本文主要是介绍MR实战:统计总分与平均分,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、实战概述
- 二、提出任务
- 三、完成任务
- (一)准备数据
- 1、在虚拟机上创建文本文件
- 2、上传文件到HDFS指定目录
- (二)实现步骤
- 1、创建Maven项目
- 2、添加相关依赖
- 3、创建日志属性文件
- 4、创建成绩映射器类
- 5、创建成绩驱动器类
- 6、启动应用,查看结果
- 7、创建成绩归并器类
- 8、修改成绩驱动器类
- 9、启动应用,查看结果
一、实战概述
- 在本次实战中,我们将利用Apache Hadoop的MapReduce框架来计算一个包含五名学生五门科目成绩的数据集的总分和平均分。我们将通过以下步骤实现这一目标:首先,在虚拟机上创建并准备数据,将成绩表以文本文件形式存储并在HDFS上设定输入目录;然后,使用IntelliJ IDEA创建Maven项目,并添加必要的Hadoop和JUnit依赖;接着,我们将实现ScoreMapper和ScoreReducer类,分别负责处理输入数据和计算总分与平均分;在ScoreDriver类中,我们将配置作业并运行MapReduce任务。最后,我们将通过HDFS Shell命令查看结果文件内容。此实战旨在深入理解并掌握MapReduce在处理和分析学生成绩数据中的应用,展现其强大的分布式计算能力。
二、提出任务
- 成绩表,包含六个字段(姓名、语文、数学、英语、物理、化学),有五条记录
| 姓名 | 语文 | 数学 | 英语 | 物理 | 化学 |
|---|---|---|---|---|---|
| 李小双 | 89 | 78 | 94 | 96 | 87 |
| 王丽霞 | 94 | 80 | 86 | 78 | 80 |
| 吴雨涵 | 90 | 67 | 95 | 92 | 60 |
| 张晓红 | 87 | 76 | 90 | 79 | 59 |
| 陈燕文 | 97 | 95 | 92 | 88 | 86 |
- 利用MR框架,计算每个同学的总分与平均分

三、完成任务
(一)准备数据
1、在虚拟机上创建文本文件
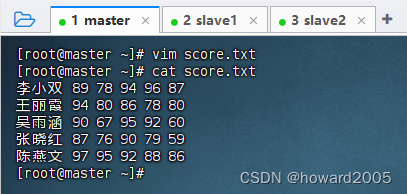
- 在master虚拟机上创建
score.txt文件
2、上传文件到HDFS指定目录
-
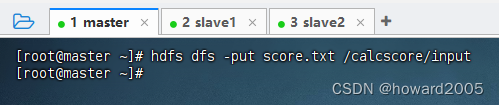
创建
/calcscore/input目录,执行命令:hdfs dfs -mkdir -p /calcscore/input

-
将文本文件
score.txt上传到HDFS的/calcscore/input目录
(二)实现步骤
- 说明:集成开发环境IntelliJ IDEA版本 -
2022.3
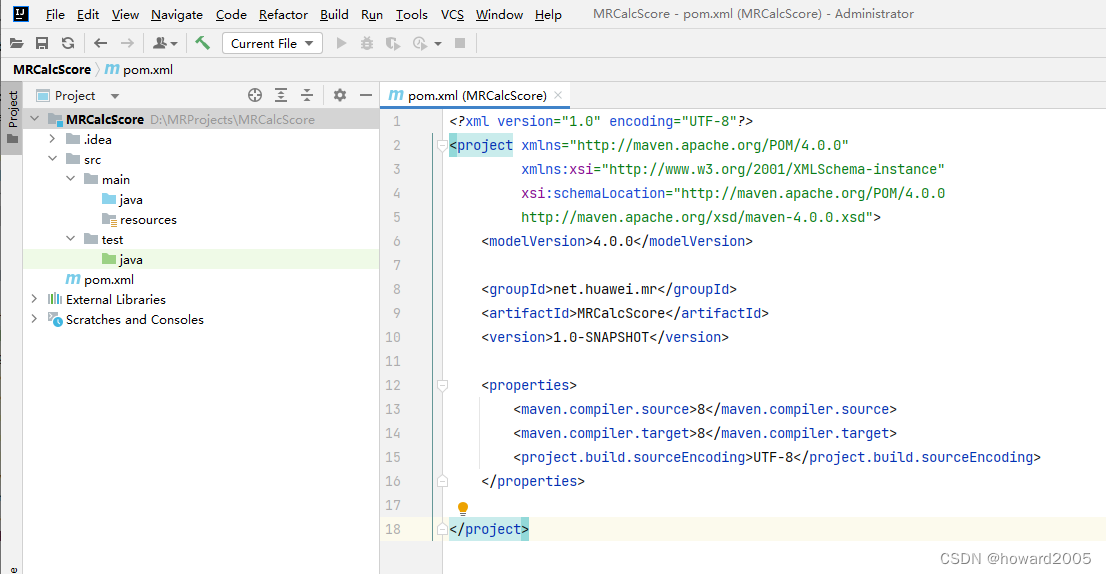
1、创建Maven项目
- Maven项目 -
MRCalcScore,设置了JDK版本 -1.8,组标识 -net.huawei.mr

- 单击【Create】按钮,得到初始化项目
2、添加相关依赖
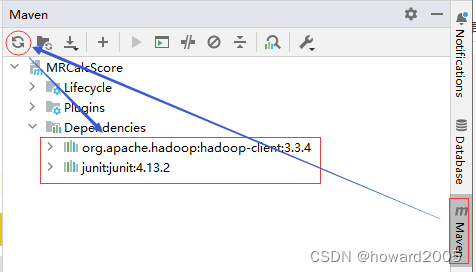
- 在
pom.xml文件里添加hadoop和junit依赖

<dependencies> <!--hadoop客户端--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.4</version> </dependency> <!--单元测试框架--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.13.2</version> </dependency>
</dependencies>
- 刷新项目依赖
3、创建日志属性文件
- 在
resources目录里创建log4j.properties文件

log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/calcscore.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
4、创建成绩映射器类
- 创建
net.huawei.mr包,在包里创建ScoreMapper类
package net.huawei.mr;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** 功能:成绩映射器* 作者:华卫* 日期:2023年12月29日*/
public class ScoreMapper extends Mapper<LongWritable, Text, Text, IntWritable> {@Overrideprotected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {// 获取行数据String line = value.toString();// 按空格拆分,得到字段数组String[] fields = line.split(" ");// 获取姓名String name = fields[0];// 遍历各科成绩for (int i = 1; i < fields.length; i++) {// 获取成绩int score = Integer.parseInt(fields[i]);// 写入<姓名,成绩>键值对context.write(new Text(name), new IntWritable(score)); }}
}
5、创建成绩驱动器类
- 在
net.huawei.mr包里创建ScoreDriver类
package net.huawei.mr;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.net.URI;/*** 功能:成绩驱动器类* 作者:华卫* 日期:2023年12月29日*/
public class ScoreDriver {public static void main(String[] args) throws Exception {// 创建配置对象Configuration conf = new Configuration();// 设置客户端使用数据节点主机名属性conf.set("dfs.client.use.datanode.hostname", "true");// 获取作业实例Job job = Job.getInstance(conf);// 设置作业启动类job.setJarByClass(ScoreDriver.class);// 设置Mapper类job.setMapperClass(ScoreMapper.class);// 设置map任务输出键类型job.setMapOutputKeyClass(Text.class);// 设置map任务输出值类型job.setMapOutputValueClass(IntWritable.class); // 定义uri字符串String uri = "hdfs://master:9000";// 创建输入目录Path inputPath = new Path(uri + "/calcscore/input");// 创建输出目录Path outputPath = new Path(uri + "/calcscore/output");// 获取文件系统FileSystem fs = FileSystem.get(new URI(uri), conf);// 删除输出目录(第二个参数设置是否递归)fs.delete(outputPath, true);// 给作业添加输入目录(允许多个)FileInputFormat.addInputPath(job, inputPath);// 给作业设置输出目录(只能一个)FileOutputFormat.setOutputPath(job, outputPath);// 等待作业完成job.waitForCompletion(true);// 输出统计结果System.out.println("======统计结果======");FileStatus[] fileStatuses = fs.listStatus(outputPath);for (int i = 1; i < fileStatuses.length; i++) {// 输出结果文件路径System.out.println(fileStatuses[i].getPath());// 获取文件系统数据字节输入流FSDataInputStream in = fs.open(fileStatuses[i].getPath());// 将结果文件显示在控制台IOUtils.copyBytes(in, System.out, 4096, false);}}
}
6、启动应用,查看结果
- 运行
ScoreDriver类,会看到两列,一列姓名,一列成绩

7、创建成绩归并器类
- 在
net.huawei.mr包里创建ScoreReducer类

package net.huawei.mr;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
import java.text.DecimalFormat;/*** 功能:成绩归并器类* 作者:华卫* 日期:2023年12月29日*/
public class ScoreReducer extends Reducer<Text, IntWritable, Text, NullWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {// 声明科目数、总分和平均分变量int count = 0;int sum = 0;double avg = 0;// 遍历迭代器计算总分for (IntWritable value : values) {count++; // 科目数累加sum = sum + value.get(); // 累加每科成绩}// 计算平均分avg = sum * 1.0 / count;// 创建小数点格式对象(保留一位小数)DecimalFormat df = new DecimalFormat("#.#");// 拼接每个学生总分与平均分成绩信息String scoreInfo = "(" + key + "," + new IntWritable(sum) + "," + df.format(avg) + ")";// 写入键值对<scoreInfo,null>context.write(new Text(scoreInfo), NullWritable.get());}
}
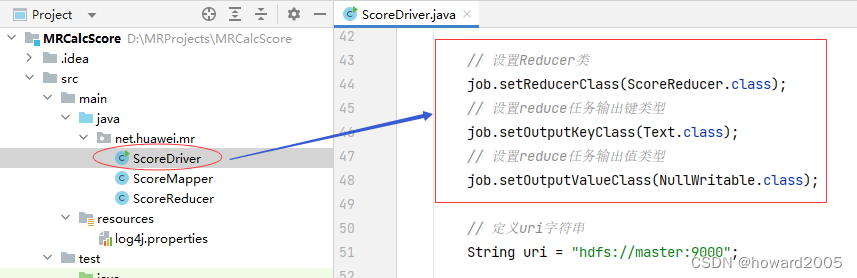
8、修改成绩驱动器类
- 设置Reducer类及其输出键值类型
9、启动应用,查看结果
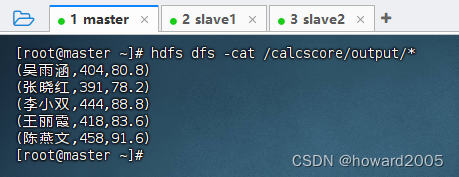
-
运行
ScoreDriver类,看到指定格式的成绩统计
-
利用HDFS Shell命令查看结果文件内容
这篇关于MR实战:统计总分与平均分的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




