本文主要是介绍58同城python委培生需要收费吗_初次小爬虫:58同城招聘信息爬取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1,通过url获取html
url="http://bj.58.com/job/pn"+pagenumber+'/?key=python&final=1&jump=1&PGTID=0d000000-0000-046d-babb-93654e2239c8&ClickID=2'
r=requests.get(url,headers=headers,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
2,headers的改变
因为爬到第二面被挡住了,就加了改了个headers
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
3,正则表达式的匹配
根据这段信息得出re表达式
res = re.compile(r'
- (.*?)
- .*?

4,excel的写入
wbk=xlwt.Workbook()
sheet=wbk.add_sheet('sheet 1')
sheet.write(sum, 0,j[0])
sheet.write(sum, 1,j[1])
sheet.write(sum, 2,j[2])
sheet.write(sum, 3, j[3])
5,二级网页的爬取
因为薪资在另外一个网页所以加了一个爬取函数,结合了一点bs4库
r=requests.get(url)
r.raise_for_status()
html=r.text
soup=BeautifulSoup(html,"html.parser")
temphtml = soup.find_all('div', class_="pos_base_info")
res = (r'(.*?)
tempre=re.findall(res, str(temphtml))
6,效果图
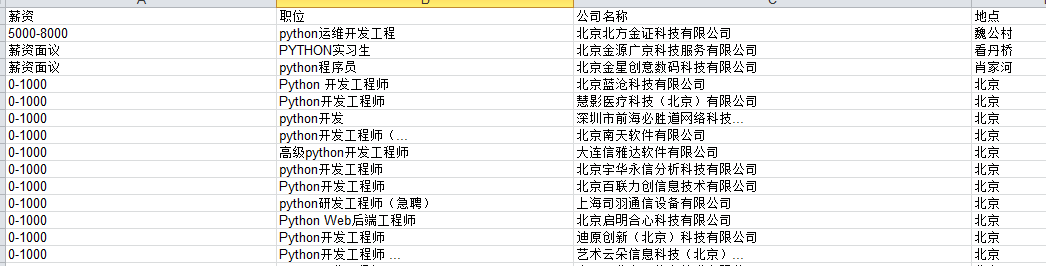
7,总结
感受:从学python到写出这个小爬虫,也花了一个月了,认识到了python的魅力,少了对过程的描述,只需要注重逻辑即可;
收获:爬虫让我对网页有了个大致的认识,对网页之间信息的传递多了一分理解
8,源码
因为未知原因已丢失
这篇关于58同城python委培生需要收费吗_初次小爬虫:58同城招聘信息爬取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








