本文主要是介绍推荐七款常用的Python数据可视化模块,数据可视化的福利,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

数据可视化的库有挺多的,这里推荐几个比较常用的:
Matplotlib
Plotly
Seaborn
Ggplot
Bokeh
Pyechart
Pygal
关注后私信小编 PDF领取十套电子文档书籍
Plotly
plotly 文档地址(https://plot.ly/python/#financial-charts)
使用方式:
plotly 有 online 和 offline 两种方式,这里只介绍 offline 的。

这是 plotly 官方教程的一部分
import plotly.plotly as py
import numpy as np
data = [dict(
visible=False,
line=dict(color=’#00CED1’, width=6), # 配置线宽和颜色
name=’ = ’ + str(step),
x=np.arange(0, 10, 0.01), # x 轴参数
y=np.sin(step * np.arange(0, 10, 0.01))) for step in np.arange(0, 5, 0.1)] # y 轴参数
data[10][‘visible’] = True
py.iplot(data, filename=‘Single Sine Wave’)
只要将最后一行中的
py.iplot
替换为下面代码
py.offline.plot
便可以运行。
漏斗图
这个图代码太长了,就不 po 出来了。

Basic Box Plot
好吧,不知道怎么翻译,直接用原名。

import plotly.plotly
import plotly.graph_objs as go
import numpy as np
y0 = np.random.randn(50)-1
y1 = np.random.randn(50)+1
trace0 = go.Box(
y=y0
)
trace1 = go.Box(
y=y1
)
data = [trace0, trace1]
plotly.offline.plot(data)
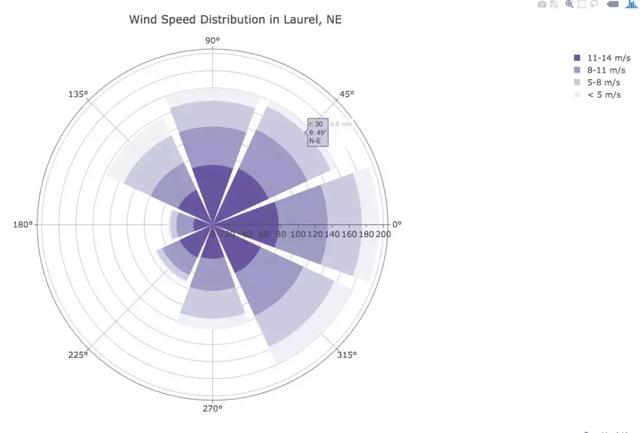
Wind Rose Chart
好吧,不知道怎么翻译,直接用原名。
import plotly.graph_objs as go
trace1 = go.Barpolar(
r=[77.5, 72.5, 70.0, 45.0, 22.5, 42.5, 40.0, 62.5],
text=[‘North’, ‘N-E’, ‘East’, ‘S-E’, ‘South’, ‘S-W’, ‘West’, ‘N-W’],
name=‘11-14 m/s’,
marker=dict(
color=‘rgb(106,81,163)’
)
)
trace2 = go.Barpolar(
r=[57.49999999999999, 50.0, 45.0, 35.0, 20.0, 22.5, 37.5, 55.00000000000001],
text=[‘North’, ‘N-E’, ‘East’, ‘S-E’, ‘South’, ‘S-W’, ‘West’, ‘N-W’], # 鼠标浮动标签文字描述
name=‘8-11 m/s’,
marker=dict(
color=‘rgb(158,154,200)’
)
)
trace3 = go.Barpolar(
r=[40.0, 30.0, 30.0, 35.0, 7.5, 7.5, 32.5, 40.0],
text=[‘North’, ‘N-E’, ‘East’, ‘S-E’, ‘South’, ‘S-W’, ‘West’, ‘N-W’],
name=‘5-8 m/s’,
marker=dict(
color=‘rgb(203,201,226)’
)
)
trace4 = go.Barpolar(
r=[20.0, 7.5, 15.0, 22.5, 2.5, 2.5, 12.5, 22.5],
text=[‘North’, ‘N-E’, ‘East’, ‘S-E’, ‘South’, ‘S-W’, ‘West’, ‘N-W’],
name=’
marker=dict(
color=‘rgb(242,240,247)’
)
)
data = [trace1, trace2, trace3, trace4]
layout = go.Layout(
title=‘Wind Speed Distribution in Laurel, NE’,
font=dict(
size=16
),
legend=dict(
font=dict(
size=16
)
),
radialaxis=dict(
ticksuffix=’%’
),
orientation=270
)
fig = go.Figure(data=data, layout=layout)
plotly.offline.plot(fig, filename=‘polar-area-chart’)
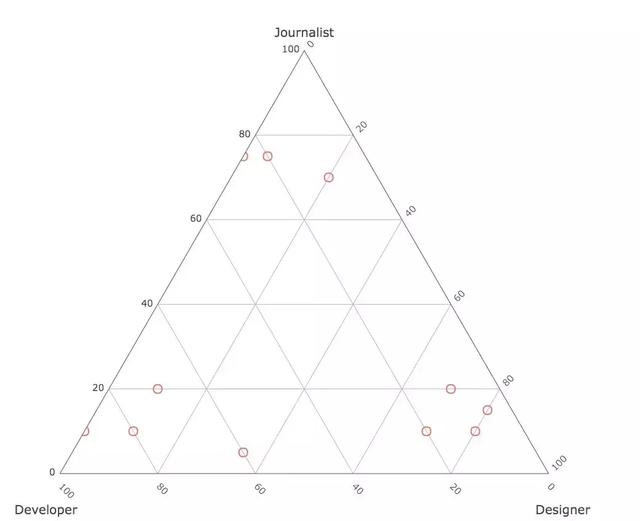
Basic Ternary Plot with Markers
篇幅有点长,这里就不 po 代码了。
Bokeh
这里展示一下常用的图表和比较抢眼的图表,详细的文档可查看(https://bokeh.pydata.org/en/latest/docs/user_guide/categorical.html)
条形图
这配色看着还挺舒服的,比 pyecharts 条形图的配色好看一点。
这篇关于推荐七款常用的Python数据可视化模块,数据可视化的福利的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





