本文主要是介绍离线知识库服务(Langchain-Chatchat)本地搭建,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于模型的离线知识库的应用,这样的应用服务目前正在遍地开花,选择一个好的模型应用服务是能把大模型的能力充分利用的(Langchain-Chatchat)。
如果基础环境没有布置好可以参考我上篇文章《Ubuntu 22.04 Tesla V100s显卡驱动,CUDA,cuDNN,MiniCONDA3 环境的安装》。
Langchain-Chatchat
基于 ChatGLM 等大语言模型与 Langchain 等应用框架实现,开源、可离线部署的检索增强生成(RAG)大模型知识库项目。
一种利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
简单来讲,它就是一个离线部署版的AI大模型知识库。
接下来,会根据清华大模型(ChatGLM3-6B),进行配置进行示例。
另外我想说的是现在是一个对大模型应用的高峰期,毕竟有数据并能训练的是少数,所以,很多都转移到对这个大模型的应用上来了,早期的 AutoGPT,然后,Langchain-Chatchat,Langflow 以及 微软的 Semantic Kernel 都是在增加对大模型的应用侧,业务侧 发力,使其能真正的落地。
所以,关注这些会更好玩。
Langchain 原理
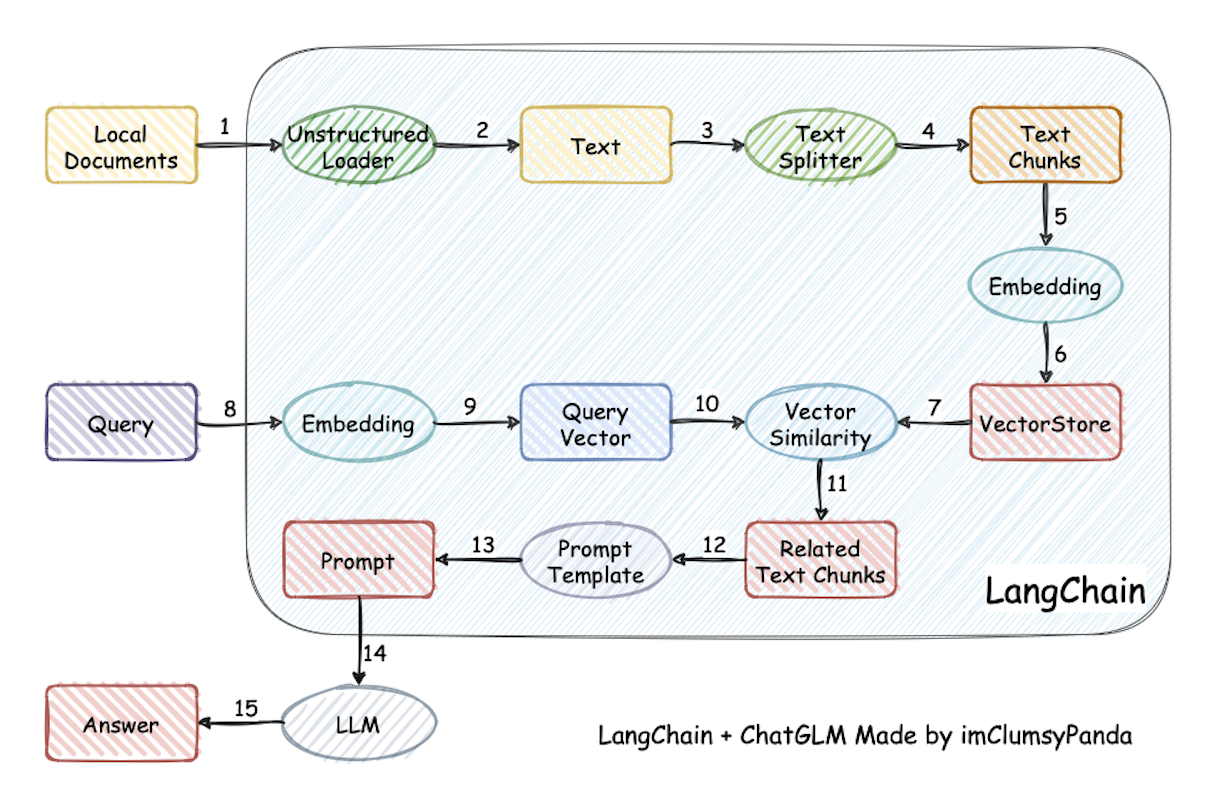
基本原理就如此图所示
官方解释:
过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。
我自己的理解
本地的知识库(HTML、MD、JSON、CSV、PDF、PNG、JPG、BMP、TXT、XML、DOCX、PPT、PPTX)等文件,会通过各种解析或者识别方式把内容文本信息,提取出来(对应非结构化加载器),然后,对文本信息进行标准化分割(就是分段,就一定规则可配置),然后,把处理后的文本向量化存入到向量数据库里。
当你进行问答的时候,会把你的问题也向量化,通过向量相似度匹配的方式,把向量数据库里跟问题相关的知识段内容查询出来,当做大模型问答 Prompt(提词器)的【知识】进行提供。
这样就会形成一个 知识 + 问题 为问题的结构,扔给大模型,大模型就会根据自身的知识内容以及你提供的【知识】一起组合成一个答案给你(当然,这个答案是随机的)。
Langchain-Chatchat 部署
https://github.com/chatchat-space/Langchain-Chatchat
先下载 Langchain-Chatchat 服务
直接就下载完毕,剩下的就是配置信息了
然后,继续搞个 python 环境管理
conda create --name langchat python=3.10
conda activate langchat
然后,进入到主项目中,开始配置一些环境
cd Langchain-Chatchat
第一步是要安装python 的依赖包
pip install -r requirements.txt -i https://mirror.sjtu.edu.cn/pypi/web/simple
pip install -r requirements_api.txt -i https://mirror.sjtu.edu.cn/pypi/web/simple
pip install -r requirements_webui.txt -i https://mirror.sjtu.edu.cn/pypi/web/simple
下载模型
如果没有下载 ChatGLM3-6B ,那么,还得下载这个模型,另外还得下载一个模型
当然,尽量以官方地址的 README.md 文档来,我这个只是根据当下的情况的一个实际选择。
git lfs install
git clone https://huggingface.co/THUDM/chatglm3-6b
git clone https://huggingface.co/BAAI/bge-large-zh
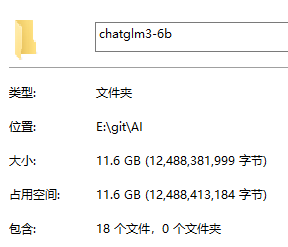
看一下大小 11.6GB ,还挺大的
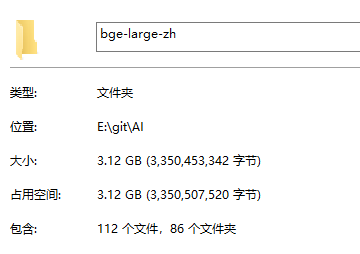
而 bge-large-zh 就只有 3.12GB ,小很多了
Langchain-Chatchat 配置
初始化知识库和配置文件
python copy_config_example.py
设置完之后,要进入到,配置文件夹 configs里面配置相关的配置
我的配置如下:
model_config.py (重点)
大部分需要配置的都在这个里面
下面这个默认模型 我只保留了一个
LLM_MODELS = ["chatglm3-6b"] # "zhipu-api", "openai-api" "Qwen-1_8B-Chat",
在 MODEL_PATH 这里,需要配置模型的文件夹位置
从
"bge-large-zh": "BAAI/bge-large-zh",
改为
"bge-large-zh": "/data/ai/chatglm3/bge-large-zh",
即可
而 llm_model 我这边修改
"chatglm3-6b": "THUDM/chatglm3-6b",
为
"chatglm3-6b": "/data/ai/chatglm3/chatglm3-6b",
并且也可以看到,里面实际上有很多的模型
模型信息展示(修改后)
MODEL_PATH = {
"embed_model": {"ernie-tiny": "nghuyong/ernie-3.0-nano-zh","ernie-base": "nghuyong/ernie-3.0-base-zh","text2vec-base": "shibing624/text2vec-base-chinese","text2vec": "GanymedeNil/text2vec-large-chinese","text2vec-paraphrase": "shibing624/text2vec-base-chinese-paraphrase","text2vec-sentence": "shibing624/text2vec-base-chinese-sentence","text2vec-multilingual": "shibing624/text2vec-base-multilingual","text2vec-bge-large-chinese": "shibing624/text2vec-bge-large-chinese","m3e-small": "moka-ai/m3e-small","m3e-base": "moka-ai/m3e-base","m3e-large": "moka-ai/m3e-large","bge-small-zh": "BAAI/bge-small-zh","bge-base-zh": "BAAI/bge-base-zh","bge-large-zh": "/data/ai/chatglm3/bge-large-zh","bge-large-zh-noinstruct": "BAAI/bge-large-zh-noinstruct","bge-base-zh-v1.5": "BAAI/bge-base-zh-v1.5","bge-large-zh-v1.5": "BAAI/bge-large-zh-v1.5","piccolo-base-zh": "sensenova/piccolo-base-zh","piccolo-large-zh": "sensenova/piccolo-large-zh","nlp_gte_sentence-embedding_chinese-large": "damo/nlp_gte_sentence-embedding_chinese-large","text-embedding-ada-002": "your OPENAI_API_KEY",
},"llm_model": {
"chatglm2-6b": "THUDM/chatglm2-6b",
"chatglm2-6b-32k": "THUDM/chatglm2-6b-32k","chatglm3-6b": "/data/ai/chatglm3/chatglm3-6b",
"chatglm3-6b-32k": "THUDM/chatglm3-6b-32k",
"chatglm3-6b-base": "THUDM/chatglm3-6b-base","Qwen-1_8B": "Qwen/Qwen-1_8B",
"Qwen-1_8B-Chat": "Qwen/Qwen-1_8B-Chat",
"Qwen-1_8B-Chat-Int8": "Qwen/Qwen-1_8B-Chat-Int8",
"Qwen-1_8B-Chat-Int4": "Qwen/Qwen-1_8B-Chat-Int4","Qwen-7B": "Qwen/Qwen-7B",
"Qwen-7B-Chat": "Qwen/Qwen-7B-Chat","Qwen-14B": "Qwen/Qwen-14B",
"Qwen-14B-Chat": "Qwen/Qwen-14B-Chat",
"Qwen-14B-Chat-Int8": "Qwen/Qwen-14B-Chat-Int8",
"Qwen-14B-Chat-Int4": "Qwen/Qwen-14B-Chat-Int4","Qwen-72B": "Qwen/Qwen-72B",
"Qwen-72B-Chat": "Qwen/Qwen-72B-Chat",
"Qwen-72B-Chat-Int8": "Qwen/Qwen-72B-Chat-Int8",
"Qwen-72B-Chat-Int4": "Qwen/Qwen-72B-Chat-Int4","baichuan2-13b": "baichuan-inc/Baichuan2-13B-Chat",
"baichuan2-7b": "baichuan-inc/Baichuan2-7B-Chat","baichuan-7b": "baichuan-inc/Baichuan-7B",
"baichuan-13b": "baichuan-inc/Baichuan-13B",
"baichuan-13b-chat": "baichuan-inc/Baichuan-13B-Chat","aquila-7b": "BAAI/Aquila-7B",
"aquilachat-7b": "BAAI/AquilaChat-7B","internlm-7b": "internlm/internlm-7b",
"internlm-chat-7b": "internlm/internlm-chat-7b","falcon-7b": "tiiuae/falcon-7b",
"falcon-40b": "tiiuae/falcon-40b",
"falcon-rw-7b": "tiiuae/falcon-rw-7b","gpt2": "gpt2",
"gpt2-xl": "gpt2-xl","gpt-j-6b": "EleutherAI/gpt-j-6b",
"gpt4all-j": "nomic-ai/gpt4all-j",
"gpt-neox-20b": "EleutherAI/gpt-neox-20b",
"pythia-12b": "EleutherAI/pythia-12b",
"oasst-sft-4-pythia-12b-epoch-3.5": "OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5",
"dolly-v2-12b": "databricks/dolly-v2-12b",
"stablelm-tuned-alpha-7b": "stabilityai/stablelm-tuned-alpha-7b","Llama-2-13b-hf": "meta-llama/Llama-2-13b-hf",
"Llama-2-70b-hf": "meta-llama/Llama-2-70b-hf",
"open_llama_13b": "openlm-research/open_llama_13b",
"vicuna-13b-v1.3": "lmsys/vicuna-13b-v1.3",
"koala": "young-geng/koala","mpt-7b": "mosaicml/mpt-7b",
"mpt-7b-storywriter": "mosaicml/mpt-7b-storywriter",
"mpt-30b": "mosaicml/mpt-30b",
"opt-66b": "facebook/opt-66b",
"opt-iml-max-30b": "facebook/opt-iml-max-30b","agentlm-7b": "THUDM/agentlm-7b",
"agentlm-13b": "THUDM/agentlm-13b",
"agentlm-70b": "THUDM/agentlm-70b","Yi-34B-Chat": "01-ai/Yi-34B-Chat",
},支持AGENT模型有:
SUPPORT_AGENT_MODEL = ["azure-api","openai-api","qwen-api","Qwen","chatglm3","xinghuo-api",
]
什么是Agent(人工智能体)
AI Agent(人工智能体)是一种能够感知环境、进行决策和执行动作的智能实体。不同于传统的人工智能,AI Agent 具备通过独立思考、调用工具去逐步完成给定目标的能力。
这个也是AutoGPT开源项目之后的一个新概念,通俗的来讲,就是这个大模型里集成了很多的工具,你可以让大模型自动调用你的工具来实现相关的业务,而这样的工具可能非常的多。就像RPA工具一样,而发号施令的人已经从人,换成了大模型本身而已。
server_config.py
这个里面可以更改服务的端口等配置信息,我暂时不需要更改,默认。
最后,初始化向量数据库,因为它需要 bge-large-zh 模型
python init_database.py --recreate-vs

初始化向量数据库的时候会报一些错误,以下脚本可以解决一部分问题
pip install jq -i https://mirror.sjtu.edu.cn/pypi/web/simple
重新执行之后

向量数据库已经初始化成功
一键启动项目
python startup.py -a
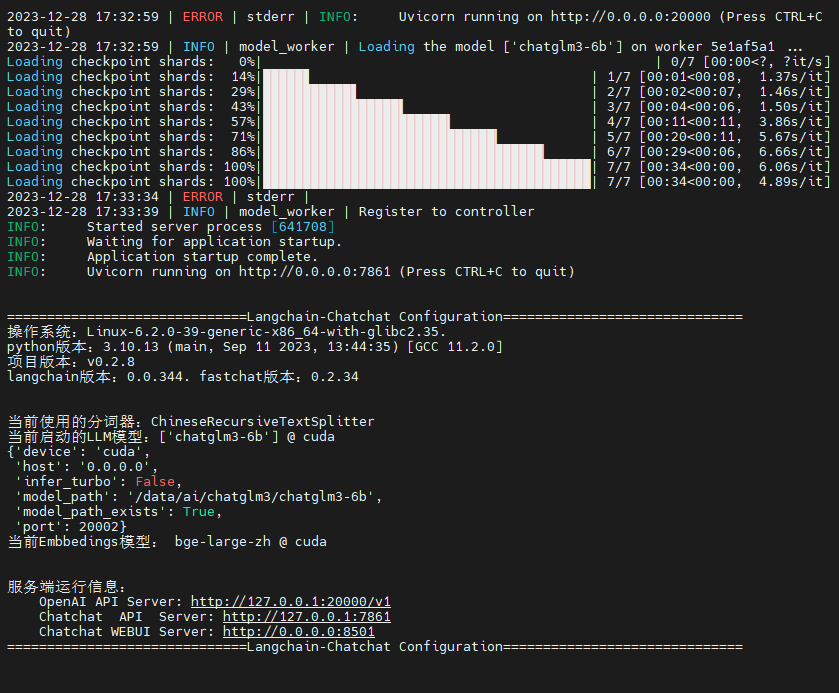
可以看已经运行起来了。
打开指定的地址 http://0.0.0.0:8501 //需把 0.0.0.0 替换成服务器自己的地址,然后游览器打开即可
简单的问答

可以看到,问答还是很轻松的,确实是使用的同一个模型 chatglm3-6b
而在对话模式中,还有更多的选择
搜索引擎问答

这个其实是要有相关搜索引擎的key 的,并且还可能需要外网的访问,具体的要在<kb_config.py>配置文件中配置。
本来想试试bing的,结果bing也是需要key的
# 默认搜索引擎。可选:bing, duckduckgo, metaphor
DEFAULT_SEARCH_ENGINE = "duckduckgo"# Bing 搜索必备变量
# 使用 Bing 搜索需要使用 Bing Subscription Key,需要在azure port中申请试用bing search
# 具体申请方式请见
# https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/create-bing-search-service-resource
# 使用python创建bing api 搜索实例详见:
# https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/quickstarts/rest/python
BING_SEARCH_URL = "https://api.bing.microsoft.com/v7.0/search"
# 注意不是bing Webmaster Tools的api key,# 此外,如果是在服务器上,报Failed to establish a new connection: [Errno 110] Connection timed out
# 是因为服务器加了防火墙,需要联系管理员加白名单,如果公司的服务器的话,就别想了GG
BING_SUBSCRIPTION_KEY = ""# metaphor搜索需要KEY
METAPHOR_API_KEY = ""
知识库问答 (重点)

可以在左侧菜单选择知识库问答,在右侧就可以看到知识库的相关信息
当然,也可以新建知识库

当然,默认知识库里已经导入了很多的文件了


可以根据这些已有的知识进行问答。

可以很清晰的看到,它确实根据已有的离线知识库进行了回答。
总结
总得来说今年是AIGC,AI大模型的元年,可以很清晰的看到,微软,OpenAi,百度,等等都在对AI大模型的应用在大力推动,我想多接触和了解这些是很有必要的。
现在这些模型的应用已经产生了业务级的影响,也是我所需要的。
参考资料地址
《清华ChatGLM3 ChatGLM3-6B 大模型》
https://github.com/THUDM/ChatGLM3
《Langchain-Chatchat(原Langchain-ChatGLM)》
https://github.com/chatchat-space/Langchain-Chatchat
阅
一键三连呦!,感谢大佬的支持,您的支持就是我的动力!
这篇关于离线知识库服务(Langchain-Chatchat)本地搭建的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







