本文主要是介绍Hive讲课笔记:内部表与外部表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、导言
- 二、内部表
- 1.1 什么是内部表
- 1.1.1 内部表的定义
- 1.1.2 内部表的关键特性
- 1.2 创建与操作内部表
- 1.2.1 创建并查看数据库
- 1.2.2 在park数据库里创建student表
- 1.2.3 在student表插入一条记录
- 1.2.4 通过HDFS WebUI查看数据库与表
- 三、外部表
- 2.1 什么是外部表
- 2.2 创建与操作外部表
- 2.2.1 在本地创建user.txt文件
- 2.2.2 将文件user.txt上传到HDFS的/data目录
- 2.2.3 创建外部表data管理/data目录的数据文件
- 2.2.4 查询外部表data的记录
- 2.2.5 在MySQL里查看hive元数据信息
- 四、内部表与外部表的区别
- 3.1 区别体现在删除表
- 3.2 通过实验进行验证
- 3.2.1 删除内部表student
- 3.2.2 删除外部表data
- 3.2.3 查看MySQL里hive元数据
- 五、总结与展望
一、导言
-
本次课程将深入讲解Hive的内部表和外部表。我们会从定义出发,逐步教授如何在park数据库中创建和操作student内部表,包括数据插入和通过HDFS WebUI查看。接着,我们将探讨外部表,从本地文件user.txt的创建与上传到HDFS,再到在Hive中管理/data目录的数据并进行查询,同时展示MySQL中hive元数据的查看方法。
-
重点环节,我们将揭示内部表和外部表在删除操作上的区别,并通过课堂实验进行验证。同学们将亲自体验删除内部表student和外部表data的过程,并观察MySQL中hive元数据的变化。
-
最后,我们将对本课程内容进行总结,并展望Hive表管理的未来应用,旨在帮助同学们全面掌握和有效运用Hive内部表和外部表。
二、内部表
1.1 什么是内部表
1.1.1 内部表的定义
- Hive内部表是Hive数据仓库中的一种表类型。当在Hive中创建一个内部表时,表的数据和元数据都由Hive进行管理。
1.1.2 内部表的关键特性
-
存储位置:Hive内部表的数据默认存储在Hadoop Distributed File System (HDFS) 中的一个指定目录下,这个目录由Hive自动管理。
-
元数据管理:Hive内部表的元数据(如表结构、分区信息等)存储在 Hive Metastore 中,这是一个集中式的服务,用于存储和管理所有Hive表的元数据。
-
数据生命周期:删除Hive内部表时,不仅会删除表的元数据,还会从HDFS中删除与该表相关联的实际数据文件。
-
独立性:由于Hive完全管理内部表的数据和元数据,因此这些表对Hive具有完全的依赖性。如果不再使用Hive,内部表的数据将无法直接通过其他方式访问。
-
表操作限制:对Hive内部表进行数据修改或移动等操作可能会受到限制,因为这些操作可能会影响Hive对数据的管理和追踪。
- 总的来说,Hive内部表是一种适合于数据仓库环境中长期存储和管理数据的表类型,它提供了方便的数据管理和查询功能,但同时也要求用户考虑其对数据持久性和访问方式的需求。
1.2 创建与操作内部表
1.2.1 创建并查看数据库
- 创建
park数据库,执行命令CREATE DATABASE park

- 在MySQL里查看数据库信息
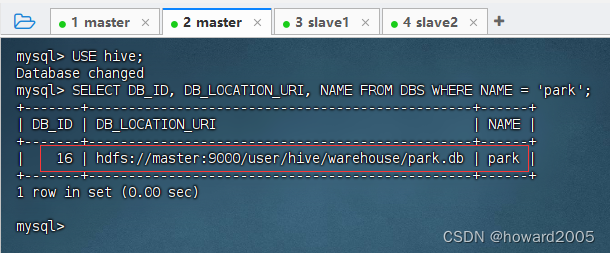
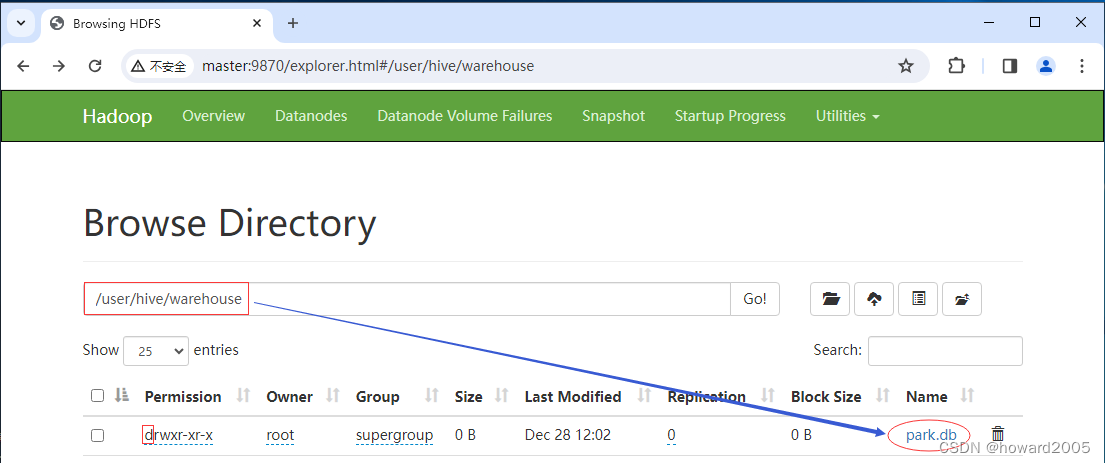
- 在HDFS上查看
park数据库对应的目录/user/hive/warehouse/park.db
1.2.2 在park数据库里创建student表
- 使用
CREATE TABLE命令创建内部表。 - 查看表信息。
1.2.3 在student表插入一条记录
- 使用
INSERT INTO命令插入数据。
1.2.4 通过HDFS WebUI查看数据库与表
- 查看HDFS中数据库与表的存储情况。
三、外部表
2.1 什么是外部表
- 通过
CREATE EXTERNAL TABLE...LOCATION...命令创建的表称为外部表。 - 对应HDFS某一个目录下的数据文件。
2.2 创建与操作外部表
2.2.1 在本地创建user.txt文件
- 准备外部表的数据文件。
2.2.2 将文件user.txt上传到HDFS的/data目录
- 通过HDFS Explorer查看上传的文件。
2.2.3 创建外部表data管理/data目录的数据文件
- 使用
CREATE EXTERNAL TABLE命令创建外部表。
2.2.4 查询外部表data的记录
- 使用
SELECT命令查询外部表的记录。
2.2.5 在MySQL里查看hive元数据信息
- 查询Hive元数据中外部表的信息。
四、内部表与外部表的区别
3.1 区别体现在删除表
- 内部表删除后,HDFS对应目录被删除。
- 外部表删除后,HDFS对应目录不被删除。
3.2 通过实验进行验证
3.2.1 删除内部表student
- 使用
DROP TABLE命令删除内部表。
3.2.2 删除外部表data
- 使用
DROP TABLE命令删除外部表。
3.2.3 查看MySQL里hive元数据
- 查询Hive元数据中表的状态。
五、总结与展望
- 总结内部表与外部表的特点与操作步骤。
- 展望在实际应用中的使用场景与注意事项。
这篇关于Hive讲课笔记:内部表与外部表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








