本文主要是介绍百度沧海文件存储CFS推出新一代Namespace架构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着移动互联网、物联网、AI 计算等技术和市场的迅速发展,数据规模指数级膨胀,对于分布式文件系统作为大规模数据场景的存储底座提出了更高的要求。已有分布式文件系统解决方案存在着短板,只能适应有限的场景:
>> 新型分布式文件系统无法承接传统领域内的所有 WorkLoad:通过只支持部分 POSIX 接口来简化系统设计,无法完全兼容 POSIX 协议。
>> 传统分布式文件系统无法支持海量小文件场景:为了保证低延迟,元数据的可扩展性较差、随文件规模性能和稳定性下降严重,无法支持如 AI 训练、自动驾驶等文件规模达到十亿甚至百亿规模的 AI 场景。
因此,设计出一款不仅能完美兼容传统应用,又能适应最新 AI 场景需求的分布式文件存储,显得意义重大。这样的分布式文件系统需要满足:
-
完全兼容 POSIX 协议。
-
在确保元数据低延迟、稳定的情况下,可线性扩展,支持百亿文件规模,具备超大规模文件数量元数据操作能力的同时具备超高的性能稳定性。
要想达到以上目标,百度沧海·文件存储 CFS 给出的技术解答是设计新一代的 Namespace 子系统,在实现创建文件每秒百万级 QPS 的同时,保证各项性能指标表现稳定。
这使得文件存储 CFS 不仅可以支持传统应用,作为传统业务上云的存储方案;也可以应用于最新的 AI 场景,满足海量文件规模处理的应用需求。
Namespace 的技术现状
Namespace 子系统的功能主要是维护文件系统的文件属性、目录树结构等元数据信息,同时支持兼容 POSIX 的目录树及文件操作,如:文件/目录创建、查找(Lookup/Getattr)删除及重命名(Rename)等。
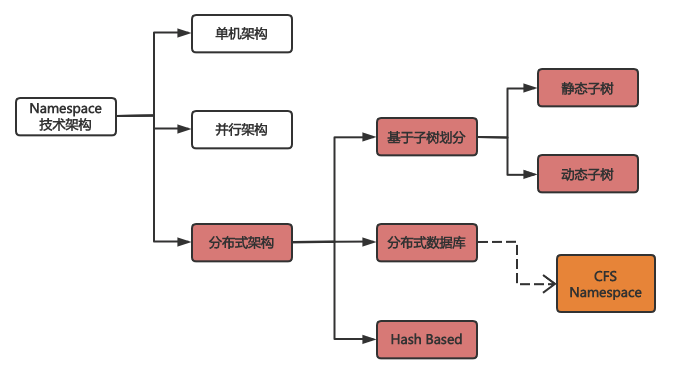
当前,业界分布式文件系统领域衍生出各种类型的 Namespace 技术架构,可以归类为如下几种:
-
单机架构:配合单机全内存,可做到低延迟,无法横向扩展,最大规模仅支持 5 亿文件数,代表产品为 HDFS。
-
并行架构:适用于 HPC 等并行文件系统应用场景,元数据静态切分到多机部署,单机利用一主一备保证可用性,缺乏弹性扩展能力。
-
分布式架构:将元数据按照某种方式切分和扩展到一组机器上,按照集群的方式管理。

相对于单机架构不可扩展及并行架构对扩展性的弱支持,分布式 Namespace 架构在扩展性上做的更加彻底。
那么直接引入一套现成的分布式 Namespace 架构是否可以直接解决上文提到的挑战呢?
答案是否定的,因为现有的分布式 Namespace 架构都存在各自的局限性和不足。
-
基于 Hash Based 架构尽管具有很好的扩展性及负载均衡效果,但是其牺牲了 POSIX 兼容语义的支持。该架构方案将文件全路径 Hash 来组织打散到分布式 Meta 集群,对于 Lookup 路径查找非常友好同时容易实现,但是缺点是牺牲了元数据的局部性,尤其是 rename 的实现复杂度高且性能很差,这类架构主要停留在学术研究,没有在工业界大规模应用,典型的系统如 Dr.Hadoop,GiraffaFS;
-
基于子树划分架构保证了元数据的局部性,可兼容 POSIX 语义,但是扩展性不够好 。该架构方案通过将层级目录树拆分成多个子树并将每颗子树按照相应的负载策略部署到不同的 Meta 节点中,单节点上具有很好的元数据局部性,但是缺点就是容易产生热点,负载均衡难以实现,扩展性不够好,典型的实现如 CephFS、IndexFS;
相对于前两种架构都具有明显的局限性且难以弥补,近几年脱颖而出的基于分布式数据库或分布式 KV 的 Namespace 架构兼顾了扩展性及 POSIX 语义兼容支持。
该方案通常采用分层架构:上层维护了一层元数据处理层,该层将目录树 POSIX 操作转化为数据库事务请求。下层是分布式数据库或分布式 KV 层,负责元数据的存储管理,同时对上层的数据库事务请求进行语义处理。
通过这样的分层架构就做到了对 POSIX 语义的完整兼容。同时,利用分布式数据库或分布式 KV 本身的可扩展性,做到了 NameSpace 架构的可扩展。
另外,为了进一步提升 POSIX 语义的处理速度,通常会维护一层 Hint Cache 来加速元数据的处理。
虽然该架构方案可以在存储层面做到弹性可扩展且简化了元数据的处理,但由于现有架构对锁及数据库事务存在强依赖,Namespace 在写延迟及写性能的扩展性层面仍然存在不足,难以支持每秒创建百万以上的文件的需求。
百度智能云 CFS 在此架构基础上改进和扩展出新一代的 Namespace 架构。
CFS 的 Namespace 架构
百度沧海的文件存储 CFS 作为百度智能云提供的分布式文件存储服务,通过标准的文件访问协议(NFS/SMB),为云上的虚机、容器等计算资源提供无限扩展、高可靠、地域级别共享的文件存储能力。
为了兼顾传统及 AI 场景的用户需求,弹性可扩展且兼容 POSIX 一直被作为 CFS 架构尤其是 Namespace 子系统的重要设计目标。
基于分布式 KV 架构,CFS 采用自研的分布式索引系统来支撑 Namespace 子系统,并基于该索引系统实现了分层架构,即 POSIX 语义层+分布式 KV 层。该索引系统经过 CFS 产品多年的打磨,目前可以非常好地解决 Namespace 层级结构扩展性与低延迟的需求。
相比于其他基于分布式数据库或分布式 KV 的分布式文件系统(比如 HopsFS),CFS 不直接依赖底层分布式数据库或分布式 KV 层的锁及事务机制来维持 POSIX 语义,而是通过以下创造性的设计配合来解决:
-
适配层级结构数据模型,定制化 Schema 来降低 KV 层数据之间的关联性。
-
在 POSIX 语义层设计一套针对 Namespace 层级结构、相对数据库锁及事务机制更轻量的一致性协议,保障所有 Namespace 层的读写操作不会破坏 POSIX 语义。
基于以上设计,CFS 在 Namespace 层的读写操作都具备非常低的延迟和好的线性扩展能力,具体性能参考下文测试结果。

除此之外,为了进一步优化延迟,CFS 团队在该架构的各个层面做了深入优化:
-
单机层面进一步优化延迟:单机 KV 引擎适配了 AEP 等高速硬件,确保 Namespace 关键路径低延迟。
-
一致性协议层面进一步优化扩展性及延迟:POSIX 语义层一致性协议采用无状态实现,不同节点之间无需同步、无需单独部署,而是作为 LIB 编译到 Client 或者接入模块,简化了架构的维护及 Namespace 读写路径,同时进一步保障了架构的可扩展性。
Namespace 性能测试
为了验证 CFS 产品 Namespace 架构的扩展性及性能稳定性,我们分别从扩展索引系统 KV 节点和 Meta Client 节点两个维度来测试,在验证扩展性同时给出相应单次请求的延迟数据及稳定性。
说明:以下测试 workload 均采用 Mdtest 作为元数据测试工具,其中 Meta Client 作为文件系统协议接入层对接标准的 NFS 协议,压测中的线程工作在相同 FS 不同路径上。
KV 节点扩展
以下数据对比了 10 个 KV 节点和 20 个 KV 节点在并发 mkdir 的性能数据表现(图中 BE 对应分布式 KV 层一个后端 KV 节点):
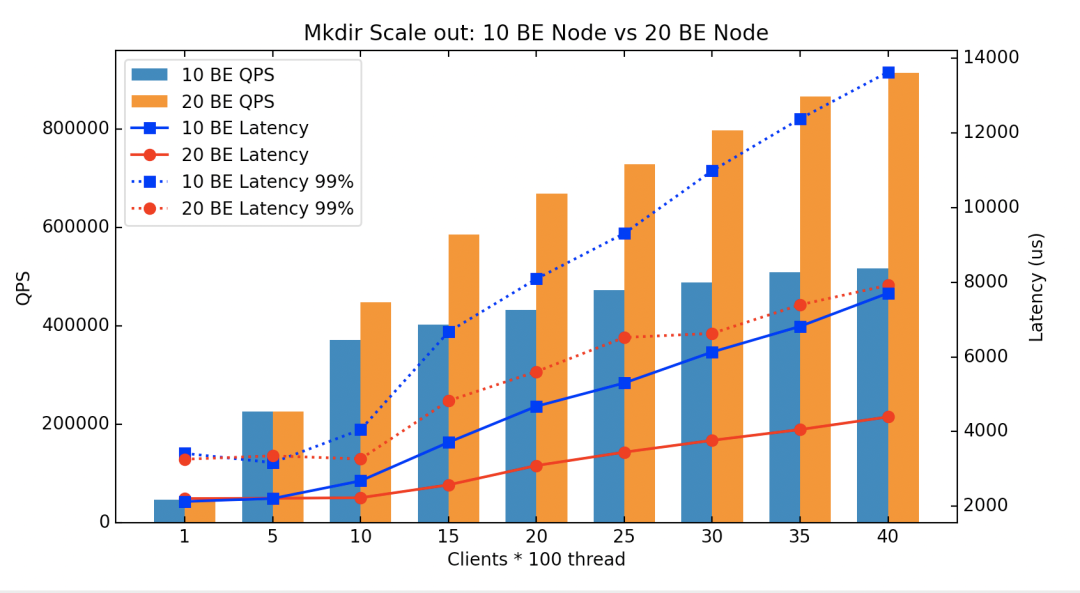
通过以上数据可以看出:
-
20 个 KV 节点相对于 10 个 KV 节点在写吞吐上接近于两倍的提升;
-
当系统负载正常情况下一次 Namespace 写延迟只需要 2ms 左右;
-
当系统负载过高且瓶颈来到 KV 层,延迟长尾表现稳定;
综上,可以看出 CFS 的架构在 KV 层可以支持线性扩展。
Meta Client 扩展
以下是基于集群的 KV 层固定为 24 个 KV 节点的对应数据,一方面通过扩展 Meta Client 数来验证架构在语义层的扩展性,另一方面验证架构在读和写是否具备突破百万 QPS 的能力。




通过以上数据可以看出:
-
Namespace 写和读吞吐可以在 POSIX 语义层做到线性扩展,其中写操作(文件\目录创建)可以达到 100 万 QPS,即每秒可支持创建百万文件;路径查找(Lookup)可以达到 400 万 QPS,目录/文件属性获取(Getattr)可以达到 600 万 QPS。
-
延迟方面写延迟为 2ms,读延迟只需要百 us 级。
CFS 可以在元数据读写操作上都可以做到支持线性扩展的同时保证低延迟以及性能稳定性,并且在此基础上完成每秒创建百万文件的挑战。
这篇关于百度沧海文件存储CFS推出新一代Namespace架构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






