.0020
select sum(0.0010*k_input_tokens+0.0020*k_output_tokens) "调整前成本",sum(if(mark_model='GPT4',0.03,0.0010)*k_input_tokens+if(mark_model='GPT4',0.06,0.0020)*k_output_tokens) "调整后成本"
from k_tokens
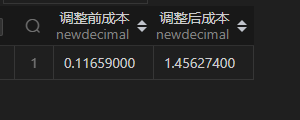
调整前后成本相差还是挺大的,调整后成本是调整前的 12.5 倍。实际情况可以拿更多的数据,比如说一周、一个月,进行测算。
使用 Python 实现
使用 Python 实现比 SQL 实现多加了一步:读取数据,并转化为数组。之后的逻辑也是大同小异:时间格式化->记录排序、编号->分类求 Token->计算成本。
读取数据表,使用sql读取数据库数据,并使用 Pandas 转为 DataFrame。
import pandas as pd
from sqlalchemy import create_engine
def get_datas(sql):# 连接数据库# engine = create_engine("mysql+pymysql://用户名:密码@主机地址:端口号/数据库名")connect_info = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'\.format("root", "123123", "127.1.1.0", "3306","testdb")engine = create_engine(connect_info)# 执行SQL语句prox = engine.execute(sql)df = pd.DataFrame(list(prox),columns=prox.keys())return df
sql = 'select * from testdb.chat_logs'
df = get_datas(sql)
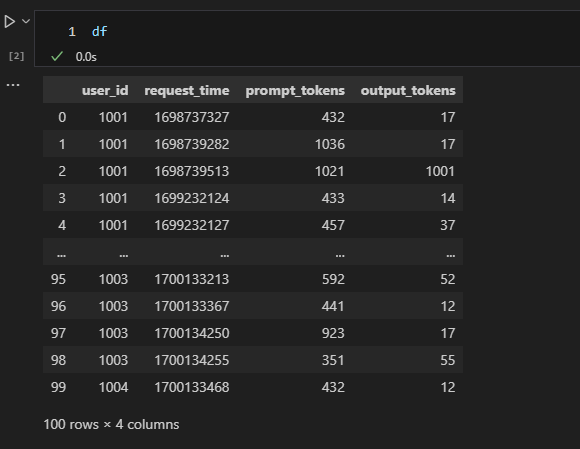
将时间戳格式化
#将 request_time 转为日期格式
df['request_date'] = pd.to_datetime(df.request_time,unit='s').dt.date
排序编号
df['req_sort'] = df.groupby(['user_id','request_date'])['request_time'].rank(ascending=True,method='first')
分类,编号req_sort不超过 10 次的分为GPT4,其他分为GPT3.5。
df['mark_model'] = df.req_sort.apply(lambda x:'GPT4' if x<=10 else 'GPT3.5')
求和,并转化为 k Token 单位
df_1 = df.groupby(['mark_model'])['prompt_tokens','output_tokens'].sum().reset_index()
df_1['k_input_tokens'] = df_1.prompt_tokens/1000
df_1['k_output_tokens'] = df_1.output_tokens/1000
df_1[['mark_model','k_input_tokens','k_output_tokens']]
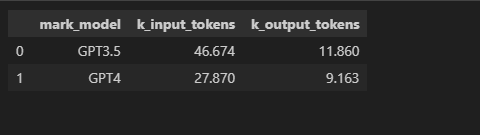
计算成本
-- gpt-4:input 0.03,output 0.06
-- gpt-3:input 0.0010,output 0.0020
input_price_4 = 0.03
input_price_3 = 0.0010
output_price_4 = 0.06
output_price_3 = 0.0020
df_1['调整前成本'] = df_1[['mark_model','k_input_tokens','k_output_tokens']].apply(lambda x:x[1]*input_price_3+x[2]*output_price_3,axis=1)
df_1['调整后成本'] = df_1[['mark_model','k_input_tokens','k_output_tokens']].apply(lambda x:x[1]*input_price_4+x[2]*output_price_4 if x[0]=='GPT4' else x[1]*input_price_3+x[2]*output_price_3,axis=1)
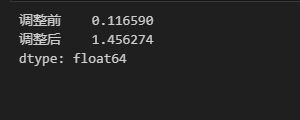
df_1[['调整前成本','调整后成本']].sum()
案例2:限制每分钟不超过 3 次,每 3 小时不超过 50 次(频率限制)
该逻辑实现比较复杂一些,本质上还是先切分,然后排序再进行统计 Tokens,再计算成本。
不同点在于,前面是按天切分,有天然的便捷方式,直接格式化即可,每天看做一个桶,分桶计算,而 1 分钟和 3 小时需要自行构建相关的计算桶,不能一步到位。
过程算法其实也有多种:
比如说按自然分钟计算,每分钟为一个单位;按自然小时计算,02、35、68、911、1214、1517、1820、2123。
比如说拿一个初始的值做差值计算,然后在这个基础上分割,这个会受到初始值的影响,不过如果把初始值设置为某一天的零时零点零分,可以兼容上面一个算法,本次拿第二种来展开。
PS:实现第一种的方法:1分钟分桶:from_unixtime(request_time,’%Y-%m-%d %H:%i’);3小时分桶(日期+小时):from_unixtime(request_time,’%Y-%m-%d’)、floor(hour(from_unixtime(request_time)/3)
使用 SQL 实现
取最小时间,使用窗口函数来取值。如果是想设置固定的某个值,可以直接新增一个列。
-- 取最小的请求时间,
select user_id,request_time,prompt_tokens,output_tokens,min(request_time)over(partition by user_id) min_time
from chat_logs
求时间差值,使用request_time减去最小值。
-- 取时间差值
select user_id,request_time,prompt_tokens,output_tokens,request_time-min(request_time)over(partition by user_id) minute_diff
from chat_logs
分桶,1 分钟则除以 60 秒,3 小时则除以 60603 秒,然后使用ceil()函数向上取值。
-- 分桶
select user_id,request_time,prompt_tokens,output_tokens,ceil((request_time-min(request_time)over(partition by user_id))/60) minute_bucket,ceil((request_time-min(request_time)over(partition by user_id))/60/60/3) hour_bucket
from chat_logs
排序,根据用户和分桶字段进行分组,然后对request_time升序排序
with
-- 分桶
cut_bucket as(select user_id,request_time,prompt_tokens,output_tokens,ceil((request_time-min(request_time)over(partition by user_id))/60) minute_bucket,ceil((request_time-min(request_time)over(partition by user_id))/60/60/3) hour_bucketfrom chat_logs
)
-- 排序
select user_id,request_time,prompt_tokens,output_tokens,minute_bucket,hour_bucket,row_number()over(partition by user_id,minute_bucket order by request_time) minute_bucket_sort,row_number()over(partition by user_id,hour_bucket order by request_time) hour_bucket_sort
from cut_bucket
分类求和,将minute_bucket_sort<=3 and hour_bucket_sort<=50分为GPT4,其他的分为GPT3.5,然后聚合求 Tokens。
with
-- 分桶
cut_bucket as(select user_id,request_time,prompt_tokens,output_tokens,ceil((request_time-min(request_time)over(partition by user_id))/60) minute_bucket,ceil((request_time-min(request_time)over(partition by user_id))/60/60/3) hour_bucketfrom chat_logs
)
-- 排序
,bucket_sort as(select user_id,request_time,prompt_tokens,output_tokens,minute_bucket,hour_bucket,row_number()over(partition by user_id,minute_bucket order by request_time) minute_bucket_sort,row_number()over(partition by user_id,hour_bucket order by request_time) hour_bucket_sortfrom cut_bucket
)
-- 分类
,mark_models as(select user_id,request_time,prompt_tokens,output_tokens,minute_bucket,hour_bucket,minute_bucket_sort,hour_bucket_sort,(case when minute_bucket_sort<=3 and hour_bucket_sort<=50 then 'GPT4' else 'GPT3.5' end) mark_modelfrom bucket_sort
)
-- 计算分钟<=3且3小时<=50
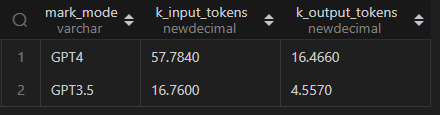
select mark_model,sum(prompt_tokens)/1000 k_input_tokens,sum(output_tokens)/1000 k_output_tokens
from mark_models
group by mark_model
然后再计算成本,完事!
直接计算minute_bucket_sort<=3且hour_bucket_sort<=50就可以了?
不不不!这里有坑,先不聚合,查看明细数据看看,如下图第一个红框,它不符合 1 分钟 3 次上限的逻辑,所以被剔除了,标记为 GPT3.5。而第二个框,它不符合 3 小时 50 次上限的逻辑,所以也被剔除了。
不知道你是否意识到了问题,通过肉眼看,第二个框的 3 条记录应该是要被统计到 3 小时 50 次上限的逻辑的,因为前面因为 1 分钟的限制多剔除了 3 条记录。
所以在 3 小时的桶里面排序的时候,需要建立 1 分钟的桶的基础之上,先保证每一条记录都符合 1 分钟的逻辑,再针对这些记录拿 3 小时的逻辑加以限制。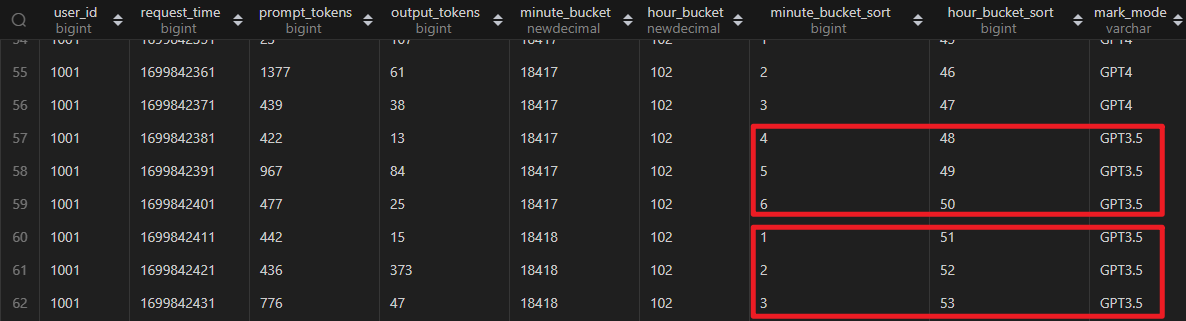
修改 3 小时的分桶排序逻辑,要建立在 1 分钟的基础上才开始排序。
新增一个步骤,对 1 分钟的桶不超过 3 次的部分和大于 3 次的部分进行分类。然后对 3 小时的分桶排序则建在 1 分钟不超过 3 次的类别上。
代码实现上,将 1 分钟不超过 3 次和大于 3 次的分类(mark_target_record)加入 3 小时的分桶排序的分组(partition by)中,然后限制只取mark_target_record=1部分作为GPT4,参考修改逻辑如下:
with
-- 分桶
cut_bucket as(select user_id,request_time,prompt_tokens,output_tokens,ceil((request_time-min(request_time)over(partition by user_id))/60) minute_bucket,ceil((request_time-min(request_time)over(partition by user_id))/60/60/3) hour_bucketfrom chat_logs
)
-- 排序
,bucket_sort as(select user_id,request_time,prompt_tokens,output_tokens,minute_bucket,hour_bucket,row_number()over(partition by user_id,minute_bucket order by request_time) minute_bucket_sort,row_number()over(partition by user_id,hour_bucket order by request_time) hour_bucket_sortfrom cut_bucket
)
-- 对分钟的排序数据进行分类
,mark_chatlog as(select user_id,request_time,prompt_tokens,output_tokens,minute_bucket,hour_bucket,minute_bucket_sort,hour_bucket_sort,(case when minute_bucket_sort<=3 then 1 else 0 end) mark_target_recordfrom bucket_sort
)
-- 分钟 <= 3 且 3小时 <= 50 标记为 GPT4
,mark_models as(select user_id,request_time,prompt_tokens,output_tokens,minute_bucket,hour_bucket,minute_bucket_sort,hour_bucket_sort,mark_target_record,(case when mark_target_record=1 and row_number() over(partition by user_id,hour_bucket,mark_target_record order by request_time)<=50 then 'GPT4' else 'GPT3.5' end) mark_modelfrom mark_chatlog
)
select *
from mark_models
order by user_id,request_time修改为叠加的逻辑之后,效果如下: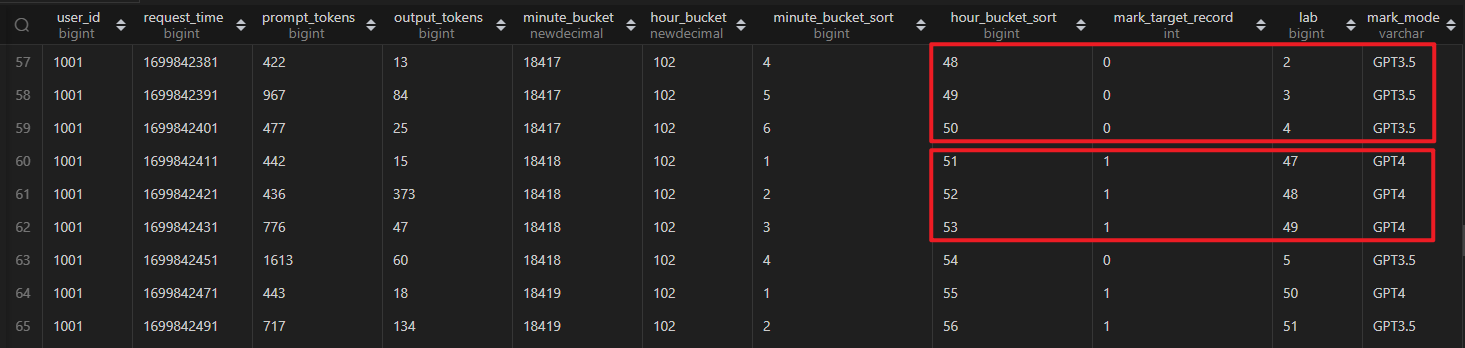
计算 Token 数,根据分好的模型聚合求和即可。
with
-- 分桶
cut_bucket as(select user_id,request_time,prompt_tokens,output_tokens,ceil((request_time-min(request_time)over(partition by user_id))/60) minute_bucket,ceil((request_time-min(request_time)over(partition by user_id))/60/60/3) hour_bucketfrom chat_logs
)
-- 排序
,bucket_sort as(select user_id,request_time,prompt_tokens,output_tokens,minute_bucket,hour_bucket,row_number()over(partition by user_id,minute_bucket order by request_time) minute_bucket_sort,row_number()over(partition by user_id,hour_bucket order by request_time) hour_bucket_sortfrom cut_bucket
)
-- 对分钟的排序数据进行分类
,mark_chatlog as(select user_id,request_time,prompt_tokens,output_tokens,minute_bucket,hour_bucket,minute_bucket_sort,hour_bucket_sort,(case when minute_bucket_sort<=3 then 1 else 0 end) mark_target_recordfrom bucket_sort
)
-- 分钟 <= 3 且 3小时 <= 50 标记为 GPT4
,mark_models as(select user_id,request_time,prompt_tokens,output_tokens,minute_bucket,hour_bucket,minute_bucket_sort,hour_bucket_sort,mark_target_record,(case when mark_target_record=1 and row_number() over(partition by user_id,hour_bucket,mark_target_record order by request_time)<=50 then 'GPT4' else 'GPT3.5' end) mark_modelfrom mark_chatlog
)
-- 聚合求 Tokens
select mark_model,sum(prompt_tokens)/1000 k_input_tokens,sum(output_tokens)/1000 k_output_tokens
from mark_models
group by mark_model统计结果如下: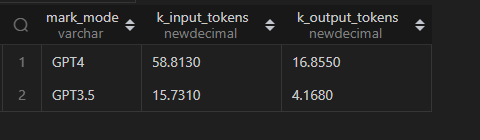
计算调整前后成本:
with
-- 分桶
cut_bucket as(select user_id,request_time,prompt_tokens,output_tokens,ceil((request_time-min(request_time)over(partition by user_id))/60) minute_bucket,ceil((request_time-min(request_time)over(partition by user_id))/60/60/3) hour_bucketfrom chat_logs
)
-- 排序
,bucket_sort as(select user_id,request_time,prompt_tokens,output_tokens,minute_bucket,hour_bucket,row_number()over(partition by user_id,minute_bucket order by request_time) minute_bucket_sort,row_number()over(partition by user_id,hour_bucket order by request_time) hour_bucket_sortfrom cut_bucket
)
-- 对分钟的排序数据进行分类
,mark_chatlog as(select user_id,request_time,prompt_tokens,output_tokens,minute_bucket,hour_bucket,minute_bucket_sort,hour_bucket_sort,(case when minute_bucket_sort<=3 then 1 else 0 end) mark_target_recordfrom bucket_sort
)
-- 分钟 <= 3 且 3小时 <= 50 标记为 GPT4
,mark_models as(select user_id,request_time,prompt_tokens,output_tokens,minute_bucket,hour_bucket,minute_bucket_sort,hour_bucket_sort,mark_target_record,(case when mark_target_record=1 and row_number() over(partition by user_id,hour_bucket,mark_target_record order by request_time)<=50 then 'GPT4' else 'GPT3.5' end) mark_modelfrom mark_chatlog
)
-- 聚合求 Tokens
,k_tokens as(select mark_model,sum(prompt_tokens)/1000 k_input_tokens,sum(output_tokens)/1000 k_output_tokensfrom mark_modelsgroup by mark_model
)
-- gpt-4:input 0.03,output 0.06
-- gpt-3:input 0.0010,output 0.0020
select sum(0.0010*k_input_tokens+0.0020*k_output_tokens) "调整前成本",sum(if(mark_model='GPT4',0.03,0.0010)*k_input_tokens+if(mark_model='GPT4',0.06,0.0020)*k_output_tokens) "调整后成本"
from k_tokens
统计结果如下: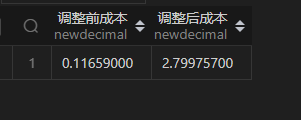
调整前后成本相差 27 倍。
使用 Python 实现
同样,使用 Python 实现比 SQL 实现多加了一步:读取数据,并转化为数组。之后的逻辑也是大同小异:求最小时间->求时间差值->分桶->1分钟排序和分类->3 小时排序和最终分类->分类求 Token->计算成本。
读取数据表,使用sql读取数据库数据,并使用 Pandas 转为 DataFrame。
import pandas as pd
from sqlalchemy import create_engine
def get_datas(sql):# 连接数据库# engine = create_engine("mysql+pymysql://用户名:密码@主机地址:端口号/数据库名")connect_info = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'\.format("root", "123123", "127.1.1.0", "3306","testdb")engine = create_engine(connect_info)# 执行SQL语句prox = engine.execute(sql)df = pd.DataFrame(list(prox),columns=prox.keys())return df
sql = 'select * from testdb.chat_logs'
df = get_datas(sql)
取最小请求时间,并合并到原来的数据框。
#取每个key的最小请求时间
df_mintime = df.groupby(['user_id'])['request_time'].min().reset_index()
#合并到原DataFrame
df = df.merge(df_mintime,on='user_id',how='left',suffixes=['','_min'])
将请求时间和最小请求时间求差值。
#将请求时间和最小请求时间求差值;
df['diff_time'] = df.request_time-df.request_time_min
分桶,保持单位一致,即 1 分钟转为 60 秒,3 小时转为 60603 秒。
使用math.ceil()向上取整。
#根据差值进行分桶,两层:1 分钟 和 3 小时,都向上取整数;
import math
df['minute_bucket'] = df.diff_time.apply(lambda x:math.ceil(x/60))
df['hour_bucket'] = df.diff_time.apply(lambda x:math.ceil(x/60/60/3))
对 1 分钟的桶排序和分类:不超过 3 次的为一类用 1 标识,其他的为另外一类,用 0 表示。
#对 1 分钟的桶和 user_id 分组,按请求时间排序;
df['minute_bucket_sort'] = df.groupby(['user_id','minute_bucket'])['request_time'].rank(ascending=True,method='first')
#对 1 分钟不超过 3 次和大于 3 次的部分进行分组
df['mark_target_record'] = df.minute_bucket_sort.apply(lambda x:1 if x<=3 else 0)3 小时的桶排序,根据用户、分桶和 1 分钟的分类进行分组,按请求时间排序。
#3小时的桶排序
df['hour_bucket_sort'] = df.groupby(['user_id','hour_bucket','mark_target_record'])['request_time'].rank(ascending=True,method='first')
最终分类:minute_bucket_sort<=3,且hour_bucket_sort<=50为 GPT4,其他为 GPT3.5。
#最终分类
df['mark_model'] = df[['minute_bucket_sort','hour_bucket_sort']].apply(lambda x:'GPT4' if x[0]<=3 and x[1]<=50 else 'GPT3.5',axis=1)
分类聚合求 Tokens
#按请求日期和模型聚合,统计Tokens 和价格
df_1 = df.groupby(['mark_model'])['prompt_tokens','output_tokens'].sum().reset_index()
df_1['k_input_tokens'] = df_1.prompt_tokens/1000
df_1['k_output_tokens'] = df_1.output_tokens/1000
df_1[['mark_model','k_input_tokens','k_output_tokens']]
结果如下,再除以 1000 就是上面 SQL 的结果。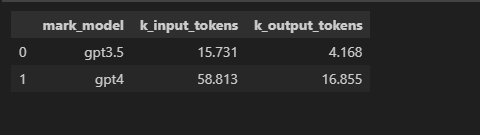
求最终调整前后成本
#求调整前后成本
#gpt-4:input 0.03,output 0.06
#gpt-3:input 0.0010,output 0.0020
input_price_4 = 0.03
input_price_3 = 0.0010
output_price_4 = 0.06
output_price_3 = 0.0020
df_1['调整前成本'] = df_1[['mark_model','k_input_tokens','k_output_tokens']].apply(lambda x:x[1]*input_price_3+x[2]*output_price_3,axis=1)
df_1['调整后成本'] = df_1[['mark_model','k_input_tokens','k_output_tokens']].apply(lambda x:x[1]*input_price_4+x[2]*output_price_4 if x[0]=='GPT4' else x[1]*input_price_3+x[2]*output_price_3,axis=1)
df_1[['调整前成本','调整后成本']].sum()
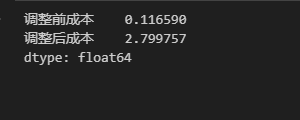
Python 完整代码:
import pandas as pd
from sqlalchemy import create_engine#连接数据库读取数据,并转为 DataFrame
def get_datas(sql):# 连接数据库# engine = create_engine("mysql+pymysql://用户名:密码@主机地址:端口号/数据库名")connect_info = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'\.format("root", "123123", "127.1.1.0", "3306","testdb")engine = create_engine(connect_info)# 执行SQL语句prox = engine.execute(sql)data = list()for result in prox:cur = dict()# print(result)for k, v in result._mapping.items(): # 不用 _mapping 也可以,后续会被弃用而已cur[k] = vdata.append(cur)df = pd.DataFrame(data)return df
sql = 'select * from testdb.chat_logs'
df = get_datas(sql)#取每个key的最小请求时间
df_mintime = df.groupby(['user_id'])['request_time'].min().reset_index()
#合并到原DataFrame
df = df.merge(df_mintime,on='user_id',how='left',suffixes=['','_min'])#将请求时间和最小请求时间求差值;
df['diff_time'] = df.request_time-df.request_time_min#根据差值进行分桶,两层:1 分钟 和 3 小时,都向上取整数;
import math
df['minute_bucket'] = df.diff_time.apply(lambda x:math.ceil(x/60))
df['hour_bucket'] = df.diff_time.apply(lambda x:math.ceil(x/60/60/3))#对 1 分钟的桶和 user_id 分组,按请求时间排序;
df['minute_bucket_sort'] = df.groupby(['user_id','minute_bucket'])['request_time'].rank(ascending=True,method='first')
#对 1 分钟不超过 3 次和大于 3 次的部分进行分组
df['mark_target_record'] = df.minute_bucket_sort.apply(lambda x:1 if x<=3 else 0)
#3小时的桶排序
df['hour_bucket_sort'] = df.groupby(['user_id','hour_bucket','mark_target_record'])['request_time'].rank(ascending=True,method='first')
#最终分类
df['mark_model'] = df[['minute_bucket_sort','hour_bucket_sort']].apply(lambda x:'GPT4' if x[0]<=3 and x[1]<=50 else 'GPT3.5',axis=1)#按请求日期和模型聚合,统计Tokens 和价格
df_1 = df.groupby(['mark_model'])['prompt_tokens','output_tokens'].sum().reset_index()
df_1['k_input_tokens'] = df_1.prompt_tokens/1000
df_1['k_output_tokens'] = df_1.output_tokens/1000
df_1[['mark_model','k_input_tokens','k_output_tokens']]#求调整前后成本
#gpt-4:input 0.03,output 0.06
#gpt-3:input 0.0010,output 0.0020
input_price_4 = 0.03
input_price_3 = 0.0010
output_price_4 = 0.06
output_price_3 = 0.0020
df_1['调整前成本'] = df_1[['mark_model','k_input_tokens','k_output_tokens']].apply(lambda x:x[1]*input_price_3+x[2]*output_price_3,axis=1)
df_1['调整后成本'] = df_1[['mark_model','k_input_tokens','k_output_tokens']].apply(lambda x:x[1]*input_price_4+x[2]*output_price_4 if x[0]=='GPT4' else x[1]*input_price_3+x[2]*output_price_3,axis=1)
df_1[['调整前成本','调整后成本']].sum()
小结
从上面的两个案例来看,成本都是以十倍上涨,不过加了限制,最高也不会超过官方标价的倍数(30 倍)。
但无论如何,成本较之前都是很高的。
如果想要保证用户体验好、可以多用GPT4、成本又不高,那是很难的。
当然,解决办法还是有的:
- 用户层面:可以搞会员制,要求不高的,用用GPT3.5,要求高的多掏钱买个会员。
- 供应商层面:降低成本,这个要拼渠道了。
没有完美的,只有合适的,看需求搞事情~
这篇关于GPT3.5 改用 GPT4 价格翻了30倍 如何破局? GPT 对话成本推演的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








